葵花宝典
新博客:https://wywwzjj.top
用一个简单的文本把每次出错的信息记录下来,
后面如果解决了就把解决方法也记录一下,
养成这种学习习惯,你会受益匪浅。
端口转发
最简单的办法
win10 openssh
# win
ssserver -p 2333 -k rois2018 -m aes-256-cfb # 跑s
ssh -R 0.0.0.0:2333:localhost:2333 [email protected] # ssh设置
#
# vps
Xshell ssh 隧道
proxychains in Linux
Proxifier in Windows
ssh 10.105.1.30 -lattacker -D1082 -L0.0.0.0:1994:10.105.1.14:80 -L0.0.0.0:1998:10.105.1.18:22 -L0.0.0.0:1993:10.105.1.13:80 -L0.0.0.0:1992:10.105.1.12:80 -R0.0.0.0:80:0.0.0.0:80
reGeorg
clash
ew
Google hacking
常用语法备忘
phpstudy 设置域名与ip
https://www.cnblogs.com/jewave/p/5625878.html
http://www.keydatas.com/html/apache.html?audience=320658
计算机网络
路由表配置
必须要学会配路由,使得内网和外网同时能访问
windows下配路由表利器:NetRouteView
无线网卡:11
有线网卡:4
route print / netstat -r # 显示本地路由表
route add 0.0.0.0 mask 0.0.0.0 xxx METRIC 1 IF ID # 全局
# xxx 设置为实际上网网卡的网关,ID 设置为实际网卡 ID
route add 10.0.0.0 mask 255.0.0.0 xxx IF ID # 上内网
# xxx 设置为 OpenVPN 网关,ID 为 OpenVPN 的虚拟网卡ID(TAP)
# 配错了的话
route delete 0.0.0.0 / 10.0.0.0
:删除默认设置
route delete 0.0.0.0
:外网路由,全走无线
route add 0.0.0.0 mask 0.0.0.0 192.168.0.1 # -p 永久路由
:公司内网全部在10.108.*.*网段,增加此路由
route add 10.108.0.0 mask 255.255.0.0 10.108.58.1
route add 134.105.0.0 mask 255.255.0.0 134.105.64.1
意思是:所有需要发往134.105.0.0/16地址段的IP数据包,全部由134.105.64.1路径转发。
Regular Expression
# 入门
# \b 匹配单词的开头或结尾
# 如果要查找 hi 这个单词,表达为 \bhi\b
\bhi\b.*\bLucy\b
# . 表示除换行符以外的任意字符
# * 代表数量,它指定 * 前边的内容可以重复使用任意次
# 和起来 => 匹配 hi ... Lucy
0\d\d-\d\d\d\d\d\d\d\d # \d 表示一位数字, - 为连字符,只匹配本身
# 简化一下 => 0\d{2}-\d{8}
# \s 匹配任意的空白字符
# \w 匹配字母或数字或下划线或汉字等
\ba\w*\b # 表示匹配任意长度以 a 开头的单词
\d+ # 匹配 1 个或多个连续的数字,+ 和 * 类似,不过 + 是至少一次
\b\w{6}\b # 匹配长度恰好为 6 的单词
# ^ 匹配字符串的开始
# $ 匹配字符串的结束
^\d{5,12}$ # 表示整个字符串只能是 5~12 位数字
# 元字符
. 除换行符以外的任意字符
\w 字母或数字或下划线或汉字
\s 任意的空白符
\d 数字
\b 单词的开始或结束
^ 字符串的开始
$ 字符串的结束
# 字符转义 => \
# 重复
* 任意次
+ 至少 1 次
? 0 次或 1 次
{n} 重复 n 次
{n,} 至少 n 次
{n,m} n ~ m 次
# 字符类
如果想匹配没有预定义元字符的字符集合
比如元音字母 a, e, i, o, u => [aeiou]
比如匹配一些标点符号 . ? ! => [.?!]
还可以轻松地指定一个字符范围
比如 [0-9] == \d ,含义与 \d 是完全一致的,还有 [a-z0-9A-Z] == \w
\(?0\d{2}[)-]?\d{8}) => (010)88886666 / 022-22334455 / 02912345678
# 分枝条件
不幸的是,上面那个表达式也能匹配到 010)12345678 / (022-87654321 这种格式,此时就要用到分枝条件
分枝条件指的是有几种规则,如果满足其中任意一种规则都应该当成匹配,用 | 进行分隔
0\d{2}-\d{8}|0\d{3}-d{7} # 注意分隔符,此时就能匹配两种格式的号码了,3 + 8 / 4 + 7
\(0\d{2}\)[-]?\d{8}|0\d{2}[-]?\d{8} # 匹配 (0xx) - xx.. / (xxx) xx.. / 0xx-xx.. / ..
\d{5}-\d{4}|\d{5} # xxxxx-xxx | xxxxx
# 使用分枝条件时还要注意各个条件的顺序
比如 \d{5}|\d{5}-\d{4} ,它只会匹配5位的邮编(以及9位邮编的前5位)
匹配分枝条件时,将会从左到右地测试每个条件,如果满足了某个分枝的话,就不会去再管其他条件
# 分组
重复单个字符很方便,那么重复一个字符串呢?就可以用小括号进行分组了,也叫做子表达式
(\d{1,3}\.){3}d{1,3} # 简单的IP地址匹配 1.1.1.1
然而上面的表达式也可能出现 256.300.888.999,正则表达式又不提供任何数学计算
只能这样用:((2[0-4]\d|25[0-5]|[01]?\d\d?)\.){3}(2[0-4]\d|25[0-5]|[01]?\d\d?)
(?<name>exp) # 命名
# 反义
\W 任意不是字母,数字,下划线,汉字的字符
\S 任意非空白符的字符
\D 任意非数字的字符
\B 不是单词开头或结束的位置
[^x] 非x的任意字符
[^aeiou] 非aeiou的任意字符
如:\S+ 不包含空白符的字符串
<a[^>]+> 用尖括号括起来的以a开头的字符串
# 后向引用
# 零宽断言
# 负向零宽断言
# 注释
(?#注释) 直接加到exp后面
# 贪婪与懒惰
默认贪婪状态
*? 重复任意次,但尽可能少重复
+? 重复1次或更多次,但尽可能少重复
?? 重复0次或1次,但尽可能少重复
{n,m}? 重复n到m次,但尽可能少重复
{n,}? 重复n次以上,但尽可能少重复
# 处理选项
# 平衡组/递归匹配
# php的正则
preg_match() / preg_match_all()
用来做包围的字符不能出现在re中,否则会出现矛盾,将报错
可以用以下符号包围正则参数
`~!@#$%^&*-+/
继续学习
- py re
re.search(pattern, )
Flask
配置虚拟环境
pip install virtualenv
mkdir flaskenv
cd flaskenv
virtualenv flask-env # --no-site-packages 纯净py环境
cd Script
activate # 不要 ./activate
deactivate
Start
# 初始化一个Flask对象
# __name__ 方便flask寻找资源,方便插件寻找问题
app = Flask(__name__)
app.run(debug=True) # 设置debug模式
Django
创建项目:
django-admin startproject project_name
目录解释:
│manage.py # 命令行工具,可以用多种方式对Django项目进行交互
│
└─djtest
settings.py # 项目的配置文件
urls.py # 项目的URL声明
wsgi.py # 项目与WSGI兼容的服务器入口
__init__.py # 空文件,它告诉Python这个目录应该被看做一个Python包
基本操作:
- 设计表结构
前端部分
- **HTML是网页内容的载体。**内容就是网页制作者放在页面上想要让用户浏览的信息,可以包含文字、图片、视频等。
- **CSS样式是表现。**就像网页的外衣。比如,标题字体、颜色变化,或为标题加入背景图片、边框等。所有这些用来改变内容外观的东西称之为表现。
- **JavaScript是用来实现网页上的特效效果。**如:鼠标滑过弹出下拉菜单。或鼠标滑过表格的背景颜色改变。还有焦点新闻(新闻图片)的轮换。可以这么理解,有动画的,有交互的一般都是用JavaScript来实现的。
HTML
HTML不是一种编程语言,而是一种标记语言。
除了某些单标签,其他都是成对出现的。
语法骨架:
// 声明为HTML5文档,有助于浏览器正确显示网页
<html>
<head>
<meta charset="utf-8"> // 定义网页编码格式为 utf-8
<title>这是一个骨架哟title>
head>
<body> // 包含了可见的页面内容
<h1>我的第一个标题h1>
<h2>这是一个标题h2>
<h3>这是一个标题h3>
<p>我的第一个段落p>
body>
html>
常用标签
<span>span> 为文字设置单独样式
<q>q> 短文本引用
<blockquote>blockquote> 长文本引用
<br> 换行
空格
<hr> 水平横线
<address>address> 地址信息
<code>code> 插入代码
<pre>pre> 插入大段代码(保留原格式)
<ul>
<li>信息1li> 新闻信息列表(无序)
<li>信息2li>
ul>
<ol>
<li>信息1li> 销售排行榜(有序)
<li>信息2li>
ol>
<div id="">div>
<table>
<tr>
<th>姓名th>
<th>年龄th>
<th>性别th>
tr>
table>
表单与PHP交互
GET:显示在地址栏,长度有限制,可以资源定位。格式 ? what=flag
POST:不会显示在地址栏,可用来提交密码
CSS
基本语法
selector {
property:value;
}
h1 {
color:red; /*属性值与单位之间不能留有空格*/
font-size:14px;
}
/*如果值大于1个单词时,则需要加上引号:*/
p {font-family:"sans serif"}
/*外部样式*/
"stylesheet" type="text/css" href="mystyle.css">
/*内部样式*/
/*内联样式:单独针对某个元素设置下属性*/
"color:sienna;margin-left:20px"
>这是一个段落。
/*多重样式:*/
如果某些属性在不同的样式表中被同样的选择器定义,属性值将从更具体的样式表中被继承过来。
h3 { // 外部css
color:red;
text-align:left;
font-size:8pt;
}
h3 { // 内部css
text-align:right;
font-size:20pt;
}
/* 最终效果
* color:red;
* text-align:right;
* font-size:20pt;
*/
/*优先级:*/
内联样式 > 内部样式 > 外部样式 > 浏览器默认样式
注意:如果外部样式放在内部样式的后面,则外部样式将覆盖内部样式
/*背景*/
body {
background-color:#b0c4de; // 设置元素的背景颜色
background-image:url('paper.gif'); // 把图像设置为背景
background-repeat:repeat-x; // 设置背景图像是否及如何重复
background-attachment // 背景图像固定或滚动
background-position:right top; // 设置背景图像的起始位置
}
body {background:#ffffff url('img_tree.png') no-repeat;} // 直接 background 简写属性
/*文本格式*/
文本颜色
body {color:red;}
h1,h2,h3 {color:#00ff00;} // 多个标签用同一个属性
h2 {color:rgb(255,0,0);}
文本对齐方式
h1 {text-align:center;}
p.date {text-align:right;}
p.main {text-align:justify;} // 每一行被展开为宽度相等,左,右外边距是对齐(如杂志,报纸)
文本装饰:删除链接的下划线
h1 {text-decoration:overline;} // 上划线
h2 {text-decoration:line-through;} // 中划线
h3 {text-decoration:underline;} // 下划线
文本转换:大小写
p.uppercase {text-transform:uppercase;}
p.lowercase {text-transform:lowercase;}
p.capitalize {text-transform:capitalize;}
文本缩进:文本的第一行的缩进
p {text-indent:50px;}
/*字体*/
设置文本的字体系列,应该多设置几个字体名称,如果浏览器不支持第一种字体,他将尝试下一种字体
p{font-family:"Times New Roman", Times, serif;}
字体样式
p.normal {font-style:normal;}
p.italic {font-style:italic;}
p.oblique {font-style:oblique;}
字体大小
h1 {font-size:40px;}
h2 {font-size:30px;}
p {font-size:14px;}
为了避免Internet Explorer 中无法调整文本的问题,许多开发者使用 em 单位代替像素 1em = 16px
把段落设置为小型大写字母字体
p {font-variant:small-caps;}
字体粗细
p.normal {font-weight:normal;}
p.thick {font-weight:bold;}
p.thicker {font-weight:900;}
/*链接*/
a:link {color:#000000;} // 未访问链接
a:visited {color:#00FF00;} // 已访问链接
a:hover {color:#FF00FF;} // 鼠标移动到链接上
a:active {color:#0000FF;} // 鼠标点击时
高级玩法:方框显示
a:link,a:visited {
display:block;
font-weight:bold;
color:#FFFFFF;
background-color:#98bf21;
width:120px;
text-align:center;
padding:4px;
text-decoration:none;
}
a:hover,a:active {background-color:#7A991A;}
/*列表*/
列表项标记样式
ul.a {list-style-type: circle;}
ul.b {list-style-type: square;}
ol.c {list-style-type: upper-roman;}
ol.d {list-style-type: lower-alpha;}
标记的背景图像
ul {list-style-image: url('sqpurple.gif');}
简写
ul {list-style: square url("sqpurple.gif");}
位置
ul {list-style-position: inside;}
/*表格*/
/**/
/**/
/**/
/**/
/**/
/**/
/**/
/**/
/**/
/**/
/**/
/**/
/**/
/**/
/**/
/**/
/**/
/**/
/**/
/**/
/**/
/**/
/**/
/**/
/**/
/**/
/**/
/**/
/**/
/**/
/**/
/**/
/**/
/**/
/**/
/**/
/**/
/**/
/**/
/**/
/**/
/**/
/**/
派生选择器
依据元素在其位置的上下文关系来定义样式,可以使标记更加简洁
id 选择器
这是一个div
#idd {proprety:value;}
类选择器
属性选择器
[属性=值] {}
JavaScript
PHP
-
(1) 熟悉HTML/CSS/JS等网页基本元素,完成阶段可自行制作简单的网页,对元素属性相对熟悉。
-
(2) 理解动态语言的概念和运做机制,熟悉基本的PHP语法。
-
(3) 学习如何将PHP与HTML结合起来,完成简单的动态页面。
-
(4) 接触学习MySQL,开始设计数据库。
-
(5) 不断巩固PHP语法,熟悉大部分的PHP常用函数,理解面向对象编程、MySQL优化,以及一些模板框架。
-
(6) 最终完成一个功能齐全的动态站点。
-
新手不要看到上面的概括就以为PHP学习是很简单的,编程是需要你认真的思考和不断的实践。下面具体解释一下PHP的学习线路。首先,任何网站都是由网页组成的,也就是说想完成一个网站,必须先学会做网页,掌握静态网页的制作技术是学习开发网站的先决条件。因此我们要学习HTML,为今后制作网站打下基础。学习HTML应该边学边做,HTML中的任何元素都要亲自实践,只有明白了什么元素会起到什么效果之后,才能深刻记忆,一味的看书是不行的。
-
假设你已经可以完成一个静态页面了,那么就该开始了解动态语言,刚一接触动态语言,可能很多人都会有很多不解,代码不是作为直接输出的,而是要经过处理的,HTML是经过HTML解析器,而PHP也要通过PHP解析器,跟学习HTML一样的道理,想让任何的解析器工作,就必须使用它专用的语法结构。
-
学习PHP,你应该感到幸运,因为如果你学过其他语言,你就会发现PHP还是相对简单的,这一阶段,你要搞清楚HTML和PHP的概念,你现在完全可以让PHP给你算算一加一等于几,然后在浏览器输出。不要觉得幼稚,这虽然是很小的一段代码,但是对于你的编程之路,可是迈出了一大步。不过现在,你还是一个菜鸟。
-
接下来就要学习数据库了,MySQL可以说是PHP的黄金搭档,我们要征服这个数据库,在你理解了数据库的概念之后,就要尝试通过PHP来连接数据库,进而会用PHP成功的插入,删除和更新数据。
-
这个时候,你可能会处于这种状态:你会HTML吗?会,我能编好几个表格排板的网页呢!你会PHP吗?会,我会把一加一的运算写在函数里,然后调用!你会MySQL吗?会,我可以把数据库里的数据插入删除啦!
-
那接下来该做什么呢?尝试着做个小的留言本吧,这同样是新手面临的一道关卡。花了一段时间,你终于学会把表单的数据插入数据库,然后显示出来了,应该说一个程序的雏形已经诞生了。但是,你可能会看人家这个编论坛,那个开发CMS,我什么时候可以写一个呢?不要急,再巩固一下知识,熟悉了PHP和MySQL开发的要领后,再回头看你写的那个留言本,你也许会怀疑那真的是你写的吗?这个时候,你可以完善一下你写的留言本。留言本应该加入注册以及分页的功能,可以的话,UI也可以加强。
-
这就算学会了吗?NO,NO,NO,还早呢,你到现在还没碰过OOP呢吧?那模板和框架呢?还要继续学习呀!PHP框架提供了一个用以构建web应用的基本框架,从而简化了用PHP编写web应用程序的流程。可以节省开发时间、有助于建立更稳定的应用。所以说,PHP框架是一个可以用来节省时间并强化自己代码的工具。当你第一次选择PHP框架时,建议多尝试几个,每个框架都有自己的长处和短处,例如Zend框架由于多样的功能、并且有一个广泛的支持系统,流行了很长时间。而CakePHP是一个晚于Zend的PHP框架,相应的支持系统也比较少,但是更为方便和易于使用。
-
了解了面向对象和框架后,你应该接触一下XML了,总而言之,你绝对不会发现你全部都学会了,学无止境!学东西,永远不要妄想有速成这一说,技巧再多,但是缺少努力,那也是白搭。有一点可以保证,就是你学会了PHP,那么再学其它语言,肯定速成,反过来也一样,如果你之前学过其它的语言,那么学PHP肯定快。
-
多借鉴别人成功的代码,绝对是有益无害,所以要多看那些经过千锤百炼凝出来的经典代码,是进步的最好方法。另外,要强调的是,学习一项技术过程中可能会遇到困难,可能会迷茫,你也许学了一半的PHP,又开始打C#的主意,或者有人说Java很好,这个时候你绝对不能动摇,要坚持到底,彻底学会。祝你顺利学成PHP,开发自己想要的网站。
解决中文输出乱码:
header("Content-type:text/html;charset=utf-8");
?>
// 这就是PHP的标识
echo "This is PHP that can be run on Server"; ?>
// 字符串
需要用 " ", ' ', Heredoc?都可以...
" "中出现变量的时候,变量会自动和双引号的内容连在一起
$a .= $b // 将b字符串加到a右边
当字符串很长的时候,使用Heredoc结构
$string1 = <<<GOD
我有一只小毛驴,我从来也不骑。
有一天我心血来潮,骑着去赶集。
我手里拿着小皮鞭,我心里正得意。
不知怎么哗啦啦啦啦,我摔了一身泥.
GOD;
echo $string1;
?>
直接输出长字符串
echo <<<EOF // 这个EOF可以任意命名,与结尾处相同即可
<h1>哈哈哈哈</h1>
<p>这是标题</p>
EOF;
// 结束需要独立一行且前后不能空格
?>
echo 12*3; ?>
echo "Hello, " . "PHP!"; ?>
// 变量
$var = "This is a avarible"
var_dump($var) // 可输出变量类型
// 特殊类型——资源
资源是由专门的函数来建立和使用的,例如打开文件、数据连接、图形画布。我们可以对资源进行操作(创建、使用和释放)。任何资源再不需要的时候应该被及时释放。如果我们忘记释放资源,系统自动启动垃圾回收机制,在页面执行完毕后回收资源,以免内存被消耗殆尽。
//首先采用“fopen”函数打开文件,得到返回值的就是资源类型。
$file_handle = fopen("D:\\i.txt", "r");
if ($file_handle){
//接着采用while循环一行行地读取文件,然后输出每行的文字
while (!feof($file_handle)) { //判断是否到最后一行
$line = fgets($file_handle); //读取一行文本
echo $line; //输出一行文本
echo "
"; //换行
}
}
fclose($file_handle);//关闭文件
?>
// 特殊类型——NULL
NULL是空类型,对大小写不敏感,NULL类型只有一个取值,表示一个变量没有值,当被赋值为NULL,或者尚未被赋值时,或者被unset(),在这三种情况下变量被认为是NULL。
// 常量
自定义常量
bool define(string $constant_name, mixed$value[, $case_sensitive = true])// 大小写敏感
define("PI",3.14);
$p = "PII";
define($p,3.14);
系统常量
系统常量是PHP已经定义好的常量,我们直接拿来使用
__FILE__:PHP程序文件名。它可以帮助我们获取当前文件在服务器的物理位置。
__LINE__:PHP程序文件行数。它可以告诉我们,当前代码在第几行。
__DIR__:文件所在目录
PHP_VERSOIN:当前解析器的版本号。
PHP_OS:执行当前PHP版本的操作系统名称。
// 如何获得常量的值呢?
1.直接使用常量名,如 PI、PII
2.使用constant()函数,如 constant("PI")
// 如何判定常量是否被定义?
使用defined()函数,其返回值为bool。如 defined(PI)
// 引用
$b = $a;
$c = &$a; // c为a的引用,两变量共享一块内存
// 比较运算符
== 等于则TRUE
!= <> 不等则TRUE
=== 相等且类型相同才TRUE
!== 非全等,不相等或类型不同则TRUE
< > <= >=
// 三元运算符与c同
$a = 78;
$b = $a >= 60 ? "及格" : "不及格";
// 逻辑运算符
and or xor ! && ||
// 错误控制运算符——“@”
对于一些可能会在运行过程中出错的表达式,我们不希望出错的时候给用户显示这些错误信息。
于是,可以将@放置在一个PHP表达式之前,该表达式的坑产生的任何错误信息都被忽略掉
header("Content-type:text/html;charset=utf-8");
$conn = @mysqli_connect("localhost", "username", "passwd");
echo "出错了,错误信息是:" . $php_errormsg;
?>
$num = rand(1,50); // 获取1至50的随机数
// foreach()
foreach(数组 as 值) foreach(数组 as 下标 => 值)
header("Content-type:text/html;charset=utf-8");
$students = array(
'2010'=>'令狐冲',
'2011'=>'林平之',
'2012'=>'曲洋',
'2013'=>'任盈盈',
);
foreach ($students as $v){
echo $v;//输出(打印)姓名
echo "
";
}
foreach ($students as $key => $v){
echo $key . $v;
echo "
";
}
?>
// 数组
1.数值数组-带有数字 ID 键的数组
$cars = array("Volvo","BMW","Toyota"); // 自动分配 ID 键(0开始)
获取数组长度——count($cars)
2.关联数组-带有指定的键的数组,每个键关联一个值(dict)
$age=array("Peter"=>"35","Ben"=>"37","Joe"=>"43");
3.多维数组-包含一个或多个数组的数组
// 函数
function functionName($arg1, $arg2){return;}
杂项
ini_set("display_error", True); // 为 php.ini 中的选项值设置初始值
ini_get('display_error'); // 取值
exit(status) // 输出一条消息,并退出当前脚本,与下同
die(status) // exit() 的别名,若status为字符串,则该函数会在退出前输出字符串,若为整数,这个值将会做退出状态。0为正常终止。
eval(phpcode) // 把字符串作为PHP代码运行
trim(string(,char)) // 移除字符串两侧的空白字符或指定字符
addslashes(string) // 为string中的 ',",\,NULL添加'\'
is_string($var) // 检测变量是否为字符串
strval(mixed $var) // 返回var的字符串
strrev(str) // 反转字符串
var_dump(var) // 打印变量的相关信息
show_source() // 对文件进行语法高亮显示
$a = @$_REQUEST['hello']; // 抑制报错信息的显示
Ruby on rails
Rails框架的主要结构是MVC(Model-View-Controller)
MVC的几点理解:
-
MVC最重要的是模型Model,业务逻辑写在Model里
-
控制器Controller里面越少越好,业务逻辑不要写在控制器里
-
View是可以看到的东西
MVC的终极目标:
将软件用户界面和业务逻辑分离,以使代码可扩展性,可复用性,可维护性,灵活性加强
现实中的 Web 应用:
- Model 层是数据库访问层
- View 层是 web 展示的样子
- Controller 层写的是业务逻辑
scaffold生成User数据模型**
$ rails generate scaffold User name:string email:string
撤销generate操作
$ rails generate controller StaticPages home help
$ rails destroy controller StaticPages home help
迁移数据库——使用新的数据模型更新数据库
rails db:migrate
撤销迁移
$ rails db:rollback
回滚到最初状态
$ rails db:migrate VERSION=0 # 最后一个数字为版本号
撤销generate操作
$ rails generate controller StaticPages home help
$ rails destroy controller StaticPages home help
常用命令
| 完整形式 | 简写形式 |
|---|---|
$ rails server |
$ rails s |
$ rails console |
$ rails c |
$ rails generate |
$ rails g |
$ rails test |
$ rails t |
$ bundle install |
$ bundle |
开发中的小问题
-
U 盘格式化
diskpart lis dis sel dis ID clean create partition primary active format fs=fat32 quick -
sudo echo > 权限不够
➜ ~ sudo echo ‘
Hello, Docker!
’ > /var/www/html/test.html
zsh: permission denied: /var/www/html/test.html原因:sudo只是让echo命令具有root权限,> 没有 # sh -c 将字符串作为完整命令来执行 sudo sh -c "echo >" # 利用管道和tee命令,该命令可从标准输入中读入信息并将其写入标准输出或文件中 echo 'Hello, Docker!
' | sudo tee /test.html echo 'Hello, Docker!
' | sudo tee -a /test.html # -a 为追加 -
.swp 文件恢复
假设你的swp文件叫'.m.php.swp'
可用带-r参数编辑
#vi -r m.php
然后wq保存即可
或者使用:
#vi .m.php.swp
然后:recover
最后wq保存
- VM 共享文件夹
常规操作后,/mnt 目录下无 hgfs 文件夹,暂时没有解决:
- 在 kali 上 open-tools 之类的都显示定位失败
- 直接挂载还是啥都没有
**解决办法:**重装vm-tools,一路回车,不用管
PHP 中文输出乱码
一、HTML页面编码设置
1.在head标签里面加入这句
<head>
<metahttp-equiv="Content-Type"content="text/html; charset=UTF-8"/>
</head>
2.文件保存时设置编码UTF-8
二、PHP编码设置
在方法一的基础上在php代码时最前面即第一句写上
header("Content-type:text/html;charset=utf-8");
?>
三、Mysql编码设置
在前面的基础上,还要在你的数据查询/修改/增加之前加入数据库编码。
mysql_query('SET NAMES UTF8');
?>
rails new lmzdx -d mysql* 报错
An error occurred while installing mysql2 (0.5.2), and Bundler cannot
continue.
Make sure that `gem install mysql2 -v '0.5.2' --source 'https://rubygems.org/'`
succeeds before bundling.
In Gemfile:
mysql2
run bundle exec spring binstub --all
bundler: command not found: spring
Install missing gem executables with `bundle install`
Solution
I think you missing dev library of mysql:
On ubuntu:
$ sudo apt-get install libmysqlclient-dev
On Red Hat/CentOS and other distributions using yum:
$ sudo yum install mysql-devel
On Mac OS X with Homebrew:
$ brew install mysql
rails 新项目后运行cap install STAGES=production 报错
显示cap没有安装
此时不要听Ubuntu的建议去使用apt安装
重启终端即可
TZInfo::DataSourceNotFound: tzinfo-data is not present.
01 rake aborted!
01 TZInfo::DataSourceNotFound: tzinfo-data is not present.
Solution
run gem install tzinfo-data
or add gem 'tzinfo-data' to your Gemfile and run bundle install
直接gem安装可能会报错,说什么找不到,此时可以先 bundle update && bundle install
最重要的一步来了 git push
服务器是直接去GitHub上取代码,如果不同步给GitHub,仍然会报老错误
nginx 配置 /etc/nginx/sites-enabled/default 时挂掉
如果备份文件与配置文件就放在同一目录时,备份文件需要以.开头,
否则会与配置文件冲突,导致nginx挂掉(并非以文件名来识别)
capistrano 信息
================= Release notes for capistrano-passenger ===========================
passenger once had only one way to restart: `touch tmp/restart.txt`
Beginning with passenger v4.0.33, a new way was introduced: `passenger-config restart-app`
The new way to restart was not initially practical for everyone,
since for versions of passenger prior to v5.0.10,
it required your deployment user to have sudo access for some server configurations.
capistrano-passenger gives you the flexibility to choose your restart approach, or to rely on reasonable defaults.
If you want to restart using `touch tmp/restart.txt`, add this to your config/deploy.rb:
set :passenger_restart_with_touch, true
If you want to restart using `passenger-config restart-app`, add this to your config/deploy.rb:
set :passenger_restart_with_touch, false # Note that `nil` is NOT the same as `false` here
If you don't set `:passenger_restart_with_touch`, capistrano-passenger will check what version of passenger you are running
and use `passenger-config restart-app` if it is available in that version.
If you are running passenger in standalone mode, it is possible for you to put passenger in your
Gemfile and rely on capistrano-bundler to install it with the rest of your bundle.
If you are installing passenger during your deployment AND you want to restart using `passenger-config restart-app`,
you need to set `:passenger_in_gemfile` to `true` in your `config/deploy.rb`.
====================================================================================
Docker
基本概念
一个 Docker Registry 中可以包含多个 仓库(Repository);
每个仓库可以包含多个标签(Tag);每个标签对应一个镜像。
镜像和容器的关系,就像类与对象
安装
# 更新相关软件
sudo apt update
sudo apt install apt-transport-https ca-certificates curl software-properties-common
# 添加Docker源
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu bionic stable"
sudo apt update
apt-cache policy docker-ce
# 下面是安装信息:
docker-ce:
Installed: (none)
Candidate: 18.06.1~ce~3-0~ubuntu
Version table:
18.06.1~ce~3-0~ubuntu 500
500 https://download.docker.com/linux/ubuntu bionic/stable amd64 Packages
18.06.0~ce~3-0~ubuntu 500
500 https://download.docker.com/linux/ubuntu bionic/stable amd64 Packages
18.03.1~ce~3-0~ubuntu 500
500 https://download.docker.com/linux/ubuntu bionic/stable amd64 Packages
# 正式安装
sudo apt install docker-ce
# 查看运行状态
sudo systemctl status docker
基本使用
docker run -i -t IMAGE /bin/bash # 启动交互式容器
docker inspect NAME # 查看详细信息?
docker run --name=xxx -it IMAGE /bin/bash # 以xxx为名字运行
# CTRL + P CTRL + Q => 后台运行。run -d 守护态运行
docker attach 容器名 # 恢复到后台容器,更建议使用 docker exec?
# 查看守护进程
ps -ef|grep docker
sudo status docker
docker top
docker exec [-d][-i][-t] nginx # 为运行中的容器启动新进程
docker logs
docker images #列出本地镜像
docker start CONTAINER #启动一个或多少已经被停止的容器
docker stop / kill CONTAINER #停止一个运行中的容器
docker restart CONTAINER #重启容器
docker rm CONTAINER #删除容器 -f 强制删除
docker rmi IMAGE #删除镜像
docker rmi $(docker images -q ubuntu) # 删除Ubuntu所有镜像
sudo systemctl daemon-reload #reload daemon.json
sudo systemctl restart docker #重启docker
docker info # 查看信息
docker diff 容器名 # 查看改动信息
# 端口映射
docker run -p 80 -it # -i 标准输入保持打开
docker run -p 8080:80 -it # -t 为docker分配一个伪终端(pseudo-tty),并绑定到容器的标准输入
docker run -p 0.0.0.0:80 -it
# 容器快照?
# 导出容器
docker export ID > ubuntu.zip
# 导入容器
cat ubuntu.zip | docker import - test/ubuntu:v1.0
# 通过URL导入
docker import http://xxx example/imagesrepo
# 数据卷
docker volume create xxx
docker run -it -v ~/datavolume:/data:ro ubuntu /bin/bash # ro设置只读权限
# 数据卷容器
docker run -it --name dv --volumes-from dvt4 ubuntu /bin/bash
Nginx 部署流程
# 创建映射80端口的交互式容器
docker run -p 8080:80 --name web -it ubuntu /bin/bash
# 安装Nginx
apt update
apt install - y nginx
# 安装文本编辑器 vim
apt install -y vim
# 创建静态页面
cd /var/www/html
touch index.html
echo 'Hello, Docker!
' > index.html
# 修改Nginx配置文件
whereis nginx # 找到安装目录
vim /etc/nginx/sites-enabled/default # 修改 root 目录
# 运行Nginx
nginx
# 验证网站访问
curl IP:port # ip 可用宿主机的IP加映射端口,也可以用 docker inspect web 查看真实容器IP
# 停止容器
docker stop web
# 启动
docker start -i web # 此时会发现,nginx已经停止
docker exec web nginx
# 如果之前没有指定端口时,重新启动时 port 将发生变化
Docker也遵守Linux命令的格式
docker [option] [command] [arguments]
docker search ubuntu # 查找镜像
docker pull name # 下载image
docker push # 推送镜像
构建镜像
# 通过容器构建
docker commit [选项] <容器ID或容器名> [<仓库名>[:<标签>]]
docker commit \
--author "Tao Wang " \
--message "修改了默认网页" \
webserver \
nginx:v2
# !慎用 docker commit
# 使用dockerfile构建镜像 —— 包括一系列命令的文件,类似shell脚本?
dockerfile编写语法
# 注释
docker build # 构建镜像
配置 Docker 加速器
curl -sSL https://get.daocloud.io/daotools/set_mirror.sh | sh -s http://f1361db2.m.daocloud.io
sudo systemctl restart docker.service # 重启 Docker 生效
docker info
# 包含以下信息,加速器配置成功
Registry Mirrors:
http://f1361db2.m.daocloud.io/
Docker不使用sudo
将用户添加到 docker 用户组
sudo usermod -aG docker $USER # 先试这个
cat /etc/group | grep docker # 查找 docker 组,确认其是否存在
groups # 列出自己的用户组,确认自己在不在 docker 组中
# 如果 docker 组不存在,则添加之:
sudo groupadd docker
# 将当前用户添加到 docker 组
sudo gpasswd -a ${USER} docker
# 重启服务
sudo service docker restart
# 切换一下用户组(刷新缓存)
newgrp - docker;
newgrp - `groups ${USER} | cut -d' ' -f1`; # TODO:必须逐行执行,不知道为什么,批量执行时第二条不会生效
# 或者,注销并重新登录
pkill X
sqli-labs Docker
zsh 配置
基本安装
echo $SHELL 查看当前shell环境
cat /etc/shells 查看系统已有哪些shell
sudo apt install zsh 安装zsh
chsh -s $(which zsh) 将默认shell改为zsh
wget https://github.com/robbyrussell/oh-my-zsh/raw/master/tools/install.sh -O - | sh 安装oh-my-zsh
~/.oh-my-zsh/themes 已有主题目录(最爱:agnoster)
~/.oh-my-zsh/pluglins 已有插件目录,如果自己下载的话,clone到这个目录
source ~/.zshrc 刷新配置文件
常用插件:
z, rails, git, colored-man-pages
zsh-syntax-highlighting
git clone https://github.com/zsh-users/zsh-syntax-highlighting 注意clone到plugins目录
zsh-autosuggestions
git clone https://github.com/zsh-users/zsh-autosuggestions
小技巧:
用 / 代替 cd /
用 .. 代替 cd ..
用 …. 代替 cd ../..
用 ~ 代替 cd ~
take fold_name: 建立fold_name的文件夹并且切换进去
x: 使用 x 代替 tar bz2 gz zip 等等一系列的命令
Powerline fonts
git clone https://github.com/powerline/fonts.git
cd fonts
./install.sh
或者直接 sudo apt-get install fonts-powerline
然后重启终端,其他的啥也不用干
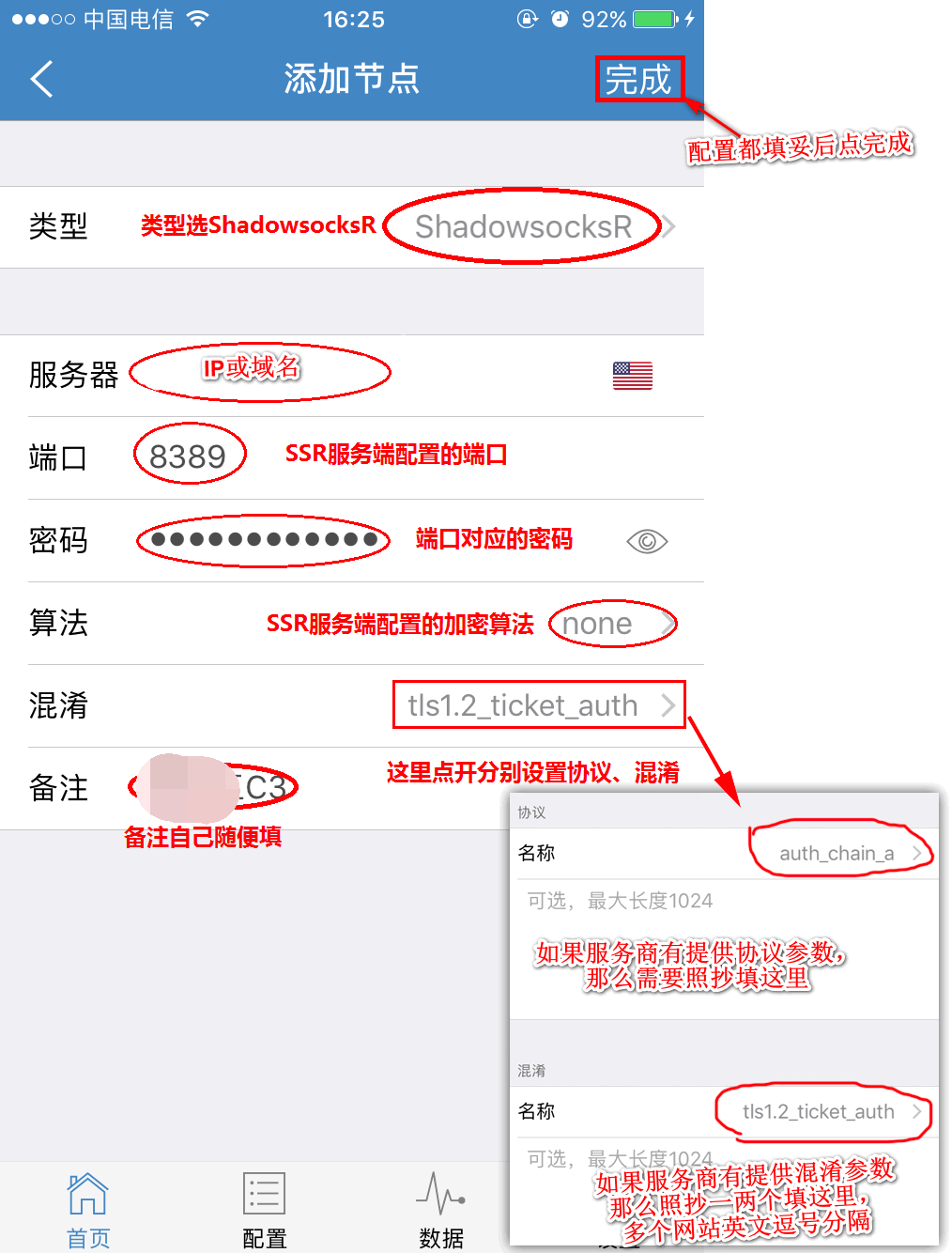
SSR 安装
wget -N --no-check-certificate https://raw.githubusercontent.com/ToyoDAdoubi/doubi/master/ssr.sh
sudo chmod +x ssr.sh
sudo bash ssr.sh
iOS 端可以从pp助手安装 Shadowrocket(pp正版)
最重要的一点,配置时类型要选择 ShadowsocksR
Markdown 笔记
链接
这就是谷歌的链接
表格
基本形式
| First Header | Second Header | Third Header |
|---|---|---|
| Content Cell | Content Cell | Content Cell |
| Content Cell | Content Cell | Content Cell |
左、右对齐,居中
| First Header | Second Header | Third Header |
|---|---|---|
| Left | Center | Right |
| Left | Center | Right |
流程图
时序图
甘特图
待补充
标记 ``
这就是标记
插图
基本格式:

Alt text:图片的Alt标签,用来描述图片的关键词,可不写。
最初的本意是当图片因为某种原因不能被显示时而出现的替代文字,后来又被用于SEO,
可以方便搜索引擎根据Alt text里面的关键词搜索到图片。
图片链接:可以是图片的本地地址或网址。"optional title":鼠标悬置于图片上会出现的标题文字,可不写。
插入本地图片

支持绝对路径和相对路径
- 缺点:不灵活不好分享,本地图片的路径更改或丢失都会造成markdown文件调不出图
Markdown 插入在线图片

- 缺点:将图片存在网络服务器上,非常依赖网络
把图片存入文件 Markdown
![avatar][base64str]
[base64str]:data:image/png;base64,iVBORw0......
base64的图片编码如何得来?
1.用python将图片转化为base64字符串:
import base64
f = open('723.png','rb') # 二进制方式打开图文件
ls_f = base64.b64encode(f.read()) # 读取文件内容,转换为base64编码
f.close()
print(ls_f)
2.base64字符串转化为图片
import base64
bs = 'iVBORw0KGgoAAAANSUhEUg....' # 太长了省略
imgdata = base64.b64decode(bs)
file = open('2.jpg','wb')
file.write(imgdata)
file.close()
SQL 笔记
基本概念:
-
SQL 语句:Structured Query Language. DBMS 用来和数据库打交道的标准语言。不区分大小写。
-
Database:
按照数据结构来组织、存储和管理数据的仓库。解决的问题:持久化存储,优化读写,保证数据的有效性。
三种模型:
- 层次模型。看起来就像一棵树。
- 网状模型。看其他就像一张图。
- 关系模型。看起来就像一张Excel。关系型数据库是建立在关系模型基础上的数据库,借助集合代数等数学概念和方法来处理数据库中的数据。
分类:文档型(SQLite),轻巧,省电,效率低;服务型(MySQL),性能强;
数据库设计:
- 三范式:列不可拆分,唯一标识,引用主键
- 关系及存储:1对1,1对多,多对多
-
每一行称为
记录(Record),记录的是一个逻辑意义上的数据。 -
每一列称为
字段(Column),同一个表的每一行记录都拥有相同的若干字段。字段定义了数据类型,以及是否允许为 NULL,注意 NULL 表示字段数据不存在,并非为 0。
不允许为NULL可以简化查询条件,加快查询速度,也利于应用程序读取数据后无需判断是否为NULL。
-
关系表中任意两条记录不能重复,不能重复不是指两条记录不完全相同,而是指能够通过某个字段唯一确定一条记录,这个字段被称为
主键。主键选取原则:不使用任何业务相关的字段作为主键。
一般把主键字段命名为
id,常见id字段类型有自增整数类型、全局唯一 GUID 类型。记录一旦插入表中,主键最好不要修改,否则会造成一系列的影响。
-
关系数据库允许通过多个字段唯一标识记录,即两个或更多字段都设置为主键,这种主键被称为
联合主键。作为联合主键的字段中,只要不出现全部相同字段就行。
-
外键:
外键并不是通过列名实现的,而是通过定义外键约束实现的:
ALTER TABLE students ADD CONSTRAINT fk_class_id FOREIGN KEY (class_id) REFERENCES classes (id);删除一个外键约束
ALTER TABLE students DROP CONSTRAINT fk_class_id;注意:删除外键约束并没有删除外键这一列。删除列是通过
DROP COLUMN ...实现的。 -
索引
-
Mysql:关系型数据库管理系统(DBMS)之一,开源。默认端口:3306
查询数据
-
基本查询:
SELECT * FROM <表名>; -- 查询表的所有数据,* 表示所有列 SELECT 100+200; -- 直接返回计算结果,可以执行 SELECT 1; 来测试数据库连接 -
条件查询
SELECT * FROM <表名> WHERE score >= 80; -- where 后接条件语句 -- 使用 AND OR NOT,即与、或、非,优先级:NOT > AND > OR = > >= < <= <> -- 等于 大于 大于或等于 小于 小于或等于 不等 LIKE -- name LIKE 'ab%' name LIKE '%bc%' %表示任意字符,例如'ab%'将匹配'ab','abc','abcd' -
投影查询:查询指定列
SELECT id, score, name FROM students; -- 还可以给列起别名 SELECT 列1 别名1, 列2 别名2, 列3 别名3 FROM ... -
排序
SELECT gender, score FROM students ORDER BY score; -- 按score从低到高(ASC被省略) SELECT name, gender, score FROM students ORDER BY score DESC; -- 高到低 ORDER BY score DESC, gender; -- score相同再按gender排序 -
分页查询
SELECT id, name, gender, score FROM students ORDER BY score DESC LIMIT 3 OFFSET 0; -- 每页三条记录,最多取三条,OFFSET 为 3 则跳过前三条 --OFFSET超过了查询的最大数量并不会报错,而是得到一个空的结果集 SELECT * FROM users limit 0, 10 -- 1,10 -
聚合查询
SELECT COUNT(*) FROM students; -- 查询所有列的行数 SELECT COUNT(*) boys FROM students WHERE gender = 'M'; -- 搭配条件语句,别名为 boys SUM AVG MAX MIN --某列的和,该列必须为数值类型 某列的平均值,该列必须为数值类型 某列的最大值 某列的最小值 SELECT COUNT(*) num FROM students GROUP BY class_id; -- 按 class_id 分组,返回三行数据 SELECT class_id, COUNT(*) num FROM students GROUP BY class_id; -- 增加 class_id 列 SELECT class_id, gender, COUNT(*) num FROM students GROUP BY class_id, gender; -- 按 class_id, gender 分组如果聚合查询的
WHERE条件没有匹配到任何行,COUNT()会返回0,而MAX()、MIN()、MAX()和MIN()会返回NULL -
多表查询
SELECT * FROM FROM <表1> <表2>; -- 返回两表的笛卡尔积表 SELECT students.id sid, students.name, students.gender, students.score, classes.id cid, classes.name cname FROM students, classes; -- 增加条件 SELECT s.id sid, s.name, s.gender, s.score, c.id cid, c.name cname FROM students s, classes c WHERE s.gender = 'M' AND c.id = 1; -
连接查询
连接查询是另一种类型的多表查询。连接查询对多个表进行JOIN运算,简单地说,就是先确定一个主表作为结果集,然后,把其他表的行有选择性地“连接”在主表结果集上。
修改数据
-
INSERT
INSERT INTO <表名> (字段1, 字段2, ...) VALUES (值1, 值2, ...); INSERT INTO students (class_id, name, gender, score) VALUES (2, '大牛', 'M', 80); --字段顺序不必和数据库表的字段顺序一致,但值的顺序必须和字段顺序一致 --如果一个字段有默认值,那么在INSERT语句中也可以不出现 -
UPDATE
UPDATE <表名> SET 字段1=值1, 字段2=值2, ... WHERE ...; UPDATE students SET name='大牛', score=66 WHERE id=1; UPDATE students SET name='小牛', score=77 WHERE id>=5 AND id<=7; UPDATE students SET score=score+10 WHERE score<80; UPDATE students SET score=100 WHERE id=999; --要特别小心的是,UPDATE语句可以没有WHERE条件 UPDATE students SET score=60; --这时,整个表的所有记录都会被更新。所以,在执行UPDATE语句时要非常小心,最好先用SELECT语句来测试WHERE条件是否筛选出了期望的记录集,然后再用UPDATE更新 -
DELETE
DELETE FROM <表名> WHERE ...; DELETE FROM students WHERE id=1; DELETE FROM students WHERE id>=5 AND id<=7; --和UPDATE类似,不带WHERE条件的DELETE语句会删除整个表的数据
事务
在执行SQL语句的时候,某些业务要求,一系列操作必须全部执行,而不能仅执行一部分。例如,一个转账操作:
-- 从id=1的账户给id=2的账户转账100元
-- 第一步:将id=1的A账户余额减去100
UPDATE accounts SET balance = balance - 100 WHERE id = 1;
-- 第二步:将id=2的B账户余额加上100
UPDATE accounts SET balance = balance + 100 WHERE id = 2;
这两条SQL语句必须全部执行,或者,由于某些原因,如果第一条语句成功,第二条语句失败,就必须全部撤销。
这种把多条语句作为一个整体进行操作的功能,被称为数据库事务。数据库事务可以确保该事务范围内的所有操作都可以全部成功或者全部失败。如果事务失败,那么效果就和没有执行这些SQL一样,不会对数据库数据有任何改动。
RDBMS的特点:
- 数据以表格的形式出现
- 每行为各种记录名称
- 每列为记录名称所对应的数据域
- 许多的行和列组成一张表单
- 若干的表单组成database
MySQL 笔记
常用命令
# 登录
mysql -user root -password xxxx
mysql -u root -p xxxx
mysql -uroot -pxxxx
ps -ef | grep mysqld # 检查是否启动
CREATE DATABASE test; # 创建数据库
DROP DATABASE test; # 删除数据库
USE database_name; # 选择要操作的数据库,以后所有Mysql命令都只针对该数据库
SHOW DATABASES; # 列出 MySQL 数据库管理系统的数据库列表
SHOW TABLES; # 显示制定数据库的所有表
CREATE TABLE students; # 创建表
DROP TABLE students; # 删除表
TRUNCATE table students; # 清空表
DESC students; # 查看表结构
SHOW CREATE TABLE students; # 查看创建表的 SQL 语句
SHOW COLUMNS FROM table_name # 显示数据表的属性
SHOW INDEX FROM table_name # 显示数据表的详细索引信息,包括主键
# 输出Mysql数据库管理系统的性能及统计信息
SHOW TABLE STATUS LIKE [FROM db_name] [LIKE 'pattern'] \G:
SHOW TABLE STATUS FROM RUNOOB; # 显示数据库 RUNOOB 中所有表的信息
SHOW TABLE STATUS from RUNOOB LIKE 'runoob%'; # 表名以runoob开头的表的信息
SHOW TABLE STATUS from RUNOOB LIKE 'runoob%'\G; # 加上 \G,查询结果按列打印
MongoDB 笔记
参考
基本概念
数据库MongoDB的单个实例可以容纳多个独立的数据库,比如一个学生管理系统就可以对应一个数据库实例。集合数据库是由集合组成的,一个集合用来表示一个实体,如学生集合。文档集合是由文档组成的,一个文档表示一条记录,比如一位同学张三就是一个文档
常用命令
# 服务端启动
mkdir data # 新建目录
mongod --dbpath='./data' # 指定数据库路径
(waiting for connections on port 27017就表示启动成功)
--port 指定服务端口号,默认端口27017
--logpath 指定MongoDB日志文件,注意是指定文件不是目录
--logappend 使用追加的方式写日志
--dbpath 指定数据库路径
--directoryperdb 设置每个数据库将被保存在一个单独的目录
# 客户端启动
mongo (--host 127.0.0.1)
# 数据库操作
show dbs # 显示所有数据库
use school # 选择数据库school
db / db.getName() # 查看当前使用的数据库
db.dropDatabase() # 删除数据库
# 集合操作
db.school.help() # 查看帮助文档
show collections # 查看数据库下的集合
db.createCollection(collection_Name) # 创建一个集合
db.collection_Name.insert(document) # 创建集合并插入文档
# 文档操作
db.collection_name.insert(document) # insert
db.collection_name.save(document) # save
# 以后再看上面那个链接
Git
Git 提示fatal: remote origin already exists
git remote rm orign
git remote add origin https://github.com/wywwzjj/Note.git
# 如果还不行,手动修改gitconfig
vi .git/config
# 把 [remote “origin”] 那一行删掉就好了
Create new repo
echo "# Note" >> README.md
git init
git add README.md
git commit -m "first commit"
git remote add origin https://github.com/wywwzjj/Note.git
git push -u origin master
Push an existing repository
git remote add origin https://github.com/wywwzjj/Note.git
git push -u origin master
实战:
git remote add origin https://github.com/yourgithubID/gitRepo.git #建立远程仓库
git checkout -b first-step
git add .
git status
git commit -m " "
git checkout master
git merge first-step
git push
cap production deploy
常用的GitHub代码
git pull origin master # 从云端获得最新版本
git clone # 本地如果无远程代码,先做这步,不然就忽略
git status # 查看本地自己修改了多少文件
git add . # 添加远程不存在的git文件
git add -A # 把项目中的所有文件都放到仓库
git commit -m "commit-info" # 提交修改
git push origin master # 更新到远程服务器上
git rm # 移除文件
git log # 查看提交历史
删除操作
git pull origin master # 将远程仓库里面的项目拉下来
dir # 查看有哪些文件夹
git rm -r --cached target # 删除target文件夹
git commit -m '删除了target' # 提交,添加操作说明
git push -u origin master # 将本次更改更新到github项目上去
误删撤回(未提交时)
git checkout -f // 强制撤销
配置
首先在本地创建ssh key;
ssh-keygen -t rsa -C "[email protected]"
# 然后一路回车
cat ~/.ssh/id_rsa.pub # 复制里面的key
进入 GitHub 上的 Account Settings(账户配置),左边选择SSH and GPG keys,粘贴 key。
ssh -T [email protected] # 验证是否成功
如果是第一次的会提示是否continue,输入yes就会看到:You’ve successfully authenticated, but GitHub does not provide shell access 。这就表示已成功连上github。
接下来我们要做的就是把本地仓库传到github上去,在此之前还需要设置username和email,因为github每次commit都会记录他们。
git config --global user.name "your name"
git config --global user.email "[email protected]"
git config --global credential.helper store # 避免 git push 时重复输密码
进入要上传的仓库,右键git bash,添加远程地址:
git remote add origin [email protected]:yourName/yourRepo.git
后面的yourName和yourRepo表示你再github的用户名和刚才新建的仓库,加完之后进入.git,打开config,这里会多出一个remote "origin"内容,这就是刚才添加的远程地址,也可以直接修改config来配置远程地址。
创建新文件夹,打开,然后执行 git init 以创建新的 git 仓库。
检出仓库
执行如下命令以创建一个本地仓库的克隆版本:
git clone /path/to/repository
如果是远端服务器上的仓库,你的命令会是这个样子:
git clone username@host:/path/to/repository
工作流
你的本地仓库由 git 维护的三棵"树"组成。第一个是你的 工作目录,它持有实际文件;第二个是 暂存区(Index),它像个缓存区域,临时保存你的改动;最后是 HEAD,它指向你最后一次提交的结果。
你可以提出更改(把它们添加到暂存区),使用如下命令:
git add <filename>
git add *
这是 git 基本工作流程的第一步;使用如下命令以实际提交改动:
git commit -m "代码提交信息"
现在,你的改动已经提交到了 HEAD,但是还没到你的远端仓库。 推送改动 你的改动现在已经在本地仓库的 HEAD 中了。执行如下命令以将这些改动提交到远端仓库:
git push origin master
可以把 master 换成你想要推送的任何分支。
如果你还没有克隆现有仓库,并欲将你的仓库连接到某个远程服务器,你可以使用如下命令添加:
git remote add origin <server>
如此你就能够将你的改动推送到所添加的服务器上去了。
分支
分支是用来将特性开发绝缘开来的。在你创建仓库的时候,master 是"默认的"分支。在其他分支上进行开发,完成后再将它们合并到主分支上。
创建一个叫做"feature_x"的分支,并切换过去:
git checkout -b feature_x
切换回主分支:
git checkout master
合并到主分支:
git merge feature_x
再把新建的分支删掉:
git branch -d feature_x
除非你将分支推送到远端仓库,不然该分支就是 不为他人所见的:
git push origin <branch>
更新与合并 要更新你的本地仓库至最新改动,执行:
git pull
以在你的工作目录中 获取(fetch) 并 合并(merge) 远端的改动。 要合并其他分支到你的当前分支(例如 master),执行:
git merge <branch>
在这两种情况下,git 都会尝试去自动合并改动。遗憾的是,这可能并非每次都成功,并可能出现冲突(conflicts)。 这时候就
需要你修改这些文件来手动合并这些冲突(conflicts)。改完之后,你需要执行如下命令以将它们标记为合并成功:
git add <filename>
在合并改动之前,你可以使用如下命令预览差异:
git diff <source_branch> <target_branch>
标签
为软件发布创建标签是推荐的。这个概念早已存在,在 SVN 中也有。你可以执行如下命令创建一个叫做 1.0.0 的标签:
git tag 1.0.0 1b2e1d63ff
1b2e1d63ff 是你想要标记的提交 ID 的前 10 位字符。可以使用下列命令获取提交 ID:
git log
你也可以使用少一点的提交 ID 前几位,只要它的指向具有唯一性。
替换本地改动 假如你操作失误(当然,这最好永远不要发生),你可以使用如下命令替换掉本地改动:
git checkout -- <filename>
此命令会使用 HEAD 中的最新内容替换掉你的工作目录中的文件。已添加到暂存区的改动以及新文件都不会受到影响。
假如你想丢弃你在本地的所有改动与提交,可以到服务器上获取最新的版本历史,并将你本地主分支指向它:
git fetch origin
git reset --hard origin/master
实用小贴士 内建的图形化 git:
gitk
彩色的 git 输出:
git config color.ui true
显示历史记录时,每个提交的信息只显示一行:
git config format.pretty oneline
交互式添加文件到暂存区:
git add -i
Linux 笔记
常用命令
- netcat
- ssh
ssh-keygen # 默认在当前用户目录下创建.ssh文件夹:公钥 id_rsa.pub 私钥 id_rsa
ssh -i Key user@host # 用私钥登陆,Key需要改权限 600
ssh user@host
与 scp 共同的参数
`-P`:数据传输默认端口,默认是22
`-r`:递归拷贝整个目录
`-i`:指定密钥文件,参数直接传递给ssh使用
`-l`:限定网速,以Kbit/s为单位
`-C`:允许压缩
`-1,-2`:强制scp命令使用ssh1或者ssh2协议
`-4,-6`:使用ipv4或者ipv6寻址
-
scp
基于 ssh 登录进行安全的远程文件拷贝命令
scp config/master.key [email protected]:/home/config # 发送给远程机
# 本地发给远程
scp file user@host:folder # 单个文件
scp -r folder user@host:folder # 整个目录 `-r`:递归拷贝整个目录
# 远程复制到本地
scp -r -i privateKey root@IP:remote_folder local_folder
`-i`:指定密钥文件,参数直接传递给ssh使用
- apt
dpkg --list # 已装软件
sudo apt-get remove <programname> # 只卸载软件,保留配置文件和数据
sudo apt-get purge / apt-get --purge remove # 完全卸载干净
- tar
tar xvf filename # 解压
tar cvf filename # 打包
- sftp
SFTP,即 SSH 文件传输协议,利用安全的连接传输文件,还可遍历本地和远程系上的文件系统
ssh username@remote_hostname_or_IP
# 成功后提示符将变为 >
help / ? # 打开帮助
Available commands:
bye Quit sftp
cd path Change remote directory to 'path'
chgrp grp path Change group of file 'path' to 'grp'
chmod mode path Change permissions of file 'path' to 'mode'
chown own path Change owner of file 'path' to 'own'
df [-hi] [path] Display statistics for current directory or
filesystem containing 'path'
exit Quit sftp
get [-Ppr] remote [local] Download file
help Display this help text
lcd path Change local directory to 'path'
# 在命令前加一个 'l',即在本地操作
lls / lpwd / lcd
get remote_file_name # 远程下载
get remote_file_name local_name_file
get -r directory_name # 递归下载文件夹
put local_file_name # 上传
put -r directory_name
环境配置
-
centos 初始配
网络部分
新安装Centos 7,执行
dhclient,系统会从dhcp服务器获取到IP地址。执行
ip add命令查看网卡信息,完整命令为ip address。重启DHCP服务的命令为
dhclient -r1、打开配置文件
vi /etc/sysconfig/network-script/ifcfg-eth02、修改配置文件
(1)动态获取IP配置(可选1):
ONBOOT=yes MM_Controlled=no BOOTPROTO=dhcp(2)设置固定IP配置(可选2):
ONBOOT=yes MM_Controlled=no BOOTPROTO=static IPADDR=192.168.1.33 BROADCAST=192.168.1.255 NETMASK=255.255.255.0 GATEWAY=192.168.1.1 DNS1=192.168.1.1 DNS2=192.168.1.23、重启网卡
systemctl restart network附(网络配置文件eth0配置项说明):
TYPE=Ethernet #网卡类型 DEVICE=eth0 #网卡接口名称 ONBOOT=yes #系统启动时是否自动加载 BOOTPROTO=static #启用地址协议 --static:静态协议 --bootp协议 --dhcp协议 IPADDR=192.168.1.11 #网卡IP地址 NETMASK=255.255.255.0 #网卡网络地址 GATEWAY=192.168.1.1 #网卡网关地址 DNS1=10.203.104.41 #网卡DNS地址 HWADDR=00:0C:29:13:5D:74 #网卡设备MAC地址 BROADCAST=192.168.1.255 #网卡广播地址vmtools
教程链接
# 卸载 usr/bin/vmware-uninstall-tools.pl rm -rvf /usr/lib/vmware-tools -
visudo
# 不输密码 user_name ALL=(ALL) NOPASSWD: ALL # group user_name ALL=(ALL) NOPASSWD: ALL %admin ALL=(ALL) NOPASSWD: ALL -
py3
# Anaconda 安装时选择添加到环境变量 # 修改包管理镜像为国内源 conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ conda config --set show_channel_urls yes conda upgrade --all # 更新所有库 conda install numpy scipy pandas # 安装库 # 配置 pycharm 时选择 System py 解释器 # 直接装Python sudo apt-get install -y python3-dev build-essential libssl-dev libffi-dev libxml2 libxml2-dev libxslt1-dev zlib1g-dev libcurl4-openssl-dev sudo apt-get install -y python3 sudo apt-get install -y python3-pip -
Chrome
wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb sudo dpkg -i google-chrome-stable_current_amd64.deb; sudo apt-get -fy install -
ChromeDriver
# 一定要看文档选择合适的版本呀......不然怀疑人生 # https://sites.google.com/a/chromium.org/chromedriver/downloads sudo apt-get install unzip wget -N http://chromedriver.storage.googleapis.com/2.26/chromedriver_linux64.zip unzip chromedriver_linux64.zip chmod +x chromedriver sudo mv -f chromedriver /usr/local/share/chromedriver sudo ln -s /usr/local/share/chromedriver /usr/local/bin/chromedriver sudo ln -s /usr/local/share/chromedriver /usr/bin/chromedriver -
MongoDB 详细
# Installing MongoDB sudo apt update sudo apt install -y mongodb # Checking the Service and Database sudo systemctl status mongodb ● mongodb.service - An object/document-oriented database Loaded: loaded (/lib/systemd/system/mongodb.service; enabled; vendor preset: enabled) Active: active (running) since Sat 2018-05-26 07:48:04 UTC; 2min 17s ago Docs: man:mongod(1) Main PID: 2312 (mongod) Tasks: 23 (limit: 1153) CGroup: /system.slice/mongodb.service └─2312 /usr/bin/mongod --unixSocketPrefix=/run/mongodb --config /etc/mongodb.conf mongo --eval 'db.runCommand({ connectionStatus: 1 })' # version, address and port # Managing the MongoDB Service sudo systemctl status/stop/start/restart mongodb sudo systemctl disable/enable mongodb # automatic startup
命令行
终端下光标移动:
CTRL + a 跳至行首
CTRL + b / f 前后移动
CTRL + u 删掉光标前的所有字符
CTRL + k 删掉光标后的所有字符
CTRL + h 往前删一个
CTRL + d 往后删一个
CTRL + x CTRL + e 进入编辑器编辑当前命令
CTRL + p / n 切换历史命令
VIM
Python 笔记
易错
functions decision control,
loops and booleans,
simulation and design,
classes,
data collection,
object-oriented design algorithms
单词
- mutable 易变的
- invoke v. 唤起,调用
- shuffle n. v. 搅乱,洗牌
list
-
list1 = [1, 3]
list2 = list1
list1[0] = 4list2 = [4, 3] 相当于引用?
-
def f(i, values = []):
values.append(i)
return valuesf(1)
f(2)
v = f(3)
print(v)v = [1, 2, 3]
-
random.shuffle(list1) 打乱顺序
-
list1 = [11, 2, 23] and list2 = [2, 11, 23], list1 != list2
-
insert(index, data) index 从0开始
-
pop() 删除末尾元素 pop(index) 删除索引为 index 元素
-
remove() 删除指定元素
-
append() 在末尾追加元素
-
count() 输出元素出现次数
-
sort() 默认从小到大排序
-
reverse() 反转
-
extend() 在列表末尾一次性追加另一个序列中的多个值
-
If a key is not in the list, the binarySearch function returns -(insertion point + 1)
tuple
- 一旦初始化就不能改变,string 也是?
- 上面的初始化后不能改变也是有条件的, Python tuple is immutable if every element in the tuple is immutable. 比如 tuple 中有个 list,也是可以变得
- 没有append,insert这些方法
- 定义一个空元组(),
- 定义一个元素的元组需要用(1,),以此与单纯的小括号区分
- The elements in a tuple or list are ordered! => 元素相对顺序确定,不是已排好序,能不能直接 [] 来访问
切片
- [a:b] => [a, b) 从 a 开始,不包括 b
- a = 0 是可省略,b 为最后一个也可省略
- 为负数时意味着倒数
- [a:\b:c] c 为步长 ,L[::-1] 逆转
- tuple也能切片,切出来仍然是一个tuple
- L[1:-1] => 第一个到倒数第二个
- L = (1,2) => 2*L = (1, 2, 1, 2)
dict
- {} 创建空 dict,{1,2} 是 set,d = {40:“john”, 45:“peter”} 这样也是正确的
- 直接 d[‘xxx’] ,如果 xxx 不存在就会报错:KeyError(事先 in 判断一下),此时可以用 get() ,不存在就会返回 none
- 使用 pop() 删除 key,其对应的 value 也会被删掉
- dict 无 delete 方法,可以 del d[“john”],不能 del d(“john”:40)
- dict 之间无法进行 > 大小比较,但是可以判断是否相等
set
- set() 创建空 set
- list(“abac”) => [‘a’, ‘b’, ‘a’, ‘c’]
- tuple(“abac”) => (‘a’, ‘b’, ‘a’, ‘c’)
- set(“abac”) => {‘a’, ‘b’, ‘c’} 重复元素在set中自动被过滤
- add() 添加元素,remove() 删除元素
- 两个 set 进行 < , >比较,比的是 集合的包含关系
- set 中的元素不能通过 [] 索引来获取
- s1.issubset(s2) => s1 是 s2 的子集
- s1 ^ s2 => (s1-s2) | (s2-s1)
- 2 * s1 是非法的
- 不能 s1 + s2,取并集只能 |
file IO
- 如果文件不存在,
open()函数就会抛出一个IOError的错误,并且给出错误码和详细的信息告诉你文件不存在 - read(size) 每次读取size个字节内容,为写size则读取全部内容
- readline() 每次读取一行内容,读取下一行
- readlines() 一次读取所有内容并返回 list
- os.path.exists(’/etc/passwd’) 判断是否存在
- dialog
小诗
s = """Gur Mra bs Clguba, ol Gvz Crgref
Ornhgvshy vf orggre guna htyl.
Rkcyvpvg vf orggre guna vzcyvpvg.
Fvzcyr vf orggre guna pbzcyrk.
Pbzcyrk vf orggre guna pbzcygrq.
Syng vf orggre guna arfgrq.
Fcnefr vf orggre guna qrafr.
Ernqnovyvgl pbhagf.
Fcrpvny pnfrf nera'g fcrpvny rabhtu gb oernx gur ehyrf.
Nygubhtu cenpgyvgl orngf chevgl.
Reebef fubhyq arire cnff fvyragyl.
Hayrff rkcyvpvgyl fvyraprq.
Va gur snpr bs nzovthvgl, ershfr gur grzcgngvba gb thrff.
Gurer fubhyq or bar-- naq cersrenoyl bayl bar --boivbhf jnl gb qb vg.
Nygubhtu gung jnl znl abg or boivbhf ng svefg hayrff lbh'er Qhgpu.
Abj vf orggre guna arire.
Nygubhtu arire vf bsgra orggre guna *evtug* abj.
Vs gur vzcyrzragngvba vf uneq gb rkcynva, vg'f n onq vqrn.
Vs gur vzcyrzragngvba vf rnfl gb rkcynva, vg znl or n tbbq vqrn.
Anzrfcnprf ner bar ubaxvat terng vqrn -- yrg'f qb zber bs gubfr!"""
d = {}
for c in (65, 97):
for i in range(26):
d[chr(i+c)] = chr((i+13) % 26 + c)
print "".join([d.get(c, c) for c in s])
杂项
ord() # ASCII码
chr() # 对应char
isinstance(x, str) # 判断x是否是字符串?
zip() # 拉链,打包成一个个元组
a = [1, 2, 3]
b = [4, 5, 6]
zipped = zip(a, b)
zipped = [(1, 4), (2, 5), (3, 6)]
c = zip(*zipped) # 相当于解压,返回二维矩阵式
c = [(1, 2, 3), (4, 5, 6)]
all(True, True, True) # 全为真才为真(与)
any(False, True, False) # 有真即为真(或)
arr = [1, 3, 3, 5]
sum(arr) # arr元素的和
max(arr) # arr的最大值
min(arr) # arr的最小值
# 导入MySQL驱动:
>>> import mysql.connector
# 注意把password设为你的root口令:
>>> conn = mysql.connector.connect(user='root', password='password', database='test')
>>> cursor = conn.cursor()
# 创建user表:
>>> cursor.execute('create table user (id varchar(20) primary key, name varchar(20))')
# 插入一行记录,注意MySQL的占位符是%s:
>>> cursor.execute('insert into user (id, name) values (%s, %s)', ['1', 'Michael'])
>>> cursor.rowcount
1
# 提交事务:
>>> conn.commit()
>>> cursor.close()
# 运行查询:
>>> cursor = conn.cursor()
>>> cursor.execute('select * from user where id = %s', ('1',))
>>> values = cursor.fetchall()
>>> values
[('1', 'Michael')]
# 关闭Cursor和Connection:
>>> cursor.close()
True
>>> conn.close()
Tuple 与 List
# []————list
classmates = ['Michael', 'Bob', 'Tracy']
classmates.append('xiaoyu')
print(classmates[-1])
classmates.pop()
print(classmates[-1])
s = ['python', 'java', ['asp', 'php'], 'scheme']
print(len(s))
# ()————tuple
t = ('jj',) # 单个元素时加“,” 是为了消除()带来的歧义,防止解释器理解为数学上的小括号
# 一旦定义则不可变的tuple的意义为相比list更安全,所以能用tuple的地方不要用list
t = ('a','b',['A','B'])
t[2][1] = 'B'
t[2][2] = 'A'
# 此时的tuple又变长“可变”了,原因只有一个,tuple的不变说的是指向不变,而不是说元素不变
print(len(t))
length = input('请输入你的身高:')
height = input('请输入你的体重:') # input()函数直接返回的是str类型
length = int(length) # 所以需要先强制转换一下
height = int(height)
循环
names = ['Michael', 'Bob', 'Tracy']
for name in names:
print(name)
sum = 0
for x in range(101):
sum += x
print(sum)
sum = 0
n = 99
while n > 0:
sum += n
n -= 1
print(sum)
L = ['Bart', 'Lisa', 'Adam']
for l in L:
print('Hello,%s' % l)
Dist 与 Set
# dist 相当于STL中的map,采用 key—value 存储
d = {'Michael': 95, 'Bob': 75, 'Tracy': 85}
d['Michael'] = 95
# set 与 dist 类似,但不存储 value。
s = set([1, 2, 3])
add() # s.add(4)
remove() # s.remove(4)
# set 可看做数学意义上的无序和无重复元素的集合,因此,两个 set 可以做数学意义上的交、并集操作
s1 = set({1, 2, 3})
s2 = set({2, 3, 4})
s1 & s2
s1 | s2
函数
- pass————如果想定义一个什么事也不做的函数
# 比如现在没想好写函数的具体实现,就可以使用 pass 占位,使得程序先跑起来
# 没写 pass 的空函数将会报错
def nop():
pass
- isinstance()————内置了参数类型检查函数
def my_abs(x):
if not isinstance(x, (int, float)):
raise TypeError('Bad operand type')
if x >= 0:
return x
else
return -x
- 函数返回多个值(本质就是返回一个tuple)
import math
def move(x, y, step, angle = 0):
nx = x + step * math.cos(angle)
ny = y - step * math.sin(angle)
return nx, ny
nx, ny = move() # 接收多个返回值
r = move(100, 100, 60, math.pi / 6)
print(r)
(151.96152422706632, 70.0)
# 在语法上,返回一个tuple可以省略括号,而多个变量可以同时接收一个tuple,按位置赋给对应的值
# 所以函数返回的就是一个tuple,但写起来很方便
# 函数执行完毕后也没有 return 语句时,将自动 return none
- 可变参数————*
# 定义默认参数要牢记一点:默认参数必须指向不变对象!并且放在后面
# 定义可变参数和定义一个list或tuple参数相比,仅仅在参数前面加了一个*号。
# 在函数内部,参数numbers接收到的是一个tuple,因此,函数代码完全不变。
# 但是,调用该函数时,可以传入任意个参数,包括0个参数:
def calc(*numbers):
sum = 0
for n in numbers:
sum += n * n
return sum
calc(1,2,3)
calc(3,4,2,25,4)
# 用起来是不是很舒服呀?
# 相当于省略了创建 tuple、list 的过程,一步到位
# 如果已经有一个list或tuple,要调用可变参数怎么办,可以这样做
nums = [1,3,5]
calc(nums[0], nums[1], nums[2])
# 显然如此处理太繁琐,办法来了:
nums = [1,3,5]
calc(*nums)
- 关键字参数————**
# 关键字参数允许你传入0个或任意个含参数名的参数,这些关键字在函数内部自动组装为一个 dict
def person(name, age, **kw):
print('name:', name, 'age:', age, 'other:', kw)
person('Michael', 30) # name: Michael age: 30 other: {}
person('Michael', 30,city='Beijing') # name: Michael age: 30 other: {'city': 'Beijing'}
# 关键字参数可以扩展函数的功能。比如在person函数中既可以接收必要的参数,但是,
# 如果调用者愿意提供更多的参数,我们也能收到。
# 试想,你正在做一个用户注册的功能,除了用户名和年龄是必选项,其他都是可选项,
# 利用关键字参数来定义这个函数就能满足注册的需求
extra = {'city': 'Beijing', 'job': 'Engineer'}
person('Jack', 24, **extra)
# name: Jack age: 24 other: {'city': 'Beijing', 'job': 'Engineer'}
- 命名关键字参数
- 参数组合
# 在Python中定义函数,可以用必选参数、默认参数、可变参数、关键词参数和命名关键词参数,这5中参数都可以组合使用。
# 但参数定义的顺序必须是:必选、默认、可变、命名关键字、关键字
- 递归函数
def fact(n):
if n == 1:
return 1
return fact(n-1)*n
print(fact(99))
尾递归优化
def fac(n):
return fact_iter(n, 1)
def fact_iter(num, product):
if num == 1:
return product
return fact_iter(num - 1, num * product)
# 优点:如果做了优化,栈不会增长,无论调用多少次也不会栈溢出
# 尾递归和循环是等价的,没有循环语句的编程语言只能通过尾递归实现循环
# 然而,注意是然而,Python标准的解释器没有针对尾递归做优化,任何递归函数都存在栈溢出问题
# 简单的汉诺塔
def move(n,a,b,c):
if n == 1:
print(a, '-->', c)
return
move(n-1, a, c, b)
print(a, '-->', c)
move(n-1, b, a, c)
# move(3, 'A', 'B', 'C')
切片
# 切片————[a :b],索引从a取到b(不包括b)
L = ['Michael', 'Sarah', 'Tracy', 'Bob', 'Jack']
print(L[0:3])
# 从0开始时可以省略(索引从0开始)
print(L[:3])
# 倒着取
print(L[-2:]) # 从L[-2]到结尾
# 遍历整个list或tuple
print(L[:])
L = list(range(100))
L[:10] # 前10个数
L[-10:] # 后10个数
L[10:20] # 前11~20个数
L[:10:2] # 前10个数,每两个取1个
L[::5] # 所有数,每5个取一个
# 利用切片操作,实现一个trim()函数,去除字符串首尾的空格
def trim(s):
if len(s) == 0:
return s
elif s[0] == ' ':
return trim(s[1:])
elif s[-1] == ' ':
return trim(s[:-1])
return s
# 这个思路真的很棒,谢谢原作者
迭代
# 迭代永远是取出元素本身,而非元素的索引
# 如果给定一个list或tuple,我们可以通过for循环来遍历这个结构,这种遍历叫做迭代(iteration)
例题:在迭代 ['Adam', 'Lisa', 'Bart', 'Paul'] 时,
如果我们想打印出名次 - 名字(名次从1开始),请考虑如何在迭代中打印出来。
zip()函数可以把两个list变成一个list
>>> zip([10, 20, 30], ['A', 'B', 'C'])
[(10, 'A'), (20, 'B'), (30, 'C')]
L = ['Adam', 'Lisa', 'Bart', 'Paul']
for index, name in zip(range(1, len(L)+1), L):
print index, '-', name
# Python的for循环抽象程度是要高于c的,因为Python的for循环不仅可以用在list或tuple上,
# 还可以作用在其他的迭代对象上。只要是可迭代对象,无论有无下标,均可迭代,比如dict
d = {'a': 1, 'b': 2, 'c': 3}
for key in d:
print(key)
# dict的存储不是按照 list 的方式顺序排列,每次的迭代的顺序可能不一样
# 默认情况下,dict 迭代的是 key
# 如果要迭代value
for value in d.values():
print(value)
py3中抛弃了itervalues方法
# 如果要同时迭代 key 和 value
for k, v in d.items(): # items()返回的是包含tuple的list
print('k = ', k, ', v = ', v)
# 字符串也是可迭代对象
for ch in 'ABC':
print(ch)
# 那如何判断对象是否可迭代呢?
from collections import Iterable
print(isinstance('abc', Iterable))
print(isinstance([1, 2, 3], Iterable))
print(isinstance(123, Iterable))
# 如果对list实现类似Java那样的下标循环怎么办?
# enumerate()函数来救场,它可以把list变成索引——元素对
for i, value in enumerate(['A', 'B', 'C']):
print(i, value)
for x, y in [(1, 1), (2, 4), (3, 9)]:
print(x, y)
列表生成器
# 生成[1, 2, 3, 4....]
list(range(1,11))
# 生成[1*1, 2*2, 3*3, 4*4....]
# 使用循环
L = []
for x in range(1, 11):
L.append(x * x)
# 过于繁琐
# 列表生成器一句话搞定
L = [x * x for x in range(1, 11)]
print(L)
# for循环后面还可以加上if判断
L = [x * x for x in range(1, 11) if x % 2 == 0]
# 还可以使用两层循环,生成全排列
L = [m + n for m in 'ABC' for n in 'XYZ']
print(L)
# 运用列表生成器可以写出非常简洁的代码
# 例如,列出当前目录下的所有文件和目录名
import os
L = [d for d in os.listdir('.')]
print(L)
# 将list中的所有字符串变成小写
L = ['Hello', 'World', 'IBM', 'Apple']
H = [s.lower() for s in L]
print(H)
# for循环可以同时使用多个变量,因此,列表生成器也可以使用两个变量来生成list
d = {'x': 'A', 'y': 'B', 'z': 'C' }
L = [k + '=' + v for k, v in d.items()]
print(L)
生成器(generator)
# 如果列表元素可以按照某种算法推算出来,那我们是否可以在循环的过程中不断推算出后续的元素呢?
# 这样就不必创建完整的list,从而节省大量的空间。
# 在Python中,这种一边循环一边计算的机制,称为生成器:generator
# 方法一:将列表生成器的 [] 改成 ()
L = [x * x for x in range(10)]
g = (x * x for x in range(10))
print(g)
<generator object <genexpr> at 0x00000221BDA5CC00>
# 通过next()获得生成器的下一个值
# 因为generator也是可迭代对象,那就可以直接使用 for 循环
for n in g:
print(n)
# 方法二:使用 yield
# 如果函数定义中包含了 yield 关键字,
# 那这个函数就不再是一个普通函数,
# 而是一个 generator
# 斐波那契数列
def fib(n):
i, a, b = 0, 0, 1
while i < n:
print(b)
a, b = b, a + b
i = i + 1
fib(9)
# 升级为生成器
def fib(n):
i, a, b = 0, 0, 1
while i < n:
yield b
a, b = b, a + b
i = i + 1
b = fib(9)
for i in b:
print(i)
迭代器
函数式编程
- 把计算视为函数而非指令
- 纯函数式编程:不需要变量,没有副作用,测试简单
- 支持高阶函数,代码简洁
高阶函数
将函数作为参数传入函数
map()
把函数依次作用在 list 的每个元素上,得到一个新的list并返回
[1, 2, 3, 4, 5, 6, 7, 8, 9]
# 如果把list的每个元素都平方,就可以用map()函数:
def f(x):
return x*x
print map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9])
# 结果:
[1, 4, 9, 10, 25, 36, 49, 64, 81]
reduce()
filter()
挑出符合条件的元素
sorted()
能自定义比较规则的sort()?
返回函数
闭包
嵌套定义函数,内层函数引用了外层函数的局部变量,然后返回内层函数
# 一般形式:
def g():
print 'g()...'
def f():
print 'f()...'
return g
# 闭包大法后:
def f():
print 'f()...'
def g():
print 'g()...'
return g
将g()挪到函数内部,防止其他代码调用g()
# 坑点:确保引用的局部变量在函数返回后不能变
# 希望一次返回3个函数,分别计算1X1,2X2,3X3:
def count():
fs = []
for i in range(1, 4):
def f():
return i * i
fs.append(f)
return fs
f1, f2, f3 = count()
# 结局是f1, f2, f3 全是9
# 正确写法:
def count():
fs = []
for i in range(1, 4):
def f(j):
def g():
return j * j
return g
r = f(i)
fs.append(r)
return fs
匿名函数
需要一个函数,又懒得特地声明,此时就可以用lambda表达式
arr = range(5)
print(map(lambda x: x*x, arr)) # 每个元素都平方一下
print(filter(lambda x: x%2==0, arr)) # 挑出偶数
装饰器(decorator)
不改动原函数代码,在代码运行期间动态扩展原函数功能的一种机制。
实际上,装饰器就是一个返回函数的高阶函数(接收函数 -> 包装 -> 返回新函数)
使用方法:@+函数名
# 可以极大地简化代码,避免每个函数写重复的代码
@log # 打印日志
@performance # 检测性能
@transaction # 数据库事务
@post('/register') # URL路由
def hello():
print("Hello, World!")
# 添加功能:输出函数运行耗费的时间
import time
def metric(fn):
def weapper(*args, **kwargs):
start = time.time()
res = fn(*args, **kwargs)
end = time.time()
print('%s executed in %s ms' % (fn.__name__, end - start))
return res
return weapper
@printTime
hello()
偏函数
偏函数的意义在于固定某些可变参数,相当于“减饰器”
# int() 可以把字符串转换为整数,但它还额外提供了 base参数,其默认值为10
# 如果传入 base参数,就可以做 N 进制转换
# 假设要转换大量二进制字符串,每次都传入int(x, base=2)非常麻烦,那么就可以定一个int2()
def int2(x, base=2):
return int(x, base)
# functools.partial就是帮助我们创建这样一个偏函数的,不用自己特意定义int2()
int2 = functools.partial(int, base=2)
异常处理
try:
# 可能出问题的代码
pass
except 错误类型1:
# 针对错误类型1进行处理的代码
pass
except 错误类型2:
# 针对错误类型2进行处理的代码
pass
except Exception as e:
# 未知错误
pass
else:
# 正常情况该执行的代码
pass
finally:
# 无论是否有异常,都会执行的代码
pass
# 异常的传递——当函数/方法执行出现异常,会讲异常传递给函数/方法的调用一方
若果传递到主程序,仍然没有异常处理,程序才会被终止
在开发中,可以利用异常的传递性,在主程序捕获异常
而在主函数中调用的其他函数,只要出现异常,都会传递到主函数的异常捕获中
# 主动抛出异常
1.创建一个Exception的对象
2.使用raise关键字抛出异常对象
# 样例:密码长度小于8则异常
def input_passwd():
pwd = input("请输入密码:")
if len(pwd) >= 8:
return pwd
print("主动抛出异常")
# 创建对象
ex = Exception("密码长度不够")
# 主动抛出异常
raise ex
try:
print(input_passwd())
except Exception as e:
print(e)
ACM Tricks
//{{{ #include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include Dynamic Programing
-
第一。先找到原问题和其子问题们之间的关系,写出递归形式。如此一来,便可利用递归公式,用子子问题的答案求出子问题的解;用子问题的解,求出原问题的解。
-
第二。确认可能出现的问题总共有哪些,这样才能知道要计算哪些问题,才能知道总共花多少时间、多少记忆体。
-
第三。有了递归公式之后,就必须安排一套计算的顺序。大问题的答案,总是以小问题的答案来求得的,所以,小问题的答案必须先计算,否则大问题的答案从何而来?一个好的安排,不但使程序容易编写,还可重复利用记忆体空间。
-
第四。记得先捋最小、最先被计算的问题,心算出答案,储存入表格,内建于程序中。一道递归公式必须拥有初始值,才有办法计算其他项。
-
第五。实践 D P DP DP 的程序时,会建立一个表格,在表格存入所有大小问题的答案。安排好每个问题在表格的位置,这样计算时才能知道在哪取值。切勿存取超出表格的元素,产生溢出情形,导致答案算错。计算过程当中,一旦某个问题的答案出错,就会如同多米诺骨牌效应般影响整体,造成很难除错。
分类
- 线性dp
- 背包
- 区间dp
- 数位dp
- 状压dp
- 树形dp
- 概率dp
基础
- 序列型
- 背包型
- 区间型
- 环形
- 棋盘型
- 普通多维
进阶
- 复杂多维
- 多线程
- 数位
- 期望
- 状压基础
高级
- 树形
- D P DP DP 优化
- 状压进阶
- 插头
- 博弈论
- D P DP DP 套 D P DP DP