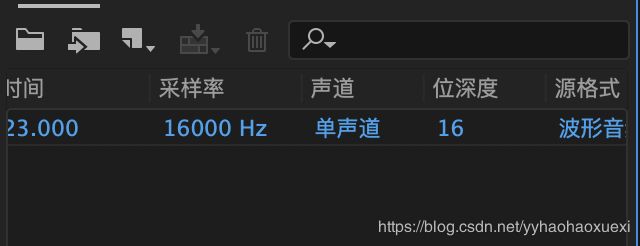
wav文件降采样
一、librosa
import librosa
import soundfile as sf
def wav_file_resample(src, dst, dst_sample):
"""
对目标文件进行降采样,采样率为dst_sample
:param src:源文件路径
:param dst:降采样后文件保存路径
:param dst_sample:降采样后的采样率
:return:
"""
src_sig, sr = sf.read(src)
dst_sig = librosa.resample(src_sig, sr, dst_sample)
sf.write(dst, dst_sig, dst_sample)
二、scipy.signal
import scipy.signal as signal
import scipy.io.wavfile as wavfile
def wav_file_resample(src, dst, source_sample=44100, dest_sample=16000):
"""
对WAV文件进行resample的操作
:param file_path: 需要进行resample操作的wav文件的路径
:param source_sample:原始采样率
:param dest_sample:目标采样率
:return:
"""
sample_rate, sig = wavfile.read(src)
result = int((sig.shape[0]) / source_sample * dest_sample)
x_resampled = signal.resample(sig, result)
x_resampled = x_resampled.astype(np.float64)
return x_resampled, dest_sample
三、AdobeAudition
3.1 导入文件
使用au导入初始语音,如下图:


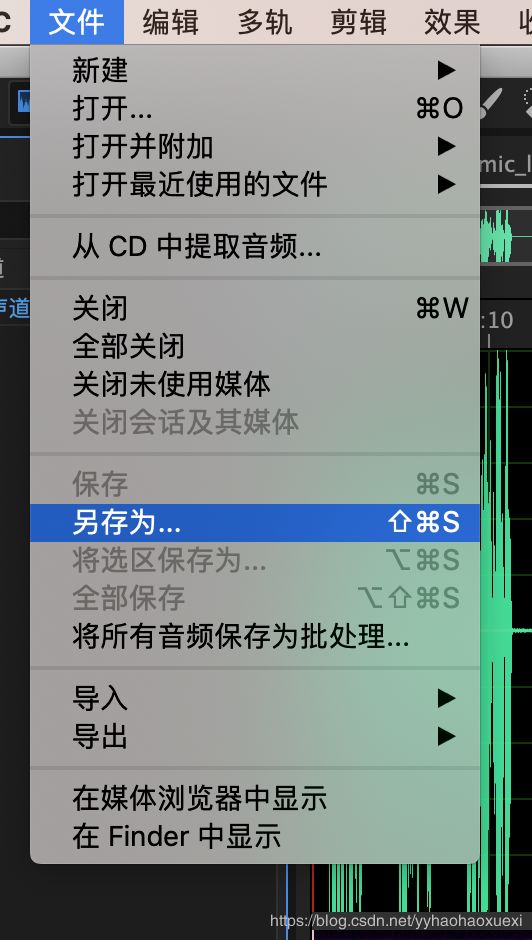
3.2 另存为
3.3 更改采样率和位深度
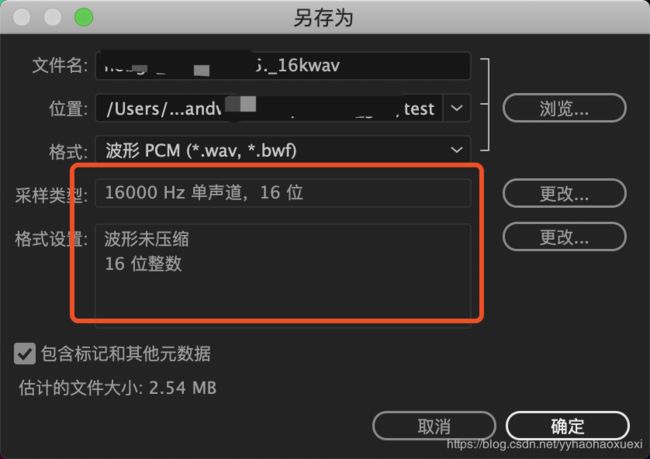
点击确定即可。结果如下: