分析Ajax爬取今日头条摄影集图片 (完全破解 max_behot_time ,as ,cp,_signature 参数)
工具:谷歌浏览器,vscode ,
主要python库:requests,execjs,selenium,re
1.前期分析
网页页面:
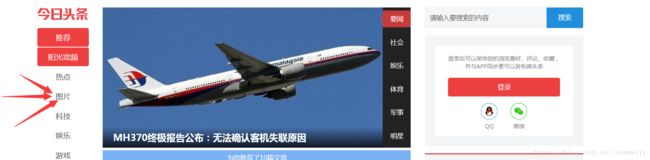
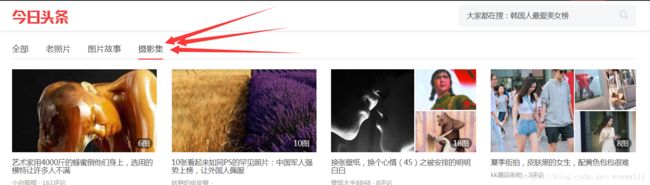
页面分析:
1.用谷歌浏览器查看网页源代码,并未发现图片的相关信息,判断使用Ajax
2.要谷歌自带检查工具,查看网页Ajax请求,果不期然发现目标
Ajax请求的响应内容分析:

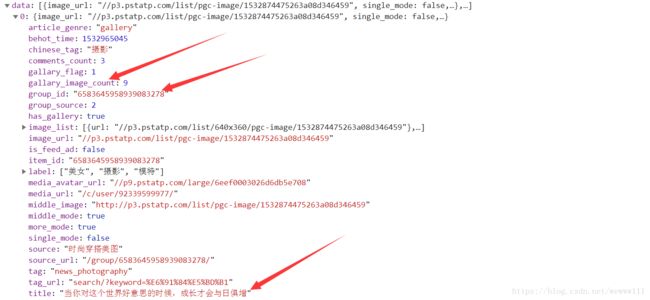
查看上图中data 里的数据(0,1,2,3....),发现页面的图片信息都包含其中,如下图
点开页面上的图片,可以发现是一组图片,每张图片的URL
https://www.toutiao.com/a6583645958939083278/#p 即(https://www.toutiao.com/a6583645958939083278/#p=1)
https://www.toutiao.com/a6583645958939083278/#p=2
https://www.toutiao.com/a6583645958939083278/#p=3
https://www.toutiao.com/a6583645958939083278/#p=4
规律:URL链接中绿色部分 变化规律为 /#p=1,2,3,4....... 具体的图片数量,可以从上图的data中的gallary_image_count:中得到
多看几张图片的URL不难发现,红色部分在一组图片URL中是不变的,恒定的,并且不难发现,数字部分在data中多次出现如:
group_id,而字母a是固定的。
解决了Ajax响应内容的解析,接下来分析每个Ajax请求的URL
解析Ajax请求 URL规律
分析可知,可以分为两部分解析
第一部分:
https://www.toutiao.com/api/pc/feed/?category=gallery_photograthy&utm_source=toutiao
分析发现,是不变的,固定的
第二部分:四个变化的参数:max_behot_time,as,cp,_signature
&max_behot_time=0
&as=A185ABD50F0ABD1
&cp=5B5FBA4B9DC1DE1
&_signature=XePSdgAABrwK1JotFh2Ks13j0m
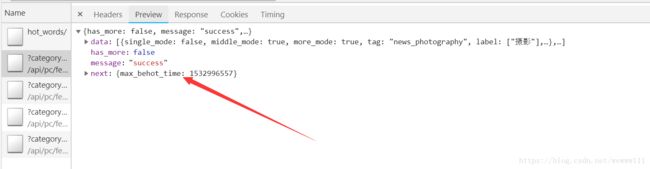
第一个参数:max_behot
规律是:第一次请求,max_behot = 0,,之后的数据在响应报文中直接给出 ,如下图:
第二,三个参数:as,cp
可以发现,响应报文中的内容,除了参数max_behot 外,没有其他几个参数的信息,而其他参数又处于动态变化之中,顺理成章的推测,信息应该存在JS文件中,如下图:
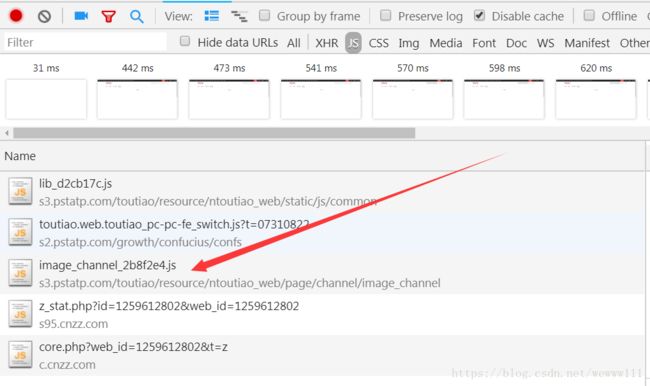
打开以上所有JS文件,进行关键词搜索,发现只有image_channel.js中存在与关键词as,cp,_signature信息有关的,将所有信息赋值到vscode中进行代码格式化,方便分析,最终发现如下信息:
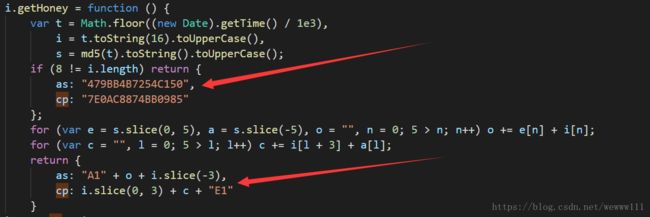
可以看到,cp,as是和当前时间有关的,复制到本地,改为自己的JS函数,import execjs 执行这个函数,即可获得cp,as 参数
第四个参数:_signature
js文件中有如下信息:
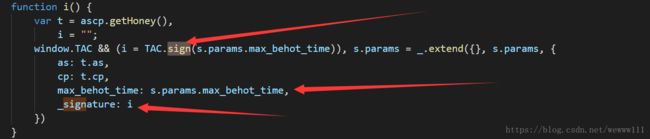
可知:_signature = i = TAC.sign(s.params.max_behot_time), 即 _signature = TAC.sign(max_behot_time)
但是:TAC.sign()函数无法使用,无法解析(???如有破解者,望告知)
解决方法:import selenium + Chrome , 加载页面后,用exectute_script()函数执行window.TAC.sign("+str(jmax)+")
得到_signature的值,(以上如有配置问题,可以探讨)
解析Ajax响应报文内容,得到组图的URL地址
即如下页面的地址,和title:
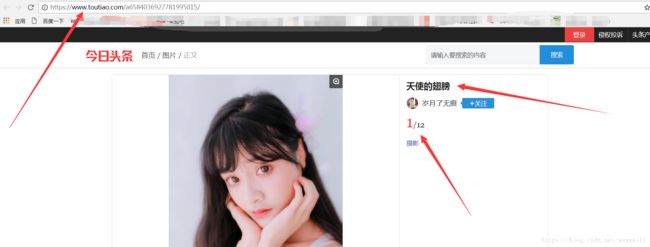
响应报文为json 格式,赋值到vscode格式化,发现内容如下:(图中 中文经过Unicode转码)
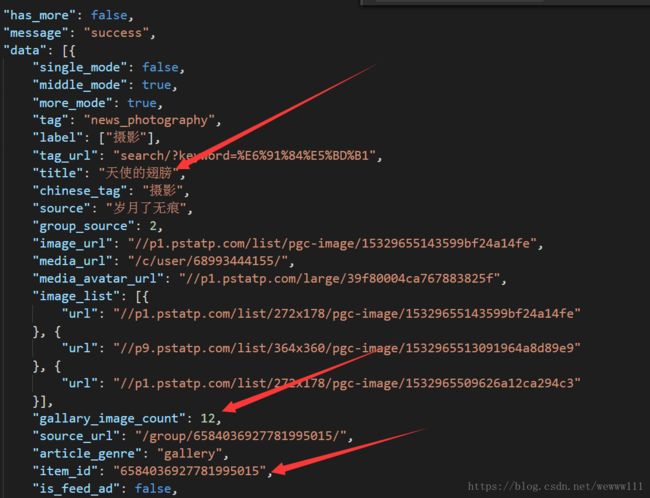
分析结果:图片信息存储在data中,用requests.get(AjaxUrl)得到响应报文,用json.loads()化为字典格式,
得到data 中的title,item_id(组图url的数字部分),便可以得到图片的URL https://www.toutiao.com/a+item_id/
对图片的URL https://www.toutiao.com/a+item_id/ 的页面源代码分析

可以发现,这一组图片的所有URL都存在于gallery:JSON.parse()中,import re ,用正则获取,并化为字典类型,得到所有URL
自此,理论上解决了所有问题,一下呈现爬取结果:
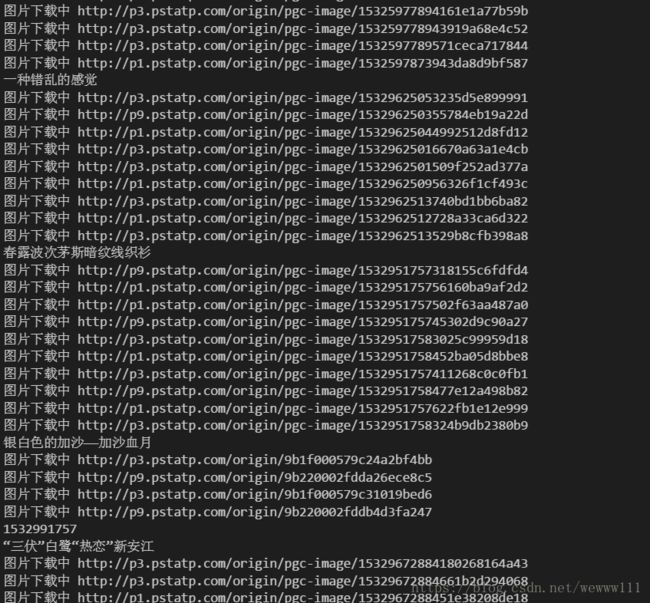
爬取的部分组图标题:
