Julia 机器学习 --- k-折交叉验证
目录
k-折交叉验证(k-fold crossValidation)
主要目的:
Julia 中代码实现
KFold
StratifiedKFold
LOOCV(留一交叉验证)
交叉验证的函数
k-折交叉验证(k-fold crossValidation)
在机器学习中,将数据集A分为训练集(training set)B和测试集(test set)C,在样本量不充足的情况下,为了充分利用数据集对算法效果进行测试。对一组n个样本进行k-折交叉验证,这些样本被随机分成k个大小几乎相同的不相交验证集。这将生成长度约为n*(1-1/k)的k个训练子集,每次将其中一个包作为测试集,剩下k-1个包作为训练集进行训练.,交叉验证法评估结果的稳定性和保真性在很大程度上取决于k的取值.k最常用的取值是10,其他常用的k值有5 20等。
主要目的:
通过多次训练,得出偏差和方差,来衡量一个模型评估方法的好坏。
Error = Bias^2 + Variance+Noise
Bias(偏差):反映的是模型在样本上的输出与真实值之间的误差,即模型本身的精准度,即算法本身的拟合能力。
Variance(方差):反映的是模型每一次输出结果与模型输出期望之间的误差,即模型的稳定性。反应预测的波动情况。
Noise(噪声):这就简单了,就不是你想要的真正数据,你可以想象为来破坏你实验的元凶和造成你可能过拟合的原因之一,至于为什么是过拟合的原因,因为模型过度追求Low Bias会导致训练过度,对测试集判断表现优秀,导致噪声点也被拟合进去了。
Julia 中代码实现
针对K -折差验证,Julia 目前常用的两个包分别是:MLBase.jl or ScikitLearn.jl,想要搞清楚拆分数据的模式,然后再看验证方法。
KFold
划分数据集的原理:根据n_split直接进行划分k个子集,每个子集均做一次测试集,其余的作为训练集。交叉验证重复k次,每次选择一个子集作为测试集,并将k次的平均交叉验证识别正确率作为结果
Julia原生的函数中,MLBase库有一个Kfold函数,可以用于交叉验证,这里给出部分伪代码:
# 对于DataFrame 无法直接拆分数据集,需要使用其他方式
a = collect(Kfold(size(houses)[1], 5))
# 选用数据集
row = a[1]
houses[row,:]
详细的实现可以参考:交叉验证示例
StratifiedKFold
划分数据集的原理:它是分层采样,确保训练集,划分后的训练集和验证集中类别分布尽量和原数据集一样
实现方式一:
#Symbol相当于占位符,但必须与数据的length相等 ,:b 或者:a的所占比例对结果影响不大,但是数量都必须大于K
index_row = [i for i = 1:size(houses)[1]]
index_a = [:a for i = 1:size(houses)[1]*0.5]
index_b = [:b for i = 1:size(houses)[1]*0.5]
index = vcat(index_a,index_b)
rows = collect(StratifiedKfold(index, 10))
# 选用数据集
row = rows[1]
houses[row,:]实现方式二:
#更倾向于选择连续的数据,而不是随机先择,可能跟y 的生成方式有关
using ScikitLearn
f(i) = ifelse(i
LOOCV(留一交叉验证)
留一交叉验证是一个极端的例子,如果数据集D的大小为N,那么用N-1条数据进行训练,用剩下的一条数据作为验证,用一条数据作为验证的坏处就是可能EvalEval和EoutEout相差很大,所以在留一交叉验证里,每次从D中取一组作为验证集,直到所有样本都作过验证集,共计算N次,最后对验证误差求平均,得到Eloocv(H,A),这种方法称之为留一法交叉验证。
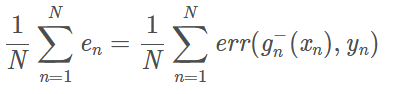
什么时候使用LOOCV:LOOCV
rows = collect(LOOCV(floor(size(houses)[1])))
# 选用数据集
row = rows[1]
houses[row,:]
其它模式参考:折交叉验证模式
交叉验证的函数
实现方式一:
#自己写
function cross_validation(train,k, learn)
a = collect(Kfold(size(train)[1], k))
for i in 1:k
row = a[i]
temp_train = train[row,:]
temp_test = train[setdiff(1:end, row),:]
#机器学习的函数learn 具体执行逻辑
end
end
#或者用手册提供的
using MLBase
# functions
compute_center(X::Matrix{Float64}) = vec(mean(X, 2))
compute_rmse(c::Vector{Float64}, X::Matrix{Float64}) =
sqrt(mean(sum(abs2(X .- c),1)))
# data
const n = 200
const data = [2., 3.] .+ randn(2, n)
# cross validation
scores = cross_validate(
inds -> compute_center(data[:, inds]), # training function
(c, inds) -> compute_rmse(c, data[:, inds]), # evaluation function
n, # total number of samples
Kfold(n, 5)) # cross validation plan: 5-fold
# get the mean and std of the scores
(m, s) = mean_and_std(scores)实现方式二:
using ScikitLearn
using PyCall
@sk_import model_selection : cross_val_score
@sk_import datasets: load_iris
@sk_import svm: SVC
#加载并返回鸢尾花数据集 (scikit-learn自带的数据集)
iris = load_iris() # 返回
svc = SVC(kernel="linear", C=1)
scores = cross_val_score(svc, iris["data"], iris["target"], cv=5)
# 5-element Array{Float64,1}:
# 0.9666666666666667
# 1.0
# 0.9666666666666667
# 0.9666666666666667
# 1.0