Prometheus (五)配置和启动Prometheus
配置Prometheus

Global
配置的第一部分是global,它包含了控制Prometheus服务器行为的全局配置。
第一个参数scrape_interval用来指定应用程序或服务抓取数据的时间间隔(在示例中是15秒)。这个值是时间序列的颗粒度,即该序列中每个数据点所覆盖的时间段。
参数evaluation_interval用来指定Prometheus评估规则的频率。
目前主要有两种规则:
记录规则(recording rule)和警报规则(alerting rule)。
- 记录规则:允许预先计算使用频繁且开销大的表达式,并将结果保存为一个新的时间序列数据。
- 警报规则:允许定义警报条件。
根据这个参数,Prometheus将每隔15秒(重新)评估这些规则。
Alerting
Alerting用来设置Prometheus的警报。警报是由名为Alertmanager的独立工具进行管理的。Alertmanager是一个可以集群化的独立警报管理工具。

在默认配置中,alerting部分包含服务器的警报配置,其中alertmanagers块会列出Prometheus服务器使用的每个Alertmanager,static_configs块表示我们要手动指定在targets数组中配置的Alertmanager。
Rule_files
配置的第三部分是rule_files,它用来指定包含记录规则或警报规则的文件列表。
Scrape_Configs
配置的最后一部分是scrape_configs,用来指定Prometheus抓取的所有目标。
Prometheus将它抓取的指标的数据源称为端点。为了抓取这些端点的数据,Prometheus定义了一个目标,这个目标里包含的信息是抓取数据所必需的,比如用到的标签、建立连接所需的身份验证,或者其他定义数据抓取的信息。若干目标构成的组称为作业,作业里每个目标都有一个名为实例(instance)的标签,用来唯一标识这个目标。

默认配置中定义了一个作业prometheus,它的static_configs参数部分列出了抓取的目标,这些特定的目标被单独列出来,而不是通过自动服务发现。你也可以将静态配置理解为手动或人工服务发现。
作业prometheus只有一个监控目标:Prometheus服务器自身。它从本地的9090端口抓取数据并返回服务器的健康指标。Prometheus假设抓取的指标将返回到/metrics路径下,因此它会被追加到目标中然后抓取地址http://localhost:9090/metrics。
启动Prometheus
启动

第一个指标
现在服务器已经开始运行了,我们来看看正在抓取的端点和一些原始的Prometheus指标。为此,我们可以浏览http://localhost:9090/metrics并查看返回的内容。
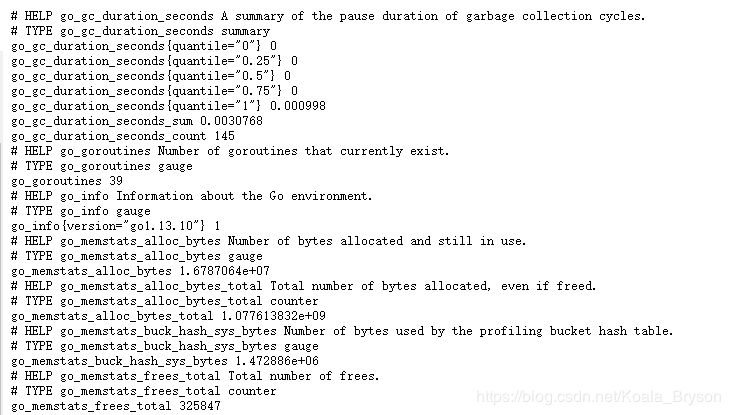
go_gc_duration_seconds{quantile="0.5"} 0
这个指标的名称是go_gc_duration_seconds,里面有一个标签quantile=“0.5”,表示这衡量的是第50百分位数,后面的数字是这个指标的值。
表达式浏览器
由于上述查看指标的方式对用户不是很友好,所以我们可以使用Prometheus的内置表达式浏览器来查看,其可通过在Prometheus服务器上浏览http://localhost:9090/graph来获得。

指标列表

在这个指标列表中,每个指标都使用一个或多个标签来进行描述,我们需要找到表示第50百分位数的标签。

我们可以看到两个新标签已添加到指标上,这是Prometheus在抓取过程中自动完成的。第一个新标签instance是我们抓取指标的目标,第二个标签job则是抓取指标的作业名称。标签为指标提供了不同的维度,允许我们查询或使用单个/多个指标。
prometheus_build_info

时间聚合序列
在上述查询界面中还可以进行指标的复杂聚合。我们选择另一个指标promhttp_metric_handler_requests_total来看一下,它是Prometheus服务器中抓取数据所产生的HTTP请求总数。

查询结果会返回一个HTTP请求指标列表,但我们真正想要的是每个作业的HTTP请求总数,为此,我们需要通过查询语句来创建新的指标。
让我们从按作业汇总HTTP请求开始。将以下内容添加到查询框中,然后单击Execute。
这个查询使用了promhttp_metric_handler_requests_total指标的sum()运算符[插图],它对所有请求进行累加,但没有按作业分类。为此,我们需要根据特定的标签维度进行聚合。PromQL有一个子句by,它允许按特定维度聚合。将以下内容添加到查询框中,然后单击Execute。

容量规划
Prometheus的性能很难估计,因为它在很大程度上取决于你的配置、所收集的时间序列的数量以及服务器上规则的复杂性。一般容量规划关注两个问题:内存和磁盘。
内存
Prometheus在内存中做了很多工作。每个收集的时间序列、查询和记录规则都会消耗进程内存。关于Prometheus的容量规划的参考数据并不多(特别是自2.0版本发布以来),但一个有用的、粗略的经验法则是将每秒采集的样本数乘以样本的大小。我们可以使用以下查询语句来查看样本收集率。
rate(prometheus_tsdb_head_samples_appened_total(1m))

这将显示你在最后一分钟添加到数据库的每秒样本率。如果想知道收集的指标数量,则可以使用以下语句:
sum(count by (_name_)({_name_=\~"\.\+"}))
这里使用sum聚合来计算所有匹配的指标的计数和,使用=~运算符和.+的正则表达式来匹配所有指标。每个样本的大小通常为1到2个字节,让我们谨慎一点,按照2个字节计算。假设在12小时内每秒收集100000个样本,那我们可以像下面这样计算内存使用情况:
100000 * 2 bytes * 43200 seconds
结果大概是8.64GB的内存。
你还需要考虑在查询和记录规则方面的内存使用情况。这个不太好计算,并且依赖于许多其他变量,建议根据内存使用情况灵活调整。你可以通过检查process_resident_memory_bytes指标来查看Prometheus进程的内存使用情况。
磁盘
磁盘使用量受存储的时间序列数量和这些时间序列的保留时间限制。默认情况下,指标会在本地时间序列数据库中存储15天。数据库的位置和保留时间由命令行选项控制。
-
–storage.tsdb.path选项:它的默认数据目录位于运行Prometheus的目录中,用于控制时间序列数据库位置。
-
–storage.tsdb.retention选项:控制时间序列的保留期。默认值为15d,代表15天。
对于每秒10万个样本的示例,我们知道按时间序列收集的每个样本在磁盘上占用大约1到2个字节。假设每个样本有2个字节,那么保留15天的时间序列意味着需要大约259 GB的磁盘。
age.tsdb.retention选项:控制时间序列的保留期。默认值为15d,代表15天。
对于每秒10万个样本的示例,我们知道按时间序列收集的每个样本在磁盘上占用大约1到2个字节。假设每个样本有2个字节,那么保留15天的时间序列意味着需要大约259 GB的磁盘。