干货 | Spark 2.4 高阶函数介绍
Apache Spark 2.4 在近期已经发布了(参见Apache Spark 2.4 正式发布,重要功能详细介绍),其中为我们带来了24个内置操作数组和 map 的函数,5个高阶函数。可以参见Apache Spark 2.4 中解决复杂数据类型的内置函数和高阶函数介绍。关于这新引入的29个内置函数和高阶函数介绍可以参见(点击下面 阅读原文 即可进入)
https://www.iteblog.com/archives/2459.html
本文来自2018年在伦敦举行的Spark+AI Summit Europe。本次会议全部PPT可以到下面地址下载
https://www.iteblog.com/archives/2432.html
本文配套视频
由于微信公众号的限制,需要高清(720p)的视频可以到下面地址下载:
http://cdn.iteblog.com/sparksummit2018/an-introduction-to-higher-order-functions-in-spark-sql-with-herman-van-hovell-iteblog.mp4(强烈推荐)
https://www.iteblog.com/sparksummit2018/an-introduction-to-higher-order-functions-in-spark-sql-with-herman-van-hovell-iteblog.mp4(不推荐)
好了,废话不多说,开始上车吧。

Spark SQL 中存在各种各样的复杂数据类型,比如 Struct、Array、Map等。有了复杂数据类型,我们可以构建比较复杂的数据对象,而且这看起来更加自然,和真实的数据模型很像。

正如上面的 Json 字符串,我们直接可以使用结构体表示。

但是复杂类型的数据操作比较复杂,比如难以改造或汇总。

比如我们想对上面数组 vals 里面的元素加一操作,我们该如何做?

我们会使用到 explode 和 collect 函数。

第一步我需要对数组进行 explode 操作
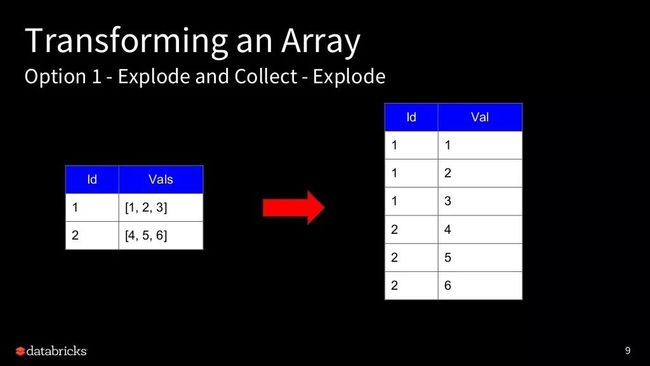
结果看起来就像上面一样

第二步需要使用 collect_list 将展开来的数组进行汇集

看起来就像上面一样,整个操作的物理计划如下所示


我们可以从物理计划看到有 hashpartitioning 操作,这也意味着需要进行 shuffle,而这个操作代价比较高。更重要的是, collect_list 汇集的数据不能保证原来的顺序。

如上,如果某个数组为 null,经过 collect_list 操作将消失了!

第二种方案就是我们可以使用 Scala 编写 UDF

然后再通过 spark.udf.register 注册刚刚编写的 UDF

这样我们就可以直接在 Spark DSL 中使用这个已经注册的 UDF

Scala UDF 的优点是:
它比 explode 和 Collect 快
可以避免很多陷阱
缺点是:
这种写法也会比较慢,因为我们需要进行许多序列化工作
针对每种类型,我们都需要注册相应的 UDF
SQL 中无法使用
笨重


让我们再以另外一个视角看看 Scala UDF

map 函数其实是个高阶函数

里面的 value => value + 1 其实是 lambda 函数。我们是否可以在 Spark SQL 中实现这些事情?

Spark SQL 是最原生的代码,而且不需要序列化。我们可以直接在 SQL 中使用它。

transform就是我们要的高阶函数,他可以使用给定函数转换数组中的元素。详情参见https://www.iteblog.com/archives/2459.html#transform。

val -> val + 1 就是 lambda 函数。他可以对数组里面的每个元素执行相关的操作。这个函数包含两部分:
参数列表
计算新值得表达式

它还支持操作嵌套类型的数据,甚至引用外部的值。

那么这种方式到底有多快,我们来和前面的方式对比一下吧。

从上图可以看到,高阶函数性能可以吊打 explode 加 collect 的方式,也比 UDF 方式要快。

其实 Spark 2.4 带来了5个高阶函数,24个内置用来操作数组和map的函数,可以参见。

目前数组和map实现了很多很实用的函数,但是struct目前还做的不够好。在未来,我们还有许多要做的:
以下数据集函数应适用于嵌套字段:
-
withColumn()
withColumnRenamed()
以下函数应该适用于struct里面的字段
-
select()
withColumn()
withColumnRenamed()
本文 PPT可以通过下面方式下载:
https://www.iteblog.com/sparksummit2018/an-introduction-to-higher-order-functions-in-spark-sql-with-herman-van-hovell-iteblog.pdf(不推荐)
http://cdn.iteblog.com/sparksummit2018/an-introduction-to-higher-order-functions-in-spark-sql-with-herman-van-hovell-iteblog.pdf(推荐)
欢迎关注本公众号:iteblog_hadoop:
回复 spark_summit_201806 下载 Spark Summit North America 201806 全部PPT
回复 spark_summit_eu_2018 下载 Spark+AI Summit europe 2018 全部PPT
0、回复 电子书 获取 本站所有可下载的电子书
1、Apache Spark 统一内存管理模型详解
2、Elasticsearch 6.3 发布,你们要的 SQL 功能来了
3、即将发布的 Apache Spark 2.4 都有哪些新功能
4、干货 | 深入理解 Spark Structured Streaming
5、Apache Spark 黑名单(Blacklist)机制介绍
6、Kafka分区分配策略(Partition Assignment Strategy)
7、Spark SQL 你需要知道的十件事
8、干货 | Apache Spark 2.0 作业优化技巧
9、[干货]大规模数据处理的演变(2003-2017)
10、Flink Forward 201809PPT资料下载
11、更多大数据文章欢迎访问https://www.iteblog.com及本公众号(iteblog_hadoop) 12、Flink中文文档: http://flink.iteblog.com 13、Carbondata 中文文档: http://carbondata.iteblog.com