微信小程序_请求失败
问题:微信小程序请求失败
今天遇到这个问题

成功请求因该是
解决方法
Chromium神秘的cache lock
对请求头加个时间戳让其变得唯一 或者服务器响应头设置为无缓存 'cache-control': 'no-cache', 就ok 了
知识点
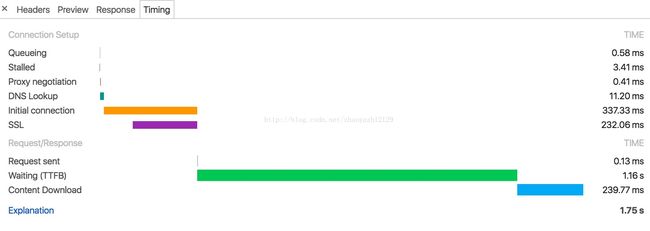
Chrome浏览器的Timing分析

Stalled是浏览器得到要发出这个请求的指令,到请求可以发出的等待时间,一般是代理协商、以及等待可复用的TCP连接释放的时间,不包括DNS查询、建立TCP连接等时间等。
SSL(Secure Sockets Layer 安全套接层),及其继任者传输层安全(Transport Layer Security,TLS)是为网络通信提供安全及数据完整性的一种安全协议。TLS与SSL在传输层对网络连接进行加密。
SSL当前版本为3.0。它已被广泛地用于Web浏览器与服务器之间的身份认证和加密数据传输。
Request sent 请求第一个字节发出前到最后一个字节发出后的时间,也就是上传时间
Waiting 请求发出后,到收到响应的第一个字节所花费的时间(Time To First Byte)
首字节时间:
浏览器开始收到服务器响应数据的时间=后台处理时间+重定向时间,是反映服务端响应速度的重要指标
TTFB (Time To First Byte),是最初的网络请求被发起到从服务器接收到第一个字节这段时间,它包含了 TCP连接时间,发送HTTP请求时间和获得响应消息第一个字节的时间。注意:网页重定向越多,TTFB越高,所以要减少重定向
Content Download 收到响应的第一个字节,到接受完最后一个字节的时间,就是下载时间
HTTPS(Hypertext Transfer Protocol Secure)安全超文本传输协议
它是由Netscape开发并内置于其浏览器中,用于对数据进行压缩和解压操作,并返回网络上传送回的结果。HTTPS实际上应用了Netscape的完全套接字层(SSL)作为HTTP应用层的子层。(HTTPS使用端口443,而不是象HTTP那样使用端口80来和TCP/IP进行通信。)SSL使用40 位关键字作为RC4流加密算法,这对于商业信息的加密是合适的。HTTPS和SSL支持使用X.509数字认证,如果需要的话用户可以确认发送者是谁。。
https是以安全为目标的HTTP通道,简单讲是HTTP的安全版。即HTTP下加入SSL层,https的安全基础是SSL。
cache lock
Stackoverflow上找到一个问题,跟现在需要解决一有些类似点:
- 偶发,并不是必然出现的。这里我们的问题也是偶发,很难复现,需要反复刷。
- 也是请求被
Pending了很久,从请求的时间线来看,体现在Stalled上。
过程是查看Chrome的网络日志,在事件里面发现有一个超时错误:
t=33627 [st= 5] HTTP_CACHE_ADD_TO_ENTRY [dt=20001] –> net_error = -409 (ERR_CACHE_LOCK_TIMEOUT)
耗时20秒之久!而且写得非常明显是ERR_CACHE_LOCK_TIMEOUT。根据提问者贴出来的链接,了解到Chrome有一个缓存锁的机制。
浏览器对一个资源发起请求前,会先检查本地缓存,此时这个请求对该资源对应的缓存的读写是独占的。那么问题来了,试想一下,当我新开一个标签尝试访问同一个资源的时候,这次请求也会去读取这个缓存,假设之前那次请求很慢,耗时很久,那么后来这次请求因为无法获取对该缓存的操作权限就一直处于等待状态。这样很不科学。于是有人建议优化一下。也就是上面所描述的那样。
随着问题的提出,还出了两种可能的实现方案。
(a) [Flexible but complicated] Allow cache readers WHILE writing is in progress. This way the first request could still have exclusive access to the cache entry, but the second request could be streamed the results as they get written to the cache entry. The end result is the second page load would mirror the progress of the first one.
(a) [Naive but simpler] Have a timeout on how long we will block readers waiting for a cache entry before giving up and bypassing the cache.
我猜上面第二个(a)应该是(b)。简单说第一种优化方案更加复杂但科学。之前的请求对缓存仍然是独占的,但随着前一次请求不断对缓存进行更新,可以把已经更新的部分拿给后面的请求读取,这样就不会完全阻塞后面的请求了。
第二种方案则更加简单暴力。给后来的请求设定一个读取缓存超时的时限,如果超过了这个时限,我认为缓存不可用或者本地没有缓存,忽略这一步直接发请求。
于是Chromium的开发者们选择了后者简单的实现。也就是Issue 345643003: Http cache: Implement a timeout for the cache lock 这个提交里的实现。
这个提交的描述如下:
The cache has a single writer / multiple reader lock to avoid downloading the same resource n times. However, it is possible to block many tabs on the same resource, for instance behind an auth dialog.
This CL implements a 20 seconds timeout so that the scenario described in the bug results in multiple authentication dialogs (one per blocked tab) so the user can know what to do. It will also help with other cases when the single writer blocks for a long time.
The timeout is somewhat arbitrary but it should allow medium size resources to be downloaded before starting another request for the same item. The general solution of detecting progress and allow readers to start before the writer finishes should be implemented on another CL.
于是就产生了上面题主遇到的情况。
所以他的解决方法就很明朗了,对请求加个时间戳让其变得唯一,或者服务器响应头设置为无缓存。Both will work!
wx.request({
url: rootDocment + url,
header: {
'content-type': 'application/x-www-form-urlencoded',
'cache-control': 'no-cache',
},
success: function (res) {
success(res);
},
fail: function (res) {
fail(res)
console.log(res.errMsg);
}
});完美解决