Python爬虫爬取豆瓣TOP250和网易云歌单
python爬虫(网易云)笔记
@(python学习)
- 先
推荐看一下b站的视频链接如下:https://www.bilibili.com/video/BV12E411A7ZQ?from=search&seid=10419059379828214037 - 里面具体介绍了语法和pycharm编辑器的用法还有如何爬取豆瓣TOP250的过程(代码在后面),我自己再根据过程写了爬取网易云歌单,只是比原来的多了个循环爬取了歌曲,本来不必进入但是因为大网站他有反爬,所以得多写一层
- 最后爬取的结果如下:
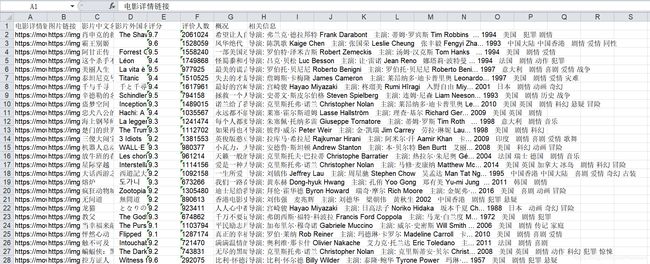
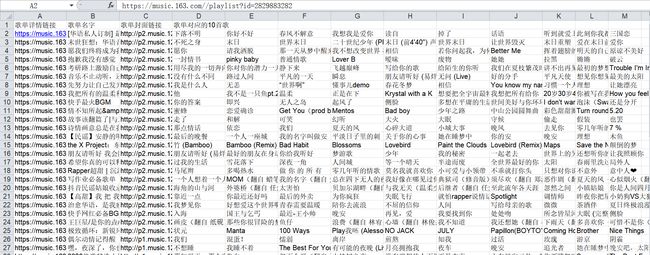
基本流程
- 准备工作
- 查看页面整体html框架,分析标签
- 获取数据
- 写一个askurl函数获取整个页面内容,传入一个链接地址作为参数
一定注意:
网址除去/和#不然会获取到没有有用信息的代码段并且会被反爬
(但其实去除符号之后得到了歌曲信息其他还是被加密了,自己分清楚哪些可以爬哪些不行,一定要根据自己代码爬出的页面去写后面的,而不是光看F12以后的页面元素)- urllib.Request生成请求 urllib.urlopen发送请求获取响应 read读取
注意头部信息处理- 设置异常处理加入异常捕获try except语句
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"): # 什么原因导致没有打印成功
print(e.reason) #打印出来可能会有404,500等错误
- 逐一解析内容:利用
正则表达式和页面解析库bs
在getdata函数中由于img标签的正则表达式的错误导致产生了很多多余的不要的信息
-
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-seeHQiex-1595850838299)(./}7JHYL5O0$GDL692DCFTI8.png)]
-
保存数据:用xlwt保存到excel表格里
注意小点
- 一些库的说明
- bs4网页解析获取数据(爬完网页将数据进行拆分);
- re正则表达式进行文字匹配(进行数据的提炼);
- urllib.request,.error制定url获取网页数据(给网页就能爬);
- xlwt进行excel操作(存到excel)
- sqlite3进行SQLITE数据库操(存到数据库)
- 发起请求:
- urlopen方法可以实现最基本的请求的发起,但是如果要加入headers等信息,就可以用Request类来构造请求。此时要注意头部信息的空格的处理
- 从爬取歌单界面进入每一个歌单内部,发现歌单的链接和歌曲的链接只是后面id后缀的值不同可以用列表将其保存再利用列表进入链接内部
- 原本页面信息链接的符号多余或者一些http的省略要用拼串接上
例如获取歌单链接时:
data.append("https://music.163.com/"+link)
for i in range(0,70):
a=datalist[i][0]
a=a[0:22]+a[23:] #除去多余的/
baseurl2.append(a)
- 几个正则表达式设置为全局变量
#70个歌单的链接
findLink=re.compile('')
#歌单名字
findAlbum=re.compile('')
#70页歌单封面的链接
findImgSrc=re.compile(r') ',re.S)
#10首歌曲名字
findSongTitle=re.compile('(.*?)')
',re.S)
#10首歌曲名字
findSongTitle=re.compile('(.*?)')
中途出现的错误
- 1、500,头部信息没有处理好
- 2、正则表达式没有处理好获取到了不必要的信息
- 3、反爬机制,解析到的数据页面与原来的数据页面不相同导致获取标签时出现错误(寻找even的div但是已经改成了u-cover u-cover-1,并且原来的tr/td标签的表格变成了一堆乱码,提取不到想要的信息,可能是加密或者是服务器不给你提供)
- 4、可以爬取到歌单信息与歌曲信息,但是爬取不到歌单页面的其他信息只有歌名,根据id进入歌曲链接后可以爬到歌曲信息
- 5、链接的处理
子函数功能分析
- def askUrl(url): #模拟浏览器头部信息向网易云服务器发送信息
- def getData2(baseurl2):#解析歌单内部界面获取歌曲信息
- def getData(baseurl):#逐一解析歌单信息
- def saveData(datalist,datalist2,savepath):#获取到的歌单信息和歌曲信息存入excel表格
附加:代码(第一个是豆瓣第二个是网易云)
- 豆瓣TOP250:
from bs4 import BeautifulSoup
import urllib.request,urllib.error
import xlwt
import re
import sqlite3
def main():
baseurl="https://movie.douban.com/top250?start="
#1.爬取网页
datalist=getData(baseurl)
savepath="豆瓣电影Top250.xls"
#3.保存数据
saveData(datalist,savepath)
#askUrl("https://movie.douban.com/top250?start=0")
#影片详情链接规则
findLink=re.compile(r'')#创建正则表达式表示规则
#影片图片的链接规则
findImgSrc=re.compile(r'(.*)')
#影片评分
findRating=re.compile(r'')
#评价人数
findJudge=re.compile(r'(\d*)人评价')
#找到概况
findInq=re.compile(r'(.*)')
#找到影片的相关内容
findBd=re.compile(r'(.*?)
',re.S)
#爬取网页
def getData(baseurl):
datalist = []
for i in range(0,10):
#当i=0的时候即start=0第一页的信息,并且i从0到10即调用十次获取页面信息的函数,
url = baseurl + str(i*25)#即start的值,
html = askUrl(url)#保存获取到的网页源码
# 2.逐一解析数据
soup = BeautifulSoup(html,"html.parser")
for item in soup.find_all('div',class_="item"):
data = []#保存一部电影的全部信息
item = str(item)
link = re.findall(findLink,item)[0]
#findLink是一个全局变量
data.append(link)
imgSrc = re.findall(findImgSrc,item)[0]
data.append(imgSrc)
titles = re.findall(findTitle,item)#影片可能有一个中文名一个英文名字
if(len(titles) == 2):
ctitle = titles[0]
data.append(ctitle)#添加中文名
otitle = titles[1].replace("/","")#因为英文名字前有个/,去掉无关符号
data.append(otitle)#添加外国名
else:
data.append(titles[0])
data.append(' ')#外国名留空因为最后是表格
rating = re.findall(findRating,item)[0]
data.append(rating)#添加评分
judgeNum = re.findall(findJudge, item)[0]
data.append(judgeNum) # 添加评价人数
inq = re.findall(findInq,item)
if len(inq) != 0:
inq = inq[0].replace("。","")
data.append(inq) # 添加概述
else:
data.append(" ")
bd = re.findall(findBd,item)[0]
bd = re.sub(' - 下面是网易云的:
#-*- coding=utf-8 -*-
#@Time : 2020/6/2920:03
#@Author : 雪宝
#@File : spider.py
#@Software: PyCharm
from bs4 import BeautifulSoup
import urllib.request,urllib.error
import xlwt
import re
def main():
baseurl="https://music.163.com/discover/playlist/?order=hot&cat=%E5%8D%8E%E8%AF%AD&limit=35&offset=0"
datalist=getData(baseurl)
savepath = "网易云.xls"
baseurl2=[]
for i in range(0,70):
a=datalist[i][0]
a=a[0:22]+a[23:] #除去多余的/
baseurl2.append(a)
# print(baseurl2)
datalist2 = getData2(baseurl2)
saveData(datalist,datalist2,savepath)
# savepath="网易云.xls"
# askUrl("https://music.163.com/discover/playlist/?order=hot&cat=%E5%8D%8E%E8%AF%AD&limit=35&offset=0")
#对askurl函数进行测试获取华语歌单
# saveData(datalist, savepath)
#70个歌单的链接
findLink=re.compile('')
#歌单名字
findAlbum=re.compile('')
#70页歌单封面的链接
findImgSrc=re.compile(r'',re.S)
#10首歌曲名字
findSongTitle=re.compile('(.*?)')
def askUrl(url): #模拟浏览器头部信息向网易云服务器发送信息
head={
"User-Agent": "Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, like Gecko) Cha rome / 83.0.4103.116 Safari / 537.36"
}
request=urllib.request.Request(url,headers=head)
html=""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"): # 什么原因导致没有打印成功
print(e.reason)
except IndexError:
pass
return html
def getData2(baseurl2):#解析歌单界面
songdatalist = []
for i in range(0,70): #找70个歌单
url=baseurl2[i]
html=askUrl(url)
#print(html) #测试整个页面的代码
soup=BeautifulSoup(html,"html.parser")
# 形成树形结构的对象
songitem=soup.find_all('ul',class_="f-hide") #找歌单里面每个ul标签
songdata=[]
songitem=str(songitem)
#print(songitem) #测试每个包含歌曲D的ul标签内容
for j in range(0,10): #找ul标签的每个列表项包含的歌名
title=re.findall(findSongTitle,songitem)[j][1]
# print(title)
songdata.append(title.strip())
#print(songdata)
songdatalist.append(songdata)
# re.sub('\u202d ',"",songdatalist[4][8]) #打算去除有问题的数据
print(songdatalist)
# return(songdatalist)
return songdatalist
# # songLink=re.findall(findSongLink,songitem)
# # print(songdata)
def getData(baseurl):#逐一解析
datalist=[]
for i in range(0,2):
url=baseurl+str(i*35)
html=askUrl(url)#保存每个页面的页面源码
soup=BeautifulSoup(html,"html.parser")
for item in soup.find_all('div',class_="u-cover u-cover-1"):
#测试print(item)
data=[]#保存一个歌单div的所有信息
item=str(item)
link=re.findall(findLink,item)[0][0] #re库用来通过正则表达式查找指定的字符串
data.append("https://music.163.com/"+link)
album = re.findall(findAlbum, item)[0][1]
data.append(album)
img=re.findall(findImgSrc,item)[0]
data.append(img)
# num=re.compile(findNum,item)[0]
# data.append(num)
#re库通过正则表达式来寻找
# print(link)
# print(album)
# print(img)
datalist.append(data)
return datalist
def saveData(datalist,datalist2,savepath):
print("saving...")
book = xlwt.Workbook(encoding="utf-8", style_compression=0)
sheet = book.add_sheet("网易云", cell_overwrite_ok=True)
col = ("歌单详情链接", "歌单名字", "歌单封面链接","歌单对应的10首歌")
# sheet.horz = 0x02
sheet.row(1).height = 20 * 60
for i in range(0, 4):
sheet.write(0, i, col[i])
sheet.col(3).width=256*10
for i in range(0, 70):
print("第%d条" % (i + 1))
data = datalist[i]
songdata=datalist2[i]
for j in range(0, 3):
sheet.write(i + 1, j, data[j])
for k in range(0,10):
sheet.write(i+1,k+3,songdata[k])
sheet.col(k).width = 14 * 256
sheet.col(2).width = 14 * 256
book.save(savepath)
if __name__ == "__main__":
main()
print("爬取完毕")