GlusterFS知识总结
glusterfs源码框架分析: https://www.jianshu.com/p/699e9c17deff
经过大量的搜集网上的素材,总结下文(写的比较粗糙)
详细讲解
函数API
GlusterFS Translator API
STACK_UNWIND_STRICT(create, frame, op_ret, op_errno, fd, inode, buf,
preparent, postparent, xdata);
参数介绍
op: 操作类型
frame: 当前请求的stack frame
params: 任何其他的入口点相关的参数(比如针对此fop的inodes, file descriptors, offsets, data buffers等)
op_ret: fop的到目前的状态(读的字节数或者写的字节数,常常0表示fop成功,-1表示失败)
op_errno: 标准错误码(在fop失败的情况下)
fd: 打开的文件描述符
inode:
buf
https://blog.csdn.net/liuaigui/article/details/7786215/
Per Request Context请求上下文私有变量: local指针
local指针:每个translator-stack frame都有一个local指针,用来储存该translator特定的上下文,这是在调用和回调函数间存储上下文的主要机制。
// dispatch函数
param_t* p = malloc(sizeof(param_t));
p->data = ...;
frame->local = p; // 给local赋值
-----------------------
// cbk函数
param_t* p = frame->local; // 取出local
frame->local = NULL; // 将local设为NULL
free(p->data); // 记得释放param_t
free(p);
STACK_UNWIND(...,...)
注意:在cbk函数中,使用完frame->local后,记得将其设为NULL。
要记住:每个帧frame的非NULL的local域当要毁栈时要用GF_FREE来释放,不用做其他的清理工作。如果local结构里包含指针或对其他对象的引用,需要我们自己进行这些资源的清理。在毁栈前,内存或者其他资源先清理是个好的习惯,为此就不能依靠GF_FREE来自动清理。最安全的方式是定义我们自己的xlator相关的destructor,在调用STACK_UNWIND前手动调用。
形参类型:
inode_t *inode
xlator_t *xlator
value是uint64_t类型(64位整形)
inode_ctx_put (inode, xlator, value) // /* NB: put, not set */把value放到inode里?
inode_ctx_get (inode, xlator, &value) // 从inode中获取值,保存到value
inode_ctx_del (inode, xlator, &value) // _del函数实际是破坏性get,先返回然后删除值
fd_ctx_set (fd, xlator, value)
fd_ctx_get (fd, xlator, &value)
fd_ctx_del (fd, xlator, &value)
dict_t 字典
一个通用的排序字典或hash-map的数据结构,
作用:
1. 用于调用、回调函数
2. 传递不同的模块选项,包括xlator初始化选项。事实上,目前xlator的init函数,主要用于解析字典中的选项
选项 options[]
向xlator中添加一个选项,需要在xlator的options数组中添加实体,解析后的选项和其他信息可以存放在xlator_t结构体的private内
VFS
Vritual Filesystem 是给用户空间程序提供统一的文件和文件系统访问接口的内核子系统。借助VFS,即使文件系统的类型不同(比如NTFS和ext3),也可以实现文件系统之间交互(移动、复制文件等),
从用户空间程序的角度来看,VFS提供了一个统一的抽象、接口。这使得用户空间程序可以对不同类型的文件系统发起统一的系统调用,而不需要关心底层的文件系统类型。
从文件系统的角度来看,VFS提供了一个基于Unix-style文件系统的通用文件模型,可以用来表示任何类型文件系统的通用特性和操作。底层文件系统提供VFS规定的接口和数据结构,从而实现对linux的支持。
复制卷——self-heal自修复
- 假设是2副本构成的集群:即
node1:/data/brick、node2:/data/brick构成复制卷 - 杀死使node1上的brick的服务器进程:使brick的块Online状态变成N
kill -9 xxx - client在卷挂载目录/mnt上创建file文件
- 分别在node1、node2的/data/brick目录下查看是否有file文件
node1:无
node2:有 - 将node1的brick重新上线
gluster volume start [卷名] force - 再次检查node1的brick目录下是否有新建的file文件
结果:有!因为集群进行了自修复,使得node2节点上的数据同步到node1上
xlator中的调用(STACK_WIND)与回调(STACK_UNWIND)
STACK_WIND: 沿着volume 文件设置的xlator 路径,传递此请求
STACK_UNWIND: 当本xlator层完成对req的处理,要从本层的回调中把请求传回上一个xlator时
http://www.bubuko.com/infodetail-2761168.html
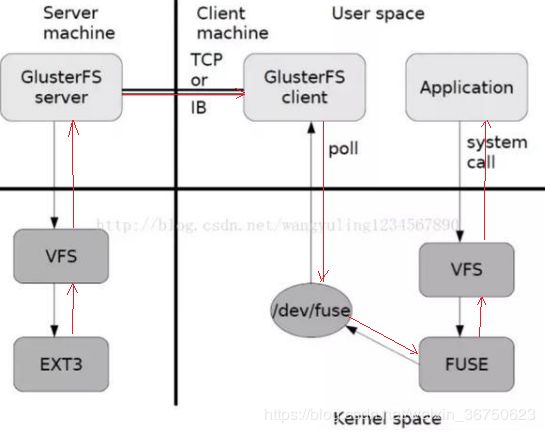
向挂载点写入数据(Linux向VFS传递这个动作)–>/dev/fuse–>fuse_xlator_t节点(进入xlator树)–>STACK_WIND递交给子节点,直到到达树的叶子节点–>STACK_UNWIND递交给父节点,直到到达fu_xlator_t–>FUSE–>VFS
App执行一次IO操作的流程
-
当APP指向系统调用向挂载点/mnt/glusterfs[写入数据]时,读写操作将会被交给VFS来处理,VFS会将请求交给FUSE内核模块,而FUSE又会通过设备/dev/fuse将数据交给glusterfs Client(此时,实际的写处理递交给了 glusterfs 系统树的 fuse_xlator_t 这个根节点,这样, [一个写数据流就正式流入了系统的 xlator_t 结构树])。
-
请求的传递[dispatch+STACK_WIND]
写处理请求从fuse_xlator_t,在(dispatch函数中)把该请求使用STACK_WIND传递给下一个或多个translator,直到到达client xlator(client模块用于与brick端通信);继续调用STACK_WIND传递给glusterfsd服务端,直到到达glusterfsd服务端的最后一个xlator
3.请求的处理[STACK_UNWIND+cbk]
(请求传递到最后一个xlator后,将不会调用STACK_WIND,而是调用STACK_UNWIND将处理后的结果和返回值传递给父volume,对应着调用父volume中的_cbk函数,即XXX_cbk),直到传递到Client的第一个xlator(fuse_xlators)。这样,一个write请求操作才算完成!
- 最后,处理的结果从fuse_xlators, 通过FUSE内核模块返回给用户。
基本概念
1、gfid:GFS卷中的每个文件或目录都有唯一的标识
1、volume:创建一个卷volume:逻辑上有N个brick构成
2、Brick :
存储目录是Glusterfs的基本存储单元,由可信存储池中服务器上对外输出的目录表示。存储目录的格式由服务器和目录的绝对路径构成,具体如下:
SERVER:EXPORT.例如:myhostname:/exports/myexportdir/
说明1:在创建卷的时候,指定Brick的挂载目录:
gluster create [卷名]:[Brick]
—>gluster create [卷名]:[/主机名/目录名]
说明2:用户对卷进行操作时,实际上数据存放在Brick上
4种进程
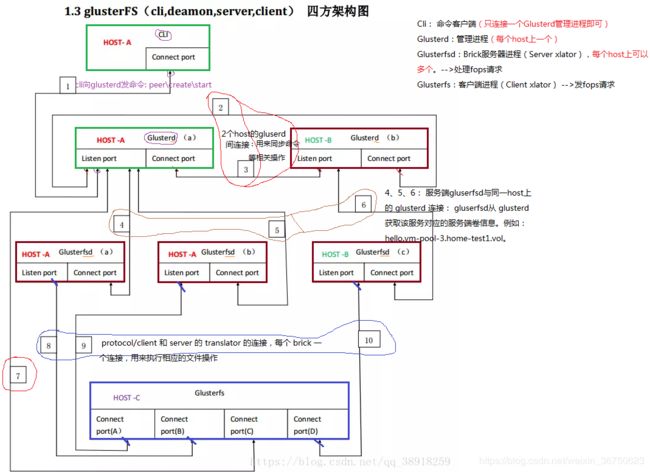
-
gluster:命令客户端
主要功能是解析命令行参数,把命令发送给glusterd模块执行,[只与glusterd管理进程通信] -
glusterd:文件系统管理进程,
(1) [处理gluster发过来的命令]
(2) 处理集群管理、存储池管理、brick管理、负载均衡、快照管理等。
集群信息、存储池信息和快照信息等都是以配置文件的形式存放在服务器中,当客户端挂载存储时, glusterd会把存储池的配置文件发送给客户端。 -
glusterfs:是客户端模块
(1) 负责通过[mount]挂载集群中某台服务器的存储池,以[目录]的形式呈现给用户
(2) 用户从此目录读写数据时,客户端根据从glusterd模块获取的存储池的配置文件信息,通过[DHT算法计算文件所在服务器的brick位置],然后通过Infiniband RDMA 或Tcp/Ip 方式[把数据发送给brick,等brick处理完,给用户返回结果]。
(3) 存储池的副本、条带、hash、EC等逻辑都在客户端处理。 -
glusterfsd:是服务端模块
(1) 存储池中的[每个brick都会启动一个glusterfsd进程]。
(2) 此模块主要是[处理客户端的读写请求,从关联的brick所在磁盘中读写数据,然后返回给客户端]。
gfs中的xlator的作用
kvm kvm虚拟机进程
io-retry xlator IO错误重试模块,根据错误码,决定是否进行io重试
io-split xlator API模式下生效,将大的IO按照128K切分
ssd-cache xlator 提供读cache,cache可缓存在SSD,连接到ssd-cached
qemu-lvm xlator
配合bd模块的lvm的使用,进行bd文件的设置,这样qcow2文件将使用lvm分区直接IO
dht xlator 文件的哈希分布,2^32区间划分
afr xlator 文件级别镜像冗余,类似raid1,VS加入了大量的修复,脑裂的处理代码
client xlator client模块用于与brick端通信
server xlator 即brick端,用于连接客户端
io-stats xlator 统计io数据,可定位性能问题
exclusive xlator 排他插件,避免同一虚拟机文件被多个客户端进程读写
io-threads xlator 将IO并行分发到不同线程,提高性能,并能设置IO优先级
locks xlator 用于实现gluster内部锁和posix锁,与afr插件有耦合
changelog xlator 控制扩展属性中的changelog字段,记录操作的是否成功entry/data/metadata,与afr插件有耦合
bd xlator block device,bd文件的读写由lvm替代文件系统,bd文件数据和元数据操作两分离
posix xlator 访问本地文件系统
ssd-cached 提供真正的ssd缓存功能,单实例运行
ssdc-cli.js 用于收集ssd-cached信息和设置ssd-cached参数
glusterfs的常用命令
https://www.jianshu.com/p/31e6a2870803
https://www.cnblogs.com/netonline/p/9102004.html
实战: 设计新的xlator,加入到gfs
null xlator的构造(刘爱贵)
https://blog.csdn.net/liuaigui/article/details/7786215/
GlusterFS的audit operation xlator设计实现方案
https://blog.csdn.net/lavorange/article/details/44902541
https://blog.csdn.net/lavorange/article/details/45246175
trashdir回收站目录只读权限以及白名单的设计与实现
https://blog.csdn.net/lavorange/article/details/47863923
GlusterFS安装
1、编译&安装
3台node机器,相互之间能ping通
下载gfs源代码,编译&安装(安装成功后,会自动启动glusterd服务)
gluster peer probe <主机名>
创建卷
2、挂载卷
假设已经安装好3个node的gfs集群,并创建了卷,后面要进行卷挂载。
在3台node上安装了gfs源码&创建了一个卷后,3台node既作为服务端brick,又作为客户端。
每个node的客户端若想访问卷,就必须在本node系统下创建一个本地目录,然后将卷挂载到本地目录。
挂载完毕后,在node上访问本地目录,就相当于在卷上执行了io操作。(即:在node上写入一个文件,本质上该文件将会被分布存储到卷的各个brick对应的目录上!!!)