快速入门Flink (2) —— Flink 集群搭建
写在前面: 博主是一名软件工程系大数据应用开发专业的学生,昵称来源于《爱丽丝梦游仙境》中的Alice和自己的昵称。作为一名互联网小白,
写博客一方面是为了记录自己的学习历程,一方面是希望能够帮助到很多和自己一样处于起步阶段的萌新。由于水平有限,博客中难免会有一些错误,有纰漏之处恳请各位大佬不吝赐教!个人小站:http://alices.ibilibili.xyz/ , 博客主页:https://alice.blog.csdn.net/
尽管当前水平可能不及各位大佬,但我还是希望自己能够做得更好,因为一天的生活就是一生的缩影。我希望在最美的年华,做最好的自己!
上一篇博客博主已经为大家介绍了 Flink的简介与架构体系,本篇博客,我们来学习如何搭建Flink集群。
码字不易,先赞后看!
文章目录
- 1、Flink 环境搭建
- 1.1 standalone 集群环境
- 1.1.1 准备工作
- 1.1.2 下载安装包
- 1.1.3 集群规划
- 1.1.4 步骤
- 1.1.5 具体操作
- 1.1.6 启动/停止 flink 集群
- 1.1.7 Flink 集群的重启或扩容
- 1.1.8 Standalone 集群架构
- 1.2 高可用 HA 模式
- 1.2.1 HA 架构图
- 1.2.2 集群规划
- 1.2.3 步骤
- 1.2.4 具体操作
- 1.3 yarn 集群环境
- 1.3.1 准备工作
- 1.3.2 集群规划
- 1.3.3 修改 hadoop 的配置参数
- 1.3.4 修改全局变量/etc/profile
- 1.3.5 Flink on Yarn 的运行机制
- 1.3.6 Flink on Yarn 的两种使用方式
- 1.3.6.1 第一种方式:YARN session
- 1.3.6.2 第二种方式:在 YARN 上运行一个 Flink 作业
- 小结
1、Flink 环境搭建
Flink 支持多种安装模式。
1)local( 本地) ——单机模式, 一般不使用
2)standalone ——独立模式, Flink 自带集群,开发测试环境使用
3)yarn——计算资源统一由 Hadoop YARN 管理,生产环境测试
1.1 standalone 集群环境
1.1.1 准备工作
1) jdk1.8 及以上【 配置 JAVA_HOME 环境变量】
2) ssh 免密码登录【 集群内节点之间免密登录】
1.1.2 下载安装包
https://archive.apache.org/dist/flink/flink-1.7.2/flink-1.7.2-bin-hadoop26-scal a_2.11.tgz
1.1.3 集群规划
master(JobManager)+slave/worker(TaskManager)
node01(master+slave)
node02(slave)
node03(slave)
1.1.4 步骤
1) 解压 Flink 压缩包到指定目录
2) 配置 Flink
3) 配置 Slaves 节点
4) 分发 Flink 到各个节点
5) 启动集群
6) 递交 wordcount 程序测试
7) 查看 Flink WebUI
1.1.5 具体操作
1)上传 Flink 压缩包到指定目录
2) 解压缩 flink 到 /export/servers 目录
tar -zxvf flink-1.7.2-bin-hadoop26-scala_2.11.tgz
3) 修改安装目录下 conf 文件夹内的 flink-conf.yaml 配置文件, 指定 JobManager
# 配置 Master 的机器名( IP 地址)
jobmanager.rpc.address: node01
# 配置每个 taskmanager 生成的临时文件夹
taskmanager.tmp.dirs: /export/servers/flink-1.7.2/tmp
4) 修改安装目录下 conf 文件夹内的 slave 配置文件, 指定 TaskManager
node01
node02
node03
5) 使用 vi 修改 /etc/profile 系统环境变量配置文件,添加 HADOOP_CONF_DIR 目录
export HADOOP_CONF_DIR=/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
6) 分发/etc/profile 到其他两个节点
scp -r /etc/profile node02:/etc
scp -r /etc/profile node03:/etc
7) 每个节点重新加载环境变量
source /etc/profile
8) 将配置好的 Flink 目录分发给其他的两台节点
for i in {2..3}; do scp -r flink-1.7.2/ node0$i:$PWD; done
9) 启动 Flink 集群
bin/start-cluster.sh
10) 通过 jps 查看进程信息

基础配置
# jobManager 的 IP 地址
jobmanager.rpc.address: localhost
# JobManager 的端⼝号
jobmanager.rpc.port: 6123
# JobManager JVM heap 内存⼤⼩
jobmanager.heap.size: 1024m
# TaskManager JVM heap 内存⼤⼩ taskmanager.heap.size: 1024m
# 每个 TaskManager 提供的任务 slots 数量⼤⼩ taskmanager.numberOfTaskSlots: 1
# 程序默认并⾏计算的个数
parallelism.default: 1
11) 启动 HDFS 集群
12) 在 HDFS 中创建/test/input 目录
hadoop fs -mkdir -p /test/input
13) 上传 wordcount.txt 文件到 HDFS /test/input 目录
hadoop fs -put /root/wordcount.txt /test/input
14) 并运行测试任务
[root@node01 flink-1.7.2]# bin/flink run
/export/servers/flink-1.7.2/examples/batch/WordCount.jar --input
hdfs://node01:8020/test/input/wordcount.txt --output
hdfs://node01:8020/test/output/200701
15) 浏览 Flink Web UI 界面

1.1.6 启动/停止 flink 集群
启动: ./bin/start-cluster.sh
停止: ./bin/stop-cluster.sh
1.1.7 Flink 集群的重启或扩容
启动/停止 jobmanager
如果集群中的 jobmanager 进程挂了, 执行下面命令启动
bin/jobmanager.sh start
bin/jobmanager.sh stop
启动/停止 taskmanager
添加新的 taskmanager 节点或者重启 taskmanager 节点
bin/taskmanager.sh start
bin/taskmanager.sh stop
1.1.8 Standalone 集群架构

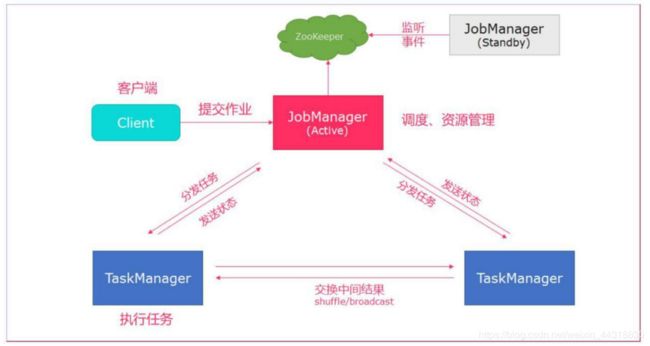
- client 客户端提交任务给 JobManager
- JobManager 负责 Flink 集群计算资源管理, 并分发任务给 TaskManager 执行
- TaskManager 定期向 JobManager 汇报状态
1.2 高可用 HA 模式
从上述架构图中, 可发现 JobManager 存在单点故障, 一旦 JobManager 出现意外, 整个集群无法工作。 所以, 为了确保集群的高可用, 需要搭建 Flink 的 HA。 ( 如果是 部署在 YARN 上, 部署 YARN 的 HA) , 我们这里演示如何搭建 Standalone 模式 HA。
1.2.1 HA 架构图
1.2.2 集群规划
master(JobManager)+slave/worker(TaskManager)
node01(master+slave)
node02(master+slave)
node03(slave)
1.2.3 步骤
1) 在 flink-conf.yaml 中添加 zookeeper 配置
2) 将配置过的 HA 的 flink-conf.yaml 分发到另外两个节点
3) 分别到另外两个节点中修改 flink-conf.yaml 中的配置
4) 在 masters 配置文件中添加多个节点
5) 分发 masters 配置文件到另外两个节点
6) 启动 zookeeper 集群
7) 启动 flink 集群
1.2.4 具体操作
1) 在 flink-conf.yaml 中添加 zookeeper 配置
#开启 HA, 使用文件系统作为快照存储
state.backend: filesystem
#默认为 none, 用于指定 checkpoint 的 data files 和 meta data 存储的目录
state.checkpoints.dir: hdfs://node01:8020/flink-checkpoints
#默认为 none, 用于指定 savepoints 的默认目录
state.savepoints.dir: hdfs://node01:8020/flink-checkpoints
#使用 zookeeper 搭建高可用
high-availability: zookeeper
# 存储 JobManager 的元数据到 HDFS,用来恢复 JobManager 所需的所有元数据
high-availability.storageDir: hdfs://node01:8020/flink/ha/
high-availability.zookeeper.quorum: node01:2181,node02:2181,node03:2181
2) 将配置过的 HA 的 flink-conf.yaml 分发到另外两个节点
[root@node01 conf]# for i in {2..3}; do scp -r /export/servers/flink-1.7.2/conf/flink-conf.yaml node0$i:$PWD; done
3) 到节点 2 中修改 flink-conf.yaml 中的配置, 将 JobManager 设置为自己节点的名称
jobmanager.rpc.address: node02
4) 在 masters 配置文件中添加多个节点
node01:8081
node02:8081
5) 分发 masters 配置文件到另外两个节点
[root@node01 servers]# for i in {2..3}; do scp -r
/export/servers/flink-1.7.2/conf/masters node0$i:$PWD; done
6) 启动 zookeeper 集群
[root@node01 servers]# /export/servers/zookeeper-3.4.5-cdh5.14.0/bin/zkServer.sh start
[root@node02 servers]# /export/servers/zookeeper-3.4.5-cdh5.14.0/bin/zkServer.sh start
[root@node03 servers]# /export/servers/zookeeper-3.4.5-cdh5.14.0/bin/zkServer.sh start
7) 启动 HDFS 集群
8) 启动 flink 集群
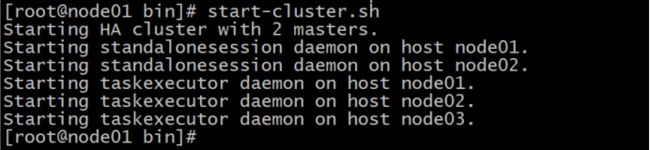
[root@node01 flink-1.7.2]# bin/start-cluster.sh
可以在linux端看见类似的开启效果
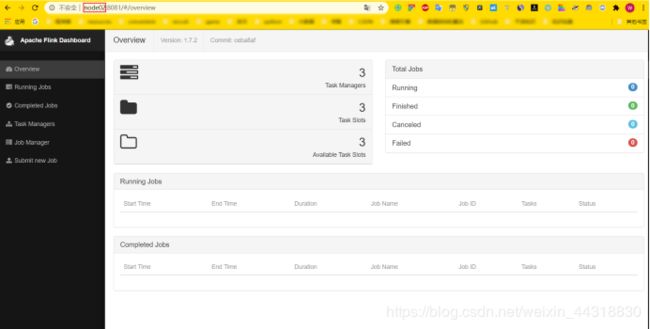
9) 分别查看两个节点的 Flink Web UI
发现当前node02为master
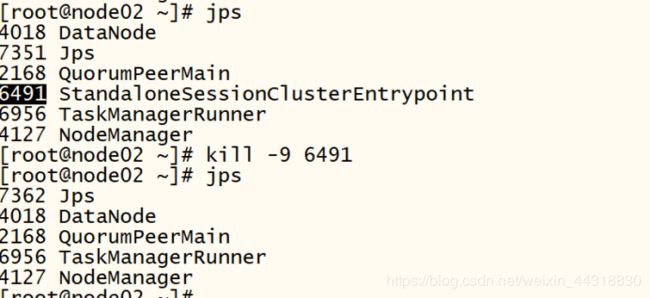
10) kill 掉一个节点, 查看另外的一个节点的 Web UI
把node02节点的JobManager 进程kill掉,查看页面,发现此时node01变成了主节点。

注意事项:
切记搭建HA,需要将第二个节点的 jobmanager.rpc.address 修改为 node02
1.3 yarn 集群环境
在一个企业中, 为了最大化的利用集群资源, 一般都会在一个集群中同时运行多种类型的 Workload。 因此 Flink 也支持在 Yarn 上面运行;
flink on yarn 的前提是: hdfs、 yarn 均启动
1.3.1 准备工作
1) jdk1.8 及以上【 配置 JAVA_HOME 环境变量】
2) ssh 免密码登录【 集群内节点之间免密登录】
3) 至少 hadoop2.2
4) 启动 hdfs & yarn
1.3.2 集群规划
master(JobManager)+slave/worker(TaskManager)
node01(master)
node02(slave)
node03(slave)
1.3.3 修改 hadoop 的配置参数
vim etc/hadoop/yarn-site.xml
添加:
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则 直接将其杀 掉,默认是 true。 在这里面我们需要关闭,因为对于 flink 使用 yarn 模式下,很容易内存超标,这个时候 yarn 会自动杀掉 job。
1.3.4 修改全局变量/etc/profile
添加:
export HADOOP_CONF_DIR=/export/servers/hadoop/etc/Hadoop
YARN_CONF_DIR 或者 HADOOP_CONF_DIR 必须将环境变量设置为读取 YARN 和 HDFS 配置
1.3.5 Flink on Yarn 的运行机制

从图中可以看出,
Yarn 的客户端需要获取 hadoop 的配置信息,连接 Yarn 的 ResourceManager。
所以要有设置有 YARN_CONF_DIR 或者 HADOOP_CONF_DIR 或者HADOOP_CONF_PATH
只要设置了其 中一个环境变量,就会被读取。如果读取上述 的变量失败了,那么将会选择 hadoop_home 的环境 变量,都区成功将会尝试加载 $HADOOP_HOME/etc/hadoop 的配置文件。
1、当启动一个 Flink Yarn 会话时,客户端首先会检查本次请求的资源是否足够。资源足够将会上传包含 HDFS 配置信息和 Flink 的 jar 包到 HDFS。
2 、随 后 客 户 端 会 向 Yarn 发 起 请 求 , 启 动 applicationMaster, 随 后 NodeManager 将 会 加 载 有 配 置 信 息 和 jar 包 , 一 旦 完 成 , ApplicationMaster(AM)便启动。
3、当 JobManager and AM 成功启动时,他们都属于同一个 container,从而 AM 就能检索到 JobManager 的地址。此时会生成新的 Flink 配置信息以便 TaskManagers 能够连接到 JobManager。同时,AM 也提供 Flink 的 WEB 接口。 用户可并行执行多个 Flink 会话。
4、随后,AM 将会开始为分发从 HDFS 中下载的 jar 以及配置文件的 container 给 TaskMangers.完成后 Fink 就完全启动并等待接收提交的 job。
1.3.6 Flink on Yarn 的两种使用方式
yarn-session 提供两种模式
1) 会话模式
使用 Flink 中 的 yarn-session ( yarn 客 户 端 ) , 会启动两个必要服务JobManager和 TaskManagers。
客户端通过 yarn-session 提交作业 yarn-session 会一直启动,不停地接收客户端提交的作业 ,有大量的小作业,适合使用这种方式。
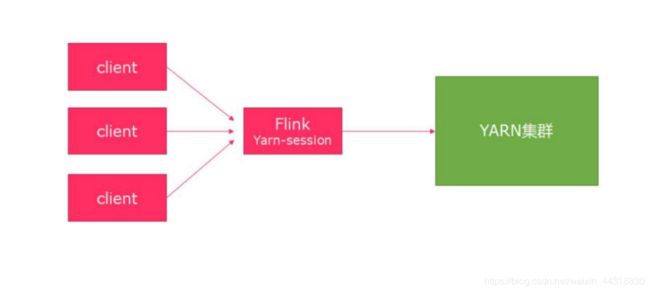
2) 分离模式
直接提交任务给 YARN ,大作业,适合使用这种方式。

1.3.6.1 第一种方式:YARN session
- yarn-session.sh(开辟资源)+flink run(提交任务)
这种模式下会启动 yarn session,并且会启动 Flink 的两个必要服务: JobManager 和 Task-managers,然后你可以向集群提交作业。同一个 Session 中可以提交多个 Flink 作业。需要注意的是,这种模式下 Hadoop 的版本至少 是 2.2,而且必须安装了 HDFS(因为启动 YARN session 的时候会向 HDFS 上 提交相关的 jar 文件和配置文件)。
通过./bin/yarn-session.sh 脚本启动 YARN Session
脚本可以携带的参数:

注意:
如果不想让 Flink YARN 客户端始终运行,那么也可以启动分离的 YARN 会话。 该参数被称为 -d 或–detached。
■ 启动:
bin/yarn-session.sh -n 2 -tm 800 -s 1 -d
上面的命令的意思是,同时向 Yarn 申请 3 个 container(即便只申请了两个,因为 ApplicationMaster 和 Job Manager 有一个额外的容器。一旦将 Flink 部署到 YARN 群集 中,它就会显示 Job Manager 的连接详细信息),其中 2 个 Container 启动 TaskManager (-n 2),每个 TaskManager 拥有 1 个 Task Slot(-s 1),并且向每个 TaskManager 的 Container 申请 800M 的内存,以及一个 ApplicationMaster(Job Manager)。
启动成功之后,去 yarn 页面:ip:8088 可以查看当前提交的 flink session。

点击 ApplicationMaster 进入任务页面:

上面的页面就是使用:yarn-session.sh。
■ 然后使用 flink 提交任务
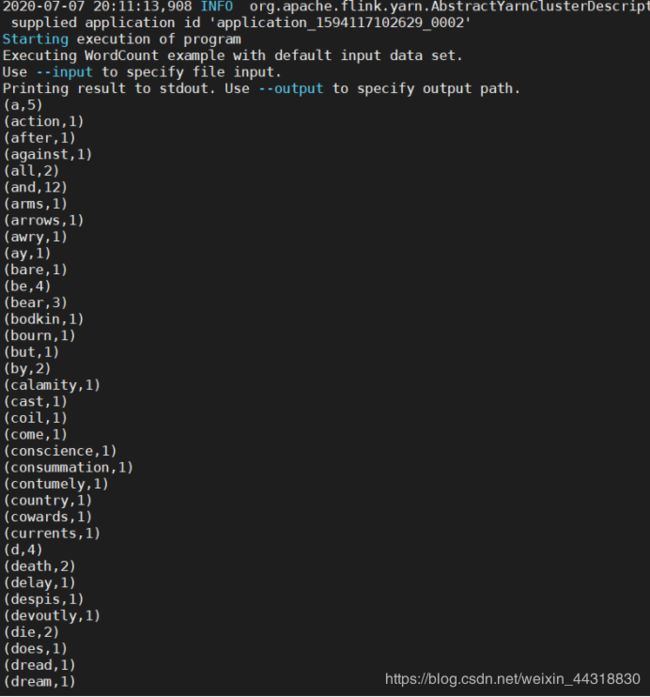
bin/flink run examples/batch/WordCount.jar
在控制台中可以看到 wordCount.jar 计算出来的任务结果
■ 在 yarn-session.sh 提交后的任务页面中也可以观察到当前提交的任务:
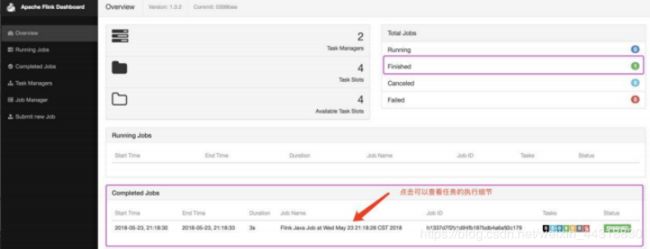
■ 点击查看任务细节:

■ 停止当前任务:
yarn application -kill application_1527077715040_0007
1.3.6.2 第二种方式:在 YARN 上运行一个 Flink 作业
上面的 YARN session 是在 Hadoop YARN 环境下启动一个 Flink cluster 集群,里面的资源 是可以共享给其他的 Flink 作业。我们还可以在 YARN 上启 动一个 Flink 作业,这里我们还是使用 ./bin/flink,但是不需要事先启动 YARN session。
■ 使用 flink 直接提交任务
bin/flink run -m yarn-cluster -yn 2 ./examples/batch/WordCount.jar
以上命令在参数前加上 y 前缀,-yn 表示 TaskManager 个数
在 8088 页面观察:

■ 停止 yarn-cluster
yarn application -kill application 的 ID
注意:
如果使用的 是 flink on yarn 方式,想切换回 standalone 模式的话, 需要删除文件: 【/tmp/.yarn-properties-root】
因为默认查找当前 yarn 集群中已有的 yarn-session 信息中的 jobmanager。
小结
本篇博客博主为大家详细介绍了Flink常见的3种模式的集群搭建以及一些避坑指南。下一篇博客,我们将学习Flink 运行架构,敬请期待|ू・ω・` )
如果以上过程中出现了任何的纰漏错误,烦请大佬们指正
受益的朋友或对大数据技术感兴趣的伙伴记得点赞关注支持一波
希望我们都能在学习的道路上越走越远
