Nutch2.3.1+MongoDB+ElasticSearch1.4.4 环境配置
前言:本博客是nutch本地运行的一篇配置实践笔记,不包含分布式运行配置
1.环境准备
Ubuntu 16.04
jdk 1.8
Ant 1.9.13
2.Mongodb安装
1)mongodb数据库安装及基本概念学习
参考:http://www.runoob.com/mongodb/mongodb-linux-install.html
2)mongodb可视化工具:robomongo
1、下载RoboMongo
RoboMongo官网下载链接:https://robomongo.org/
2、解压文件
tar -xzf robo3t-1.1.1-linux-x86_64-c93c6b0.tar.gz
cd robo3t-1.1.1-linux-x86_64-c93c6b0 (如果移动到其他目录,请加上相应的目录。)
解压后,把robomongo文件夹保存到一个常用的软件文件夹内,因为robomongo会直接从这个文件夹启动。
3、启动robo3t
3.ElasticSearch安装
1)下载安装
gannyee@ubuntu:~/download$wget https://download.elasticsearch.org/elasticsearch/elasticsearch/elasticsearch-1.4.4.tar.gz
gannyee@ubuntu:~/download$tar -zxvf elasticsearch-1.4.4.tar.gz
gannyee@ubuntu:~/download$ mv elasticsearch-1.4.4 ../elasticsearch
gannyee@ubuntu:~$cd /elasticsearch2)ES启动、关闭
后台启动ElasticSearch
gannyee@ubuntu:~/elasticsearch$ ./bin/elasticsearch -d终止ElasticSearch进程
关闭单一节点
gannyee@ubuntu:~/elasticsearch$curl -XPOST http://localhost:9200/_cluster/nodes/_shutdown
关闭节点BlrmMvBdSKiCeYGsiHijdg
gannyee@ubuntu:~/elasticsearch$curl –XPOST http://localhost:9200/_cluster/nodes/BlrmMvBdSKiCeYGsiHijdg/_shutdown检测是否成功运行ElasticSearch
在浏览器地址栏输入:http://localhost:9200,显示以下信息则表示ES启动成功
{
"status" : 200,
"name" : "gannyee",
"cluster_name" : "gannyee",
"version" : {
"number" : "1.4.4",
"build_hash" : "c88f77ffc81301dfa9dfd81ca2232f09588bd512",
"build_timestamp" : "2015-02-19T13:05:36Z",
"build_snapshot" : false,
"lucene_version" : "4.10.3"
},
"tagline" : "You Know, for Search"
}
3)由于elasticsearch1.4.4版本比较旧,一些插件已经不能正常安装使用了,对ES信息的查询建议使用curl命令
curl命令可在终端使用,也可在浏览器地址栏使用,命令参考https://blog.csdn.net/qq834024958/article/details/81902963
4.Nutch安装配置
在Lucene发展来的开源网络爬虫,本次配置只能使用nutch2.x系列,1.x系列不支持MongoDB等其他如Mysql,Habase数据库。
版本:apache-nutch-2.3.1
Nutch2.3下载、编译、配置
下载源码
gannyee@ubuntu:~/download$ wget
http://www.apache.org/dyn/closer.lua/nutch/2.3.1/apache-nutch-2.3.1-src.tar.gz
gannyee@ubuntu:~/download$ tar -zxvf apache-nutch-2.3.1-src.tar.gz
gannyee@ubuntu:~/download$ mv apache-nutch-2.3.1 ../nutch
gannyee@ubuntu:~/download$ cd ../nutch
gannyee@ubuntu:~/nutch$ export NUTCH_HOME=$(pwd)
修改/conf/nutch-site.xml使Mongodb作为GORA的存储单元
gannyee@ubuntu:~/nutch/conf$ vim nutch-site.conf
storage.data.store.class
org.apache.gora.mongodb.store.MongoStore
Default class for storing data
从/ivy/ivy.xml文件中取消下面部分的注释
gannyee@ubuntu:~/nutch/conf$ vim $NUTCH_HOME/ivy/ivy.xml
修改ivy源
由于默认的ivy源速度比较慢,所以在这里换成国内的源
在ivy/ivysetting.xml文件中找到下面这段配置
把value替换成阿里云的地址:
http://maven.aliyun.com/nexus/content/groups/public/确保MongoStore设置为默认数据存储
gannyee@ubuntu:~/nutch$ vim conf/gora.properties
/#######################
/# MongoDBStore properties #
/#######################
gora.datastore.default=org.apache.gora.mongodb.store.MongoStore
gora.mongodb.override_hadoop_configuration=false
gora.mongodb.mapping.file=/gora-mongodb-mapping.xml
gora.mongodb.servers=localhost:27017
gora.mongodb.db=nutch
开始编译nutch
gannyee@ubuntu:~/nutch$ant runtime如果编译过程中有如下错误
Trying to override old definition of task javac
[taskdef] Could not load definitions from resource org/sonar/ant/antlib.xml. It could not be found.
ivy-probe-antlib:
ivy-download:
[taskdef] Could not load definitions from resource org/sonar/ant/antlib.xml. It could not be found.
Trying to override old definition of task javac
[taskdef] Could not load definitions from resource org/sonar/ant/antlib.xml. It could not be found.
ivy-probe-antlib:
ivy-download:
[taskdef] Could not load definitions from resource org/sonar/ant/antlib.xml. It could not be found.是因为缺少lib包,解决办法如下(其实可以无视):
下载 sonar-ant-task-2.1.jar,拷贝到 $NUTCH_HOME/lib 目录下面
修改 $NUTCH_HOME/build.xml,引入上面添加
编译后的文件将被放在新生成的文件夹/nutch/runtime中
Nutch编译成功之后,会在主目录下生成一个runtime文件夹。其中包含deploy和local两个子文件夹。deploy用于分布式抓取,而local用于本地单机抓取。进入local文件夹,再进入bin文件夹。这里包含两个脚本文件,一个是nutch,另一个是crawl。其中,nutch包含了所需的全部命令,而crawl主要用于一站式抓取。
最后确认nutch已经正确地编译和运行,输出如下:
gannyee@ubuntu:~/nutch/runtime/local$ ./bin/nutch
Usage: nutch COMMAND
where COMMAND is one of:
inject inject new urls into the database
hostinject creates or updates an existing host table from a text file
generate generate new batches to fetch from crawl db
fetch fetch URLs marked during generate
parse parse URLs marked during fetch
updatedb update web table after parsing
updatehostdb update host table after parsing
readdb read/dump records from page database
readhostdb display entries from the hostDB
index run the plugin-based indexer on parsed batches
elasticindex run the elasticsearch indexer - DEPRECATED use the index command instead
solrindex run the solr indexer on parsed batches - DEPRECATED use the index command instead
solrdedup remove duplicates from solr
solrclean remove HTTP 301 and 404 documents from solr - DEPRECATED use the clean command instead
clean remove HTTP 301 and 404 documents and duplicates from indexing backends configured via plugins
parsechecker check the parser for a given url
indexchecker check the indexing filters for a given url
plugin load a plugin and run one of its classes main()
nutchserver run a (local) Nutch server on a user defined port
webapp run a local Nutch web application
junit runs the given JUnit test
or
CLASSNAME run the class named CLASSNAME
Most commands print help when invoked w/o parameters.定制你的爬取特性,修改/nutch/runtime/local/conf/nutch-site.xml
storage.data.store.class
org.apache.gora.mongodb.store.MongoStore
Default class for storing data
http.agent.name
Hist Crawler
plugin.includes
protocol-http|urlfilter-regex|parse-(html|tika)|index-(basic|anchor)|indexer-elastic|scoring-opic|urlnormalizer-(pass|regex|basic)
Regular expression naming plugin directory names to
include. Any plugin not matching this expression is excluded.
In any case you need at least include the nutch-extensionpoints plugin. By
default Nutch includes crawling just HTML and plain text via HTTP,
and basic indexing and search plugins. In order to use HTTPS please enable
protocol-httpclient, but be aware of possible intermittent problems with the
underlying commons-httpclient library.
elastic.host
localhost
elastic.cluster
elasticsearch
elastic.index
nutch
parser.character.encoding.default
utf-8
http.content.limit
6553600
此示例包含了数据存储在mongodb和索引数据到ES的配置。
创建种子文件
创建文件夹/nutch/runtime/local/urls,在此文件夹下建立seed.txt文件,写入待爬取的种子链接,示例:
http://www.runoob.com/redis/redis-tutorial.html
http://www.lianzais.com/4_4003/
http://www.lianzais.com/4_4003/1679835.html
http://www.lianzais.com/5_5279/2378223.html
http://www.lianzais.com/5_5279/
https://www.xbiquge6.com/0_761/
https://www.xbiquge6.com/0_761/1272131.html5.执行分步爬取流程
初始化crawldb
gannyee@ubuntu:~/nutch/runtime/local$ ./bin/nutch inject urls/从 crawldb生成urls
gannyee@ubuntu:~/nutch/runtime/local$ ./bin/nutch generate -topN 80获取生成的所有urls
gannyee@ubuntu:~/nutch/runtime/local$ ./bin/nutch fetch -all解析获取的urls
gannyee@ubuntu:~/nutch/runtime/local$./ bin/nutch parse -all更新database数据库
gannyee@ubuntu:~/nutch/runtime/local$ ./bin/nutch updatedb -all索引解析的urls
gannyee@ubuntu:~/nutch/runtime/local$ bin/nutch index -all爬取完给定网页,mongoDB会生成一个新的数据库:nutch,elasticsearch中会生成新的索引库nutch.
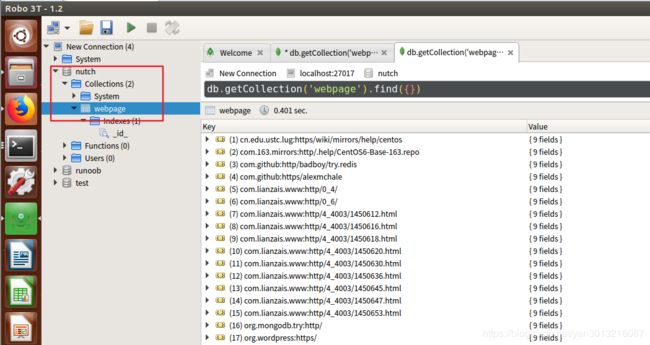
可查看某一条记录的详细信息

右上角可选择不同的数据展示方式

查看elasticsearch中的索引数据
http://localhost:9200/nutch/_search?pretty=ture
使用size指定返回的记录条数
http://localhost:9200/nutch/_search?size=100&pretty=ture

6. 异常处理
查看runtime/local/logs 目录下的 hadoop.log 日志文件,查看详细异常信息,上网查找解决办法
参考:
https://blog.csdn.net/github_27609763/article/details/50597427
https://blog.csdn.net/bluestarjava/article/details/53843857
https://blog.csdn.net/qq834024958/article/details/81902963
http://www.it610.com/article/2180055.htm