redis使用笔记
最近在工作中用到了redis,涉及到redis的入库,访问,以及对于集群的一些操作. 为了防止遗忘,特别把当时的使用情况总结一下
redis使用总结
一.redis简介
以下来自 redis官网
Redis is an open source (BSD licensed), in-memory data structure store, used as a database, cache and message broker.
Redis has built-in replication, Lua scripting, LRU eviction, transactions and different levels of on-disk persistence, and provides high availability via Redis Sentinel and automatic partitioning with Redis Cluster
翻译:
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。
它支持多种类型的数据结构,如 字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。
Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过 Redis哨兵(Sentinel)和自动 分区(Cluster)提供高可用性(high availability)。
个人使用感觉:
最大的好处就是快!写入效率,读取速度都很快!
shell脚本界面很友好,当输入关键字后,还会有提示告诉我们应该怎样操作
缺点就是集群稳定性不高 : 用多线程写数据时,写入速度超过某个范围就写不过来了...会导致很多数据写入失败
二.linux操作redis
以下的示例都是用测试机器,端口为7001-7006
或者是正式的集群,端口号为默认的6379来进行操作
1. redis服务端启动
如果没有配置好path,需要到redis安装目录下面的bin目录执行 :
a. 默认方式启动redis
./redis-server & //后台启动redis
b. 指定配置文件启动redis
./redis-server 配置文件所在的目录/配置文件名 //这种方式会按照配置文件里面的配置来启动redis
检验redis是否启动成功:
ps -ef | grep 端口号 //端口号指的是redis端口号
举例 : ps -ef | grep 7001
![]()
另一种方法:
lsof -i:端口号
举例 : lsof -i:7001

如上: 证明redis已经成功启动!
2.redis客户端连接
同样,如果没有配置好path,需要到客户端的bin目录下执行命令:
a.免密连接(集群没有配置密码)
./redis-cli -c -h 主机名(ip) -p 端口号 // 无密码
b. 需要密码的连接
./redis-cil -c -h 主机名(ip) -p 端口号 -a 密码
3. 为redis分配hash槽
先来对redis的hash槽做一个基本的介绍:
Redis 集群中内置了 16384 个哈希槽,当需要在 Redis 集群中放置一个 key-value时,
redis 先对 key 使用 crc16 算法算出一个结果,然后把结果对 16384 取模.
这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点。
crc 16 算法实现:
unsigned int keyHashSlot(char *key, int keylen) { #
int s, e; /* start-end indexes of { and } */
for (s = 0; s < keylen; s++)
if (key[s] == '{') break;
/* No '{' ? Hash the whole key. This is the base case. */
if (s == keylen) return crc16(key,keylen) & 0x3FFF;
/* '{' found? Check if we have the corresponding '}'. */
for (e = s+1; e < keylen; e++)
if (key[e] == '}') break;
/* No '}' or nothing betweeen {} ? Hash the whole key. */
if (e == keylen || e == s+1) return crc16(key,keylen) & 0x3FFF;
/* If we are here there is both a { and a } on its right. Hash
* what is in the middle between { and }. */
return crc16(key+s+1,e-s-1) & 0x3FFF;
}
假设 : redis节点的数量为N, 那么为保证数据不发生倾斜, 每个节点应该分配hash槽的数量是 16384/N
有了这个分区的思路,开始对节点进行hash槽的分配
分配命令:
redis-cli -c -h 主机名(ip地址) -p 端口号 -a 集群密码 cluster addslots {起始hash槽..结束hash槽}
该命令表示 : 将起始hash槽到结束hash槽分配给指定的节点
举例 :
redis-cli -c -h 10.182.26.195 -p 6379 -a 集群密码 xxxx addslots {0..5461}
redis-cli -c -h 10.182.26.196 -p 6379 -a 集群密码 xxxx addslots {5462..10922}
redis-cli -c -h 10.182.26.197 -p 6379 -a 集群密码 xxxx addslots {10923..16383}
分配之后的结果:
使用 cluster nodes命令查看:

cluster nodes命令详解:
(该命令的)输出是空格分割的CSV字符串,每行代表集群中的一个节点。
每行的组成结构如下 : ...
每项的含义如下:
id: 节点ID,是一个40字节的随机字符串,这个值在节点启动的时候创建,并且永远不会改变(除非使用CLUSTER RESET HARD命令)。
ip:port: 客户端与节点通信使用的地址.
flags: 逗号分割的标记位,可能的值有: myself, master, slave, fail?, fail, handshake, noaddr, noflags. 下一部分将详细介绍这些标记.
master: 如果节点是slave,并且已知master节点,则这里列出master节点ID,否则的话这里列出”-“。
ping-sent: 最近一次发送ping的时间,这个时间是一个unix毫秒时间戳,0代表没有发送过.
pong-recv: 最近一次收到pong的时间,使用unix时间戳表示.
config-epoch: 节点的epoch值(or of the current master if the node is a slave)。每当节点发生失败切换时,都会创建一个新的,独特的,递增的epoch。如果多个节点竞争同一个哈希槽时,epoch值更高的节点会抢夺到。
link-state: node-to-node集群总线使用的链接的状态,我们使用这个链接与集群中其他节点进行通信.值可以是 connected 和 disconnected.
slot: 哈希槽值或者一个哈希槽范围. 从第9个参数开始,后面最多可能有16384个 数(limit never reached)。代表当前节点可以提供服务的所有哈希槽值。如果只是一个值,那就是只有一个槽会被使用。如果是一个范围,这个值表示为起始槽-结束槽,节点将处理包括起始槽和结束槽在内的所有哈希槽。
从上述的结果可以看到,hash槽已经完美的分配!
4. 查看集群重要的信息
命令 : cluster info
结果如下:

每项的含义如下:
id: 节点ID,是一个40字节的随机字符串,这个值在节点启动的时候创建,并且永远不会改变(除非使用CLUSTER RESET HARD命令)。
ip:port: 客户端与节点通信使用的地址.
flags: 逗号分割的标记位,可能的值有: myself, master, slave, fail?, fail, handshake, noaddr, noflags. 下一部分将详细介绍这些标记.
master: 如果节点是slave,并且已知master节点,则这里列出master节点ID,否则的话这里列出”-“。
ping-sent: 最近一次发送ping的时间,这个时间是一个unix毫秒时间戳,0代表没有发送过.
pong-recv: 最近一次收到pong的时间,使用unix时间戳表示.
config-epoch: 节点的epoch值(or of the current master if the node is a slave)。每当节点发生失败切换时,都会创建一个新的,独特的,递增的epoch。如果多个节点竞争同一个哈希槽时,epoch值更高的节点会抢夺到。
link-state: node-to-node集群总线使用的链接的状态,我们使用这个链接与集群中其他节点进行通信.值可以是 connected 和 disconnected.
slot: 哈希槽值或者一个哈希槽范围. 从第9个参数开始,后面最多可能有16384个 数(limit never reached)。代表当前节点可以提供服务的所有哈希槽值。如果只是一个值,那就是只有一个槽会被使用。如果是一个范围,这个值表示为起始槽-结束槽,节点将处理包括起始槽和结束槽在内的所有哈希槽。
5.redis的其它操作
a. 清空节点全部数据! (慎用!!)
flushall //从删库到跑路的第一步
b. 查看节点全部的key
命令 : keys *

从上面可以看出 : 当前节点存储了 83461个key的数据
c. 向节点添加键值对数据
set key(键) value(值)
举例 : set name libai //设置键为name ,value为libai
get key(键) // 获得某个键的值
举例 : get name

d.删除节点中某个键的数据
del key(键)
举例 : del name

e.查询某个节点占用资源情况
info memory

三. 通过java使用redis
1. maven导入redis依赖
在 <dependencies></dependencies> 标签里面添加:
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
<type>jar</type>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
<version>2.4.2</version>
</dependency>
如果在打jar包的时候希望把redis相关的依赖打进jar包里
需要在pom.xml 添加上类似的配置
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<!-- 自动将所有不使用的类全部排除掉 -->
<minimizeJar>false</minimizeJar>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>cn.mastercom.bigdata.test.RedisTest</mainClass>
</transformer>
</transformers>
<artifactSet>
<includes>
<include>org.apache.commons:commons-pool2</include>
<include>redis*</include>
</includes>
</artifactSet>
<filters>
<filter>
<artifact>*:*</artifact>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
2. 使用java获取redis连接
首先写一个获取redis连接的工具类 :
import java.util.HashSet;
import java.util.Set;
import redis.clients.jedis.HostAndPort;
import redis.clients.jedis.JedisCluster;
import redis.clients.jedis.JedisPoolConfig;
/**
* 获取redis连接的工具类
* @author xmr
*
*/
public class JedisClusterFactory
{
private static JedisCluster jc = null;
private static HostAndPort [] hostAndPort;
private final static String SPLIT = ",";
private static class InstanceHolder
{
private static final JedisClusterFactory instance = new JedisClusterFactory();
}
public static JedisClusterFactory getInstance()
{
return InstanceHolder.instance;
}
public static void main(String[] args)
{
}
/**
* 获取redis连接
* @param redisConfig
* @param timeOut
* @param password
* @return
*/
public JedisCluster getJedisCluster(String redisConfig, int timeOut, String password)
{
if (jc != null)
{
return jc;
}
String [] strs = redisConfig.split(SPLIT);
hostAndPort = new HostAndPort[strs.length];
for (int i = 0; i < strs.length; i++)
{
hostAndPort[i] = new HostAndPort(strs[i].split(":")[0], Integer.valueOf(strs[i].split(":")[1]));
}
Set<HostAndPort> hostAndPorts = new HashSet<HostAndPort>();
for (int i = 0; i < strs.length; i++)
{
hostAndPorts.add(hostAndPort[i]);
}
JedisPoolConfig config = new JedisPoolConfig();
jc = new JedisCluster(hostAndPorts, timeOut, 0, 30, password, config);
return jc;
}
**使用方法, 在该类或者是任意一个类的main方法里面添加如下代码 : **
public static void main(String[] args)
{
JedisCluster jc = JedisClusterFactory.getInstance().getJedisCluster(args[0], 10000, args[1]);
// args[0] 是集群的节点和端口号 形如: 10.182.26.195:6379,10.182.26.196:6379,10.182.26.197:6379 注意: 这里必须是集群的全部节点,少输入或者是输错一个,都会导致连接失败!
// args[1] 是redis集群的密码
}
3. 使用java将数据写入redis
/**
* 将文件保存到redis,以key作为文件名
* @param jc
* @param f
*/
public static void saveFileToRedis(JedisCluster jc, File f) {
try (FileInputStream fis = new FileInputStream(f);
ByteArrayOutputStream baos = new ByteArrayOutputStream();
) {
IOUtils.copy(fis, baos);
byte[] value = baos.toByteArray();
jc.set((f.getName(), value);
} catch (IOException e) {
// log.error("保存文件到redis出现问题", e);
}
}
调用办法 :
public static void main(String[] args)
{
JedisCluster jc = JedisClusterFactory.getInstance().getJedisCluster(args[0], 10000, args[1]); //获取redis连接
File f = new File("C:\\Users\\DELL\\Desktop\\SIMU\\FINGERPRINT_OUT_163366914.txt.gz"); // 获取file流
saveFileToRedis(jc, f); // 将文件写入redis
}
去redis里面使用 get FINGERPRINT_OUT_163366914.txt.gz 命令 查看我们刚刚入库的数据

从结果中可以看到:
上述代码的写入方式是以key为文件名, 以文件的二进制内容作为值
为什么要采用这种方式呢?
因为写入的是.gz的压缩文件,用这种方式可以节约redis的内存占用,毕竟内存这种东西实在是太昂贵了!! 浪费不起啊!!!
4. 使用java读取入库后的文件
这里我写了两个方法 : 第一个方法是得到一个可以读取这种数据的BufferedReader流
第二个方法通过我获得的这个流 去读取数据,输出结果:
两个方法如下 :
/**
* 从redis集群中加载GZ文件并解压缩,返回一个BufferedReader
*
* @param jc jedisCluster对象
* @param key 文件名
* @return BufferedReader对象或NULL
*/
public static BufferedReader loadsAndUnzipFileFromRedis(JedisCluster jc, String key) {
assert jc != null;
assert key != null && key.length() != 0;
byte[] bytes = jc.get(key.getBytes());
ByteArrayInputStream bais = null;
GZIPInputStream gzis = null;
InputStreamReader isr = null;
try {
bais = new ByteArrayInputStream(bytes);
gzis = new GZIPInputStream(bais);
isr = new InputStreamReader(gzis);
return new BufferedReader(isr);
} catch (IOException e) {
log.error("创建BufferedReader出现异常", e);
try
{
if (bais != null)
bais.close();
}
catch (Exception e0)
{
}
return null;
}
}
/**
* 通过BufferedReader流读取入库数据
* just for test
* @param br
*/
private static void readSimuConfig(BufferedReader br) {
if (br == null)
{
System.out.println("没有获取到bufferedReader! 请检查! ");
return;
}
try {
while ((br.readLine()) != null)
{
String sline = br.readLine();
System.out.println(sline);
}
} catch (Exception ee){
System.out.println("读取key失败! ");
}
finally
{
if(br != null)
{
try {
br.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
调用方法 :
public static void main(String[] args)
{
JedisCluster jc = JedisClusterFactory.getInstance().getJedisCluster(args[0], 10000, args[1]); // 获取redis连接
String rowkey = args[2]; //获取行键
BufferedReader br = RedisUtil.loadsAndUnzipFileFromRedis(jc, rowkey); //获取BufferedReader流
readSimuConfig(br); //读取并输出数据
}
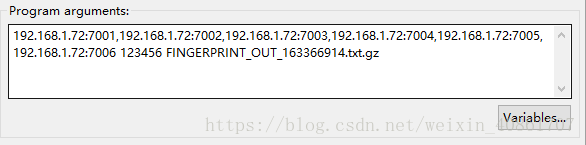
args 参数如下图所示 :
部分输出结果:

可以证明 : 入库,读取都能够成功!
四.参考链接:
redis中文官网
redis官网