Apache Flink在滴滴的应用与实践

导读:Apache Flink 是一个分布式大数据处理引擎,可对有限数据流和无限数据流进行有状态计算。可部署在各种集群环境,对各种大小的数据规模进行快速计算。
滴滴基于 Apache Flink 做了大量的优化,也增加了更多的功能,比如扩展 DDL、内置消息格式解析、扩展 UDX 等,使得 Flink 能够在滴滴的业务场景中发挥更大的作用。本文中,滴滴出行实时计算负责人、高级技术专家梁李印分享了 Apache Flink 在滴滴的应用与实践。
主要内容包括:
服务化概述
StreamSQL 实践
平台化建设
挑战及规则
1.
服务化概述

▍滴滴大数据服务架构
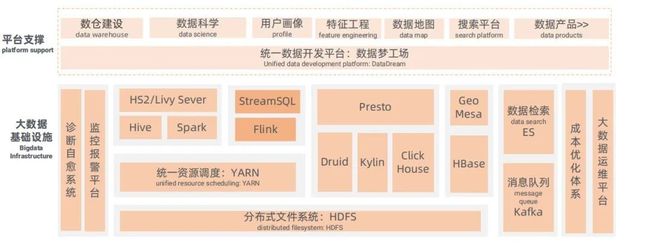
滴滴基于开源的生态构建了比较完整的大数据体系,包括离线、实时系统,如 HBase 生态、数据检索 Elastic Search、消息队列 Kafka 等。在 Flink 基础上滴滴主要发展StreamSQL,之后会有详细介绍。
▍滴滴流计算发展历程
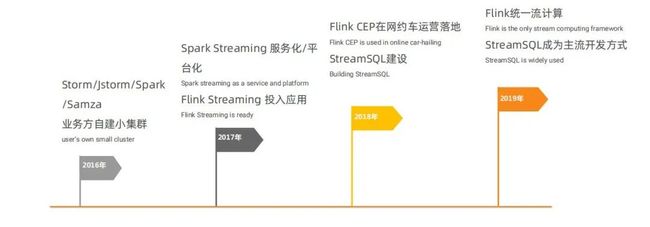
在2017年之前,滴滴流计算主要依靠业务方自建小集群的方式,技术选型也多种多样,包括 Storm、jstrom、Spark、Samza 等。2017年开始进行业务收敛,保留了8个 Spark Streaming 并构建了一个平台化、服务化的大集群,并且引入了 Flink。引入 Flink 的原因是部分业务对实时性要求较高,Spark Streaming 无法支持。2018年滴滴构建了基于 Flink SQL 的名为 StreamSQL 的 SQL 化服务,并且使用 Flink CEP 解决了一些网约车实时运营问题。2019年,滴滴完成了流计算引擎的统一,绝大部分任务以 Flink 为基础,通过 StreamSQL 开发流计算任务成为主流开发方式,达到了50%以上。
▍滴滴流计算业务规模和场景

在业务规模方面,目前滴滴流计算服务业务线达到50多个,集群规模在千级别,流计算任务数达到3000+,每天处理的数据量达到万亿条。
在业务场景上,主要包括以下四类:
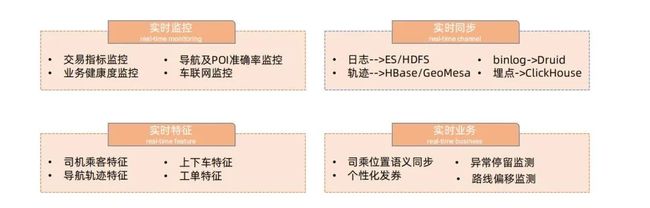
实时监控:实时监控包括交易指标监控、导航及 POI 准确率监控、业务健康度监控 ( 例如业务压测中的水位线、当前水位同水位线的实时差距监控 ) 和车辆网监控等。
实时同步:实时同步主要作用是把数据实时地从一个地方转移到另一个地方,数据包括业务日志、数据库日志、轨迹数据、埋点数据。轨迹数据放在 HBase。
实时特征:实时特征是比较关键的业务,它会影响派单,例如派单的导航和准确性。这些特征包括司机乘客特征、上下车特征、导航轨迹特征、工单特征。滴滴每天的客户量在百万级别,如果检测到高危,需要立刻触发报警和客服介入。
实时业务:实时业务会影响业务行为,包括司乘位置语义同步 ( 接单过程中司机可以实时知道乘客位置变化、乘客也可以知道司机位置变化 )、异常停留监测、高危行程监测、个性化发券、路线偏移监测等。
▍滴滴流计算多集群体系
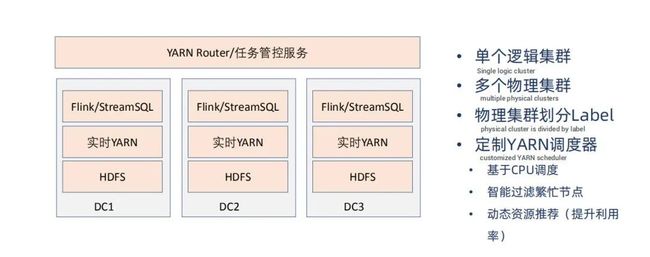
滴滴随着业务发展机房越来越多,为了更好地管理,对业务提供统一视图,滴滴在集群体系做了三方面的改进。
▪ 在 YARN 的基础上构建了路由层。路由层的职责是屏蔽多个物理集群,对业务方提供单一的逻辑集群。通过 YARN 上 queue 的划分来决定业务运行在机房的不同集群上。
▪ 在物理集群内部划分 label,通过 label 可以进行隔离,专门服务那些重要的不希望受到其他业务影响的业务。
▪ 同时定制了 YARN 调度器。由于实时和离线业务调度差异较大,所以两类业务调度完全分开。对于离线业务,希望尽可能把机器资源全部应用起来,吞吐越大越好。而实时业务对均衡性要求更高,所以将调度改为基于 CPU 调度,并且可以智能过滤繁忙节点 ( 如 CPU 使用较高的节点 ),也做了动态资源推荐,并将推荐值告知用户。
2.
StreamSQL 实践
▍StreamSQL 的优势
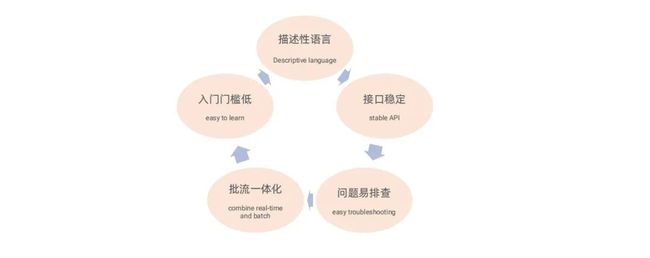
StreamSQL 是在 Flink SQL 基础上做一些完善后形成的一个产品。使用 StreamSQL 具有多个优势:
▪ 描述性语言:业务方不需要关心底层实现,只需要将业务逻辑描述出来即可。
▪ 接口稳定:Flink 版本迭代过程中只要 SQL 语法不发生变化就非常稳定。
▪ 问题易排查:逻辑性较强,用户能看懂语法即可调查出错位置。
▪ 批流一体化:批处理主要是 HiveSQL 和 Spark SQL,如果 Flink 任务也使用 SQL 的话,批处理任务和流处理任务在语法等方面可以进行共享,最终实现一体化的效果。
▪ 入门门槛低:StreamSQL 的学习入门的门槛比较低,因此受到了广大开发者的欢迎。
▍StreamSQL 相对于 Flink SQL 的完善
完善 DDL:
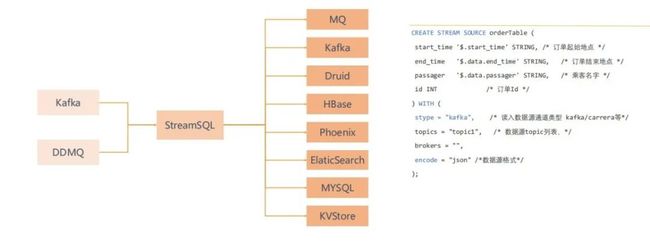
包括上游的消息队列、下游的消息队列和各种存储如 Druid、HBase 都进行了打通,用户方只需要构建一个 source 就可以将上游或者下游描述出来。
内置消息格式解析:

用户消费数据后需要将数据进行提取,但数据格式往往非常复杂,如数据库日志 binlog,每个用户单独实现,难度较大。StreamSQL 将提取库名、表名、提取列等函数内置,用户只需创建 binlog 类型 source。并内置了去重能力。
对于 business log 业务日志 StreamSQL 内置了提取日志头,提取业务字段并组装成 Map 的功能。对于 json 数据,用户无需自定义 UDF,只需通过 jsonPath 指定所需字段。
扩展 UDX:
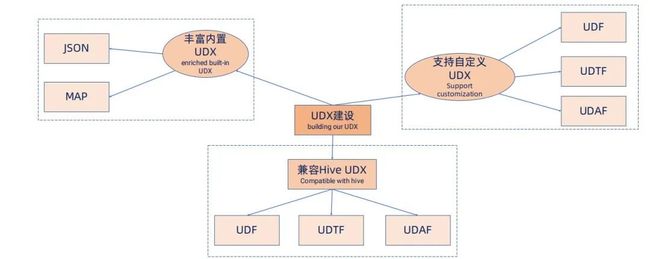
丰富内置 UDX,如对 JSON、MAP 进行了扩展,这些在滴滴业务使用场景中较多。支持自定义 UDX,用户自定义 UDF 并使用 jar 包即可。兼容 Hive UDX,例如用户原来是一个 Hive SQL 任务,则转换成实时任务不需要较多改动,有助于批流一体化。
Join 能力:
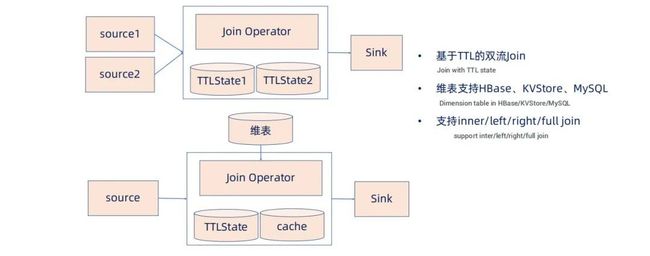
1、基于 TTL 的双流 join:
在滴滴的流计算业务中有的 join 操作数据对应的跨度比较长,例如顺风车业务发单到接单的时间跨度可能达到一个星期左右,如果这些数据的 join 基于内存操作并不可行,通常将 join 数据放在状态中,窗口通过 TTL 实现,过期自动清理。
2、维表 join 能力:
维表支持 HBase、KVStore、Mysql 等,同时支持 inner、left、right、full join 等多种方式。
3.
平台化建设
▍StreamSQL IDE
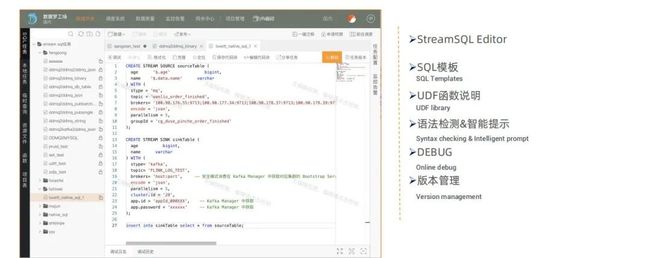
滴滴对于 StreamSQL 构建了 StreamSQL IDE,除了基本的 StreamSQL editor 外,还主要包含多个其他功能:
▪ SQL 模板:如果用户想要开发流式 SQL 时不需要从零开始,只需要选择一个 SQL 模板,并在这个模板之上进行修修改改即可达到期望的结果。
▪ UDF 函数说明:StreamSQL IDE 还提供了 UDF 的库,相当于一个库如果不知道具有什么含义以及如何使用,用户只需要在 IDE 上搜索到这个库,就能够找到使用说明以及使用案例。
▪ 语法检测与智能提示:用户输入 DB 名字可以显示表名,对错误语法提示。
▪ DEBUG:在线 DEBUG 能力,可以上传本地测试数据或者采样少量 Kafka 等 source 数据 debug,此功能对流计算任务非常重要。
▪ 版本管理:因为业务版本需要不断升级,而升级时也可能需要回退,因此 StreamSQL IDE 也提供了版本管理功能。
▍任务管控

滴滴的所有流计算全部是通过 Web 化入口进行提交,提供了整个任务生命周期管理,包括任务提交、任务停止、任务升级和回滚。同时只需要在 web 化服务台进行参数修改即可实现对内置参数 ( 如 task manager memory 等 ) 进行调优。
▍任务运维
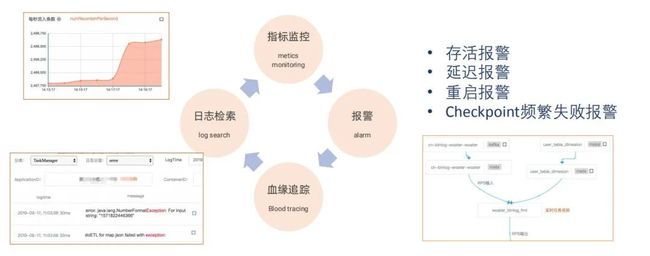
任务运维主要分为四个方面:
1、日志检索:Flink UI 上查询日志体验非常糟糕,滴滴将 Flink 任务日志进行了采集,存储在 ES 中,通过 WEB 化的界面进行检索,方便调查。
2、指标监控:Flink 指标较多,通过 Flink UI 查看体验糟糕,因此滴滴构建了一个外部的报表平台,可以对指标进行监控。
3、报警:报警需要做一个平衡,如重启报警有多类如 ( 机器宕机报警、代码错误报警 ),通过设置一天内单个任务报警次数阈值进行平衡,同时也包括存活报警 ( 如 kill、start )、延迟报警、重启报警和 Checkpoint 频繁失败报警 ( 如 checkpoint 周期配置不合理 ) 等。
4、血缘追踪:实时计算任务链路较长,从采集到消息通道,流计算,再到下游的存储经常包括4-5个环节,如果无法实现追踪,容易产生灾难性的问题。例如发现某流式任务流量暴涨后,需要先查看其消费的 topic 是否增加,topic 上游采集是否增加,采集的数据库 DB 是否产生不恰当地批量操作或者某个业务在不断增加日志。这类问题需要从下游到上游、从上游到下游多方向的血缘追踪,方便调查原因。
▍Meta 化建设
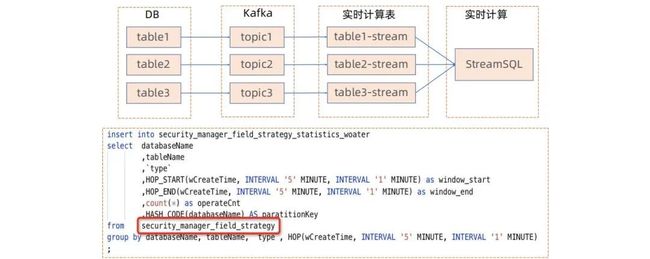
对比批处理任务,流计算 Flink 任务需要先定义好 Source、Sink,需要先定义好 MetaStore,因此滴滴目前正在做实时 Meta,将实时数据如 Kafka 的数据流定义成实时表,存储在 MetaStore 中,用户在 IDE 中只需要写 DML ( 数据操纵语言 Data Manipulation Language ) 语句,系统在执行时自动填补 DDL ( 数据定义语言 Data Definition Language ) 语句,将完整的 StreamSQL 提交到 Flink 中去,该工作可以极大的降低 Flink 的使用门槛。
▍批流一体化
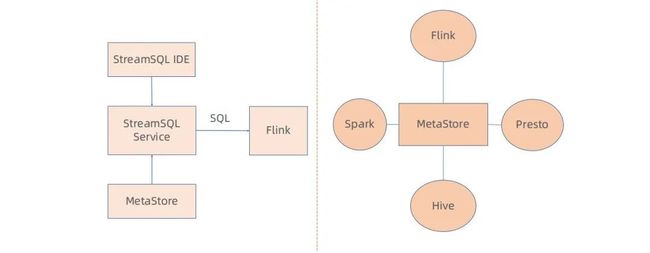
虽然 Flink 具备批流一体化能力,但滴滴目前并没有完全批流一体化,希望先从产品层面实现批流一体化。通过 Meta 化建设,实现整个滴滴只有一个 MetaStore,无论是 Hive、Kafka topic、还是下游的 HBase、ES 都定义到 MetaStore 中,所有的计算引擎包括 Hive、Spark、Presto、Flink 都查询同一个 MetaStore,实现整个 SQL 开发完全一致的效果。根据 SQL 消费的 Source 是表还是流,来区分批处理任务和流处理任务,从产品层面上实现批流一体化效果。
4.
挑战及规则
▍面临的挑战

大状态管理:
▪ Flink 作为一个有状态的计算引擎,状态有时会非常大,在记录 checkpoint 过程中需要数据线对齐,磁盘 IO 变大,导致机器负载增大,checkpoint 效率的高低会影响服务稳定性。
▪ 目前 checkpoint 是一个黑盒,如何做状态诊断是一个挑战。
▪ 通过内置系统解决了上游不重复问题,但 Flink 本身问题没有解决,希望构建一个端到端的 Exactly Once。
业务高可用:
▪ 滴滴很多内部业务是通过 golang 或者 java 开发,迁移到 Flink 后,可以解决容错问题、拓展问题、算法模型问题等。在升级时业务不可停,需要实现透明升级。
▪ 快速诊断解决问题。
▪ 资源伸缩,如滴滴的早晚高峰时流量突增情况下如何保持系统稳定。
多语言:
虽然今天在滴滴大部分实时任务都是通过 SQL 来开发的,但是依旧不能100%覆盖全部的场景,有些场景下是需要写代码的。Flink 提供了 Java 和 Scala 这两种 API,但这对于业务人员而言依然是不够的,因为业务大部分是 Go 语言系或者 Python 语言系的,因此滴滴希望根据社区来提供多语言的开发 Flink 的能力,比如写 SQL,而 UDF 也可以通过多语言来开发。
▍未来规划

提供高可用的流计算服务:使 Flink 具备支持完整线上业务能力的机制。
探索实时机器学习:借助 Flink 已经具备了10-15分钟的模型更新能力,接下来希望实现秒级别的模型更新。
实时数仓:目前的数仓系统大部分还是 T+1 级别,如何构建实时数仓,得到实时化报表,同时口径和离线保持一致,实现实时数据和离线数据互补。例如最长保存3个月的实时存储系统在3个月后将数据搬至离线仓库时,和离线产生数据保持一致,是一个较大的挑战和希望。
内容来源:Flink Forward ASIA
文章首发:DataFunTalk
作者简介
▬
滴滴出行大数据架构部负责人。十年大数据实践经验,曾在阿里巴巴负责 Hadoop 集群及图计算研发工作。对分布式计算和分布式存储有深入研究。团队招聘▬
欢迎对大数据底层引擎(如 Spark、Flink 等)有研究和实践经验的工程师/专家加入滴滴大数据架构部,一起面对互联网+出行行业的每天万亿级海量数据处理挑战。
投递邮箱 | [email protected]
邮件主题请命名为「姓名+应聘部门+应聘方向」
推荐阅读
▬
更多推荐
▬
滴滴开源 / Open Source
Nightingale | FastLoad | Levin | AoE | Delta | Mpx | Booster | Chameleon | DDMQ | DroidAssist | Rdebug | Doraemonkit | Mand Moblie | virtualApk | 获取更多项目
技术干货 / Recommended article
浅谈滴滴派单算法 | 滴滴业务研发的精益实践 | 滴滴正式发布开源客户端研发助手DoKit 3.0,新特性解读
