史上最全Java工程师知识体系-面试必备
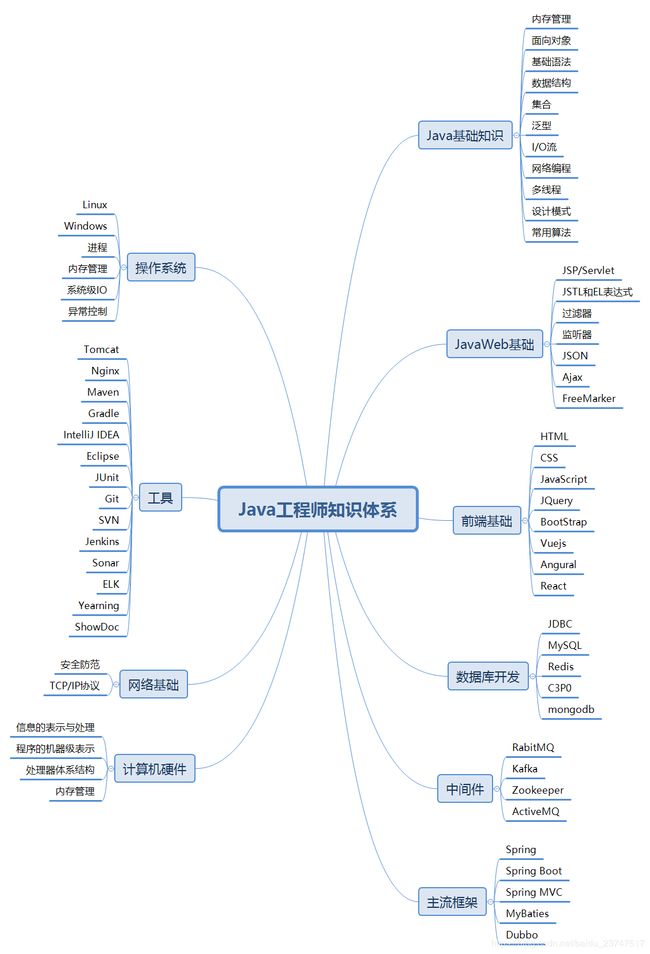
Java工程师知识体系
- 欢迎阅读Java工程师知识体系文章
- 硬件基础
- 程序的机器级表示
- 程序编码
- 数据格式
- 访问信息
- 内存管理
- 虚拟内存
- 动态分配内存
- 垃圾收集
- 操作系统
- Linux基础
- Windows基础
- 进程
- 内存管理
- 系统级I/O
- 异常控制
- 网络基础
- TCP/IP协议
- 安全防护
- Java基础
- 内存管理
- JVM内存模型
- 垃圾回收机制
- 面向对象
- 对象的概念
- 基础语法
- 数据结构
- 集合
- 泛型
- I/O流
- 网络编程
- 多线程
- 设计模式
- 常用算法
- Java Web基础
- JSP/Servlet
- JSTL和EL表达式
- 过滤器
- 监听器
- JSON
- Ajax
- FreeMarker
- 前端基础
- HTML
- CSS
- JavaScript
- JQuery
- Bootstrap
- Vuejs
- Reactjs
- Angular
- 数据库开发
- JDBC
- MySQL
- Redis
- C3P0
- MongoDB
- 中间件技术
- RabbitMQ
- Kafka
- Zookeeper
- ActiveMQ
- 主流框架
- Spring
- Spring MVC
- Spring Boot
- Spring Cloud
- MyBatis
- Dubbo
- 工具与工程化
- Nginx
- Tomcat
- Maven
- Gradle
- Git
- IntelliJ IDEA
- Eclipse
- JUnit
- SVN
- Jenkins
- Sonar
- ELK
- Yearning
- ShowDoc
- 禅道
欢迎阅读Java工程师知识体系文章
曾经多次想过梳理Java工程师知识体系,但一直以来都没有实践,理由很多:1.没时间,天天工作还得加班;2.太累,工作加上基本生活劳动;3.拿来主义,网上有很多牛人整理过了搜索一下就可以获得等等,可是终究还是无法抗拒内心的欲望,勇敢开始了这第一步。这是我第一次落实整理 Java工程师知识体系 ,欢迎阅读,如有纰漏欢迎指正,如有疑问欢迎留言交流。
硬件基础

程序的机器级表示
程序编码
在《【深入理解计算机系统·笔记】GCC编译过程理解》一文中已详细讲解过如何获取C语言文件的预编译文件、汇编文件、机器码文件,这里我们需要使用到汇编文件,因此需要用到的命令是:
gcc -S xxx.c -o xxx.s
另外还可以加入-Og 选项(GCC 4.8以上版本支持)来告诉编译器生成符合原始C代码整体结构的及其代码的优化等级,使用较高级别优化产生的代码会严重变形,以至于难以理解,因此我们使用-Og优化级别作为学习工具,其他-O1,-O2是较高级别的优化,在编译实际使用的程序时比较推荐。例如:
gcc -Og -S xxx.c -o xxx.s
注:汇编语言只是一种助记符,如需变成可执行的机器码,还需要经过汇编、链接操作。
首先我们再来看一个简单的C程序addtwonum.c:
#include 程序编写了一个函数addtwonum(),对两个整型数进行求和,在执行以下命令后:
gcc -Og -S addtwonum.c -o addtwonum.s
我们得到如下文件内容,其中以“.”开头的行都是指导汇编器和链接器工作的伪指令,其他的每一行都是一条可执行指令的汇编表示:
.file "addtwonum.c"
.text
.globl addtwonum
.type addtwonum, @function
addtwonum:
.LFB11:
.cfi_startproc
movl $1, x(%rip)
movl $2, y(%rip)
movl $3, %eax
ret
.cfi_endproc
.LFE11:
.size addtwonum, .-addtwonum
.section .rodata.str1.1,"aMS",@progbits,1
.LC0:
.string "result \344\270\272\357\274\232 %d"
.LC1:
.string "x \344\270\272\357\274\232 %d"
.LC2:
.string "y \344\270\272\357\274\232 %d"
.text
.globl main
.type main, @function
main:
.LFB12:
.cfi_startproc
subq $8, %rsp
.cfi_def_cfa_offset 16
movl $0, %eax
call addtwonum
movl %eax, %esi
movl $.LC0, %edi
movl $0, %eax
call printf
movl x(%rip), %esi
movl $.LC1, %edi
movl $0, %eax
call printf
movl y(%rip), %esi
movl $.LC2, %edi
movl $0, %eax
call printf
movl $0, %eax
addq $8, %rsp
.cfi_def_cfa_offset 8
ret
.cfi_endproc
.LFE12:
.size main, .-main
.comm y,4,4
.comm x,4,4
.ident "GCC: (GNU) 4.8.5 20150623 (Red Hat 4.8.5-39)"
.section .note.GNU-stack,"",@progbits
另外如果您已有一个机器码文件,通常是“.o”为后缀的文件,您也可以使用反汇编器来获取汇编文件,Linux系统常用的反汇编工具是OBJDUMP,将addtwonum.o反汇编的命令如下:
objdump -d addtwonum.o
addtwonum.o: 文件格式 elf64-x86-64
Disassembly of section .text:
0000000000000000 <addtwonum>:
0: c7 05 00 00 00 00 01 movl $0x1,0x0(%rip) # a 文件的最左侧是命令行索引号,十六进制数字是对应汇编代码的机器码指令,最右边才是汇编代码,这时我们得到的汇编代码与使用GCC汇编命令产生的汇编代码有所差异,“call”和“ret”指令后面多了“q”,这个“q”是大小写指示符,在大多数情况下可以省略。
数据格式
由于最初是从16位系统结构发展成为32位以及后来的64位的,Intel用术语“字(word)”表示16位数据类型,称32位数为“双字(duoble words)”,64位数为“四字(quad words)”。下表给出x86-64系统中C语言基本数据类型的表示。
| C声明 | Intel数据类型 | 汇编代码后缀 | 大小(字节) |
|---|---|---|---|
| char | 字节 | b | 1 |
| short | 字 | w | 2 |
| int | 双字 | l | 4 |
| long | 四字 | q | 8 |
| char* | 四字 | q | 8 |
| float | 单精度 | s | 4 |
| double | 双精度 | l | 8 |
大多数GCC生成的汇编代码指令都有一个字符的后缀,表明操作数的大小,例如,数据传送指令有四种变种:movb(传送字节),movw(传送字),movl(传送双字),movq(传送四字)。
访问信息
在汇编语言中,汇编指令之后很多类似“%rsp”,“%eax”以及“$0x8”格式的内容,这些内容的具体含义是什么呢?
指令后带“%”的都是指计算机系统的寄存器,在X86-64的中央处理单元(CPU)中,有16个64位通用目的寄存器,这些寄存器用来存储整数数据和指针,所有寄存器名字如下表,其%ax到%sp的8个16位寄存器是8086系统中的寄存器,从%eax到%esp的8个32位寄存器是IA32架构系统的寄存器,从%rax到%r15的16个64位寄存器才是X86-64处理器的寄存器。新一代寄存器对老的寄存器是兼容的,当在高位寄存器系统中运行低位程序时,寄存器对应的低位位置会被使用,高位自动填充0。

除了带“%”号的内容,我们还看到其他格式的数据,其含义如下:

想要更详细的了解汇编语言,请查看其它资料
内存管理
虚拟内存
在计算机系统中进程与其他进程共享CPU和主存,因此存在一个进程写了另一个进程的内存问题,这会引发令人迷惑的错误。为了有效的管理内存并减少出错,现代系统提供了一种对主存的抽象概念——虚拟内存。
虚拟内存三个重要能力:
(1)将主存视为磁盘空间的高速缓存,在主存中只保存活动区域,并根据需要在磁盘和主存间来回传送数据,高效利用主存;
(2)为每个进程提供一致的地址空间,屏蔽了对硬件操作管理的细节,简化了内存管理;
(3)保护每个进程的地址空间不被其他进程破坏。
传统的物理寻址

应用范围:早期的PC、数字信号处理器、嵌入式微控制器、Cray超级计算机等。
现代的虚拟寻址
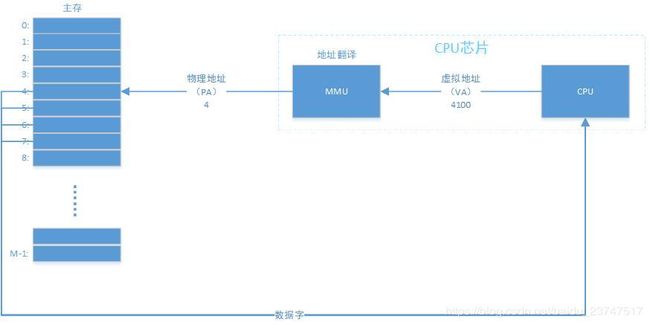
应用范围:现代计算机系统
虚拟地址与物理地址之间的映射关系:

多个虚拟地址可以指向同一个物理地址,这样共享内存就变得很容易了。
一些重要概念
DRAM缓存:指虚拟内存系统的缓存,它在主存中缓存虚拟页。
SRAM缓存:指CPU与主存之间的L1/L2/L3高级缓存。
页表:常驻内存主要是用来标识(PTE位)虚拟页是否已缓存到DRAM的数组。
页命中:目标地址的虚拟页已被缓存至内存中,通过目标地址能够找到已被缓存的虚拟页被称之为页命中。
缺页:DRAM缓存不命中称为缺页,缺页会抛出缺页异常,缺页异常又会触发异常处理程序去选中一个牺牲页,并从磁盘复制所需虚拟页去替换牺牲页。
分配页面:操作系统分配一个新的虚拟页给程序的过程,例如,调用malloc函数,操作系统首先会为程序在磁盘创建一个虚拟页,并更新页表内容,让其中一个页表条目指向这个磁盘虚拟页。
局部性:局部性原则的含义是CPU要执行的命令往往就在局部范围内,这样就保证了程序在任意时刻都趋于在一个较小的活动页面集合上工作,从而避免了大概率的缺页。只要程序有好的时间局部性,虚拟内存系统就能够很好的工作。如果程序的工作集大小超过了物理内存的大小,就会频繁发生页面的换进换出(称之为抖动),程序运行就会变得很慢。
虚拟内存作为缓存的工具
对应存储层的分块的概念,VM系统将虚拟内存也按固定大小分割为虚拟页(VP),对应的物理内存被分割为物理页(PP),物理页也称之为页帧。
虚拟页任何时刻都被分为三个不相交的子集:
(1) 未分配的:VM系统还未分配(未创建)的页,没有任何数据与之相关联,因此不占用任何磁盘空间。
(2) 未缓存的:已被创建的虚拟页,但是还没有缓存到物理内存。
(3) 已缓存的:已被创建并被缓存到物理内存中的虚拟页。
虚拟内存作为内存管理工具
在《【深入理解计算机系统·笔记】计算机系统中的重要概念》笔记中描述过计算机系统中一些重要的抽象概念,虚拟内存也是计算机中核心的抽象概念。早期的虚拟地址比物理地址要少,那时虚拟内存主要是为内存管理提供支撑。在内存管理方面,虚拟内存的出现主要起到以下作用:
1.简化链接:独立的虚拟地址空间允许每一个进程的内存映像使用相应的基本格式,而不用去管代码和数据实际存放在物理内存的何处。
2.简化加载:上文示例过系统在分配页面时,malloc函数只是在磁盘创建了虚拟页,然后让页表指向虚拟页,并未立即将虚拟页缓存至物理内存,只有当页面第一次被引用时,CPU发起取指引用后才虚拟内存才会按需调入数据页,这样可以有效提高物理内存的使用效率。另外虚拟内存允许将一组连续的虚拟页映射到任意一个文件中的任意位置,这也被称之为内存映射,Linux系统提供的mmap函数就是做内存映射工作的。
3.简化共享:前面也讲到多个虚拟地址可以指向同一个物理地址,这样就能很方便多个进程共享物理内存了。
4.简化内存分配:连续的虚拟内存对应的物理内存可以是不连续的,虚拟内存为用户进程提供了一个简单的分配额外内存的机制。
虚拟内存作为内存保护工具
任何现代计算机系统必须为操作系统提供手段来控制对内存系统的访问,不应该允许用户进程去修改它的的只读代码段,而且也不允许它读取或修改任何内核中的代码和数据结构。也不允许它读或写其他进程的私有内存。虚拟内存提供的独立地址空间将这些需求变得很容易。
动态分配内存
虽然可以在运行前使用低级的mmap和munmap来创建和删除虚拟内存的区域,但是我们也会在运行时获取额外虚拟内存,这是就需要用到动态内存分配器。
动态内存分配器维护着一个进程的虚拟内存区域,我们通常称之为堆(heap),分配器将堆视为一组不同大小的块(block)的集合,每个块中是一个连续的虚拟内存片(chunk),要么是已分配,要么是空闲的。已分配的显式地保留给应用程序使用,空闲的块可以用来分配。一个已分配的块保持自己已分配的状态,直到它被释放,要么是程序自己释放(C语言中调用free函数),要么是内存分配器自身隐式释放(Java中的垃圾回收器)。
因此内存分配器分为显示分配器和隐式分配器,C标准库提供malloc和free函数,以及C++中的new和delete都是属于显式分配,而Lisp、ML及Java语言的垃圾回收器就是隐式分配器。
动态分配器的要求
- 处理任意请求序列:一个应用可以有任意的分配请求和释放请求序列,只要满足约束条件:每个释放的请求必须对应一个已分配的块。
- 立即响应请求:分配器必须立即响应分配请求,因此不允许分配器为了提高性能重新排列或者缓冲请求。
- 只使用堆:为了使分配器是可扩展的,分配器使用的任何非标量数据结构都必须保存在堆里。
- 对齐块:分配器必须对齐块,使得它们可以保存任何类型的数据对象。
- 不修改已分配的块:分配器只能操作或者改变空闲块,特别是,一旦块被分配了,就不允许修改或移动它了。因此,压缩已分配的块的技术是不被允许的。
动态分配器的目标
1.最大化吞吐率:分配器的吞吐率是指每时间单位可处理的请求次数(包含分配和释放请求)。
2.最大化内存利用率:一个系统中被所有进程分配的虚拟内存的全部数量时受磁盘上交换空间的数量限制的。虚拟内存是一个有限的空间,必须高效利用才能让其发挥最大的价值。
垃圾收集
在诸如C malloc包这样的显式分配器中,应用通过调用malloc和free函数来分配或释放堆块,应用需要负责释放所有不在需要的已分配的块。未能释放已分配的块是一种常见的编程错误。
而垃圾收集器是一种动态内存分配器,它自动释放程序不再需要的已分配块。这些块被称为垃圾(garbage),垃圾收集最早可追溯到John McCarthy在20世纪60年代早期在MIT开发的Lisp系统,后来成为Java、ML、Perl等现代语言重要的一部分。
垃圾收集器将内存视为一张有向可达图,该图的节点被分成一组根节点(root node)和一组堆节点(heap node),每个堆节点对应于堆中的一个已分配的块,根节点对应于这样一种不在堆中的位置,它们包含指向堆节点的指针,这些位置可以是寄存器、栈里的变量、或者是虚拟内存中读写数据区域内的全局变量。

操作系统
Linux基础
Windows基础
进程
内存管理
Linux虚拟内存系统
虚拟内存系统要求硬件和内核软件之间需要紧密协作。

Linux将虚拟内存组织成一些区域(也称为段),一个区域(area)就是已经存在着的(已分配的)虚拟内存的连续片(chunk),代码段、数据段、共享库、以及用户栈都是不同的区域。每个存在着的虚拟页都保存在一个区域中,而不属于任意个区域的虚拟页是不存在,并且不能被进程引用。

Linux内核会为每一个进程维护一个单独的任务结构(task_struct),任务结构中包含的元素或指向内核运行该进程所需的信息(例如:PID,指向用户栈的指针,可执行目标文件的名字,以及程序计数器等)
想进一步了解任务结构的详细信息请进入Linux系统的sched.h文件,task_struct结构体的定义是在内核中的sched.h中,其路径一般在:/usr/src/kernels/x.xx.x-xxx.xx.x.xxx.x86_64/include/linux
任务结构中的一个条目指向mm_struct,它描述了虚拟内存的当前状态,重要的字段pdg和mmap ,pdg指向第一级页表的基址,而mmap指向一个vm_area_struct(区域结构)的链表,vm_area_struct描述了当前虚拟地址空间的一个区域。其中:
vm_end:指向所描述区域的结束位置;
vm_start:指向所描述区域的开始位置;
vm_prot:描述这个区域内包含所有页的读写许可权限;
vm_flags:描述这个区域的页面是否是与其他进程共享的,或者是私有的;
vm_next:指向链表中的下一个区域结构。
系统级I/O
异常控制
网络基础
TCP/IP协议
安全防护
Java基础
内存管理
JVM内存模型
JVM对内存的管理是基于计算机系统的虚拟内存的,相关虚拟内存知识请查看以下目录内容:
1.【硬件基础】–>【内存管理】–>【虚拟内存】
2.【操作系统】–>【内存管理】–>【Linux虚拟内存系统】

堆(Heap):对于绝大多数应用来说,这块区域是 JVM 所管理的内存中最大的一块。这块区域是线程共享的,主要存放对象实例和数组(目前由于编译器的优化,对象在堆上分配已经没有那么绝对了,参见:https://www.cnblogs.com/aiqiqi/p/10650394.html)。内部会划分出多个线程私有的分配缓冲区。可以位于物理上不连续的空间,但是逻辑上(虚拟内存)要连续。
方法区(Method Area):属于共享内存区域,存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
本地方法栈(Native Method Stack):区别于Java 虚拟机栈的是,Java 虚拟机栈为虚拟机执行 Java 方法(也就是字节码)服务,而本地方法栈则为虚拟机使用到的 Native 方法服务。方法执行完毕后相应的栈帧也会出栈并释放内存空间,也会出现 StackOverFlowError 和 OutOfMemoryError 两种异常。
虚拟机栈(VM Stack):线程私有,生命周期和线程一致。每个方法在执行时都会创建一个栈帧(Stack Frame)用于存储局部变量表、操作数栈、动态链接、方法出口等信息。每一个方法从调用直至执行结束,就对应着一个栈帧从虚拟机栈中入栈到出栈的过程。局部变量表主要存放了编译器可知的各种基本数据类型(boolean、byte、char、short、int、float、long、double)和对象引用(reference类型,它不同于对象本身,可能是一个指向对象起始地址的引用指针,也可能是指向一个代表对象的句柄或其他与此对象相关的位置)
Java 虚拟机栈会出现两种异常:StackOverFlowError 和 OutOfMemoryError。
StackOverFlowError:若Java虚拟机栈的内存大小不允许动态扩展,那么当线程请求栈的深度超过当前Java虚拟机栈的最大深度的时候,就抛出StackOverFlowError异常。
OutOfMemoryError:若 Java 虚拟机栈的内存大小允许动态扩展,且当线程请求栈时内存用完了,无法再动态扩展了,此时抛出OutOfMemoryError异常。
程序计数器(PC):存储指令地址,顺序执行时自动加1,或由转移指令指定需要转去的指令地址,与线程一一对应,程序计数器是唯不会出现 OutOfMemoryError 的内存区域。程序计数器是一块较小的内存空间,可以看作是当前线程所执行的字节码的行号指示器。字节码解释器工作时通过改变这个计数器的值来选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复等功能都需要依赖这个计数器来完。
垃圾回收机制
哪些对象属于垃圾?JVM提供了一些算法去判定,常见的判定方法有:引用计数法和可达性分析。
- 引用计数法
JVM为每一个已创建的对象分配一个引用计数器,用来存储该对象被引用的个数,当被引用的个数为0时,意味着该对象已没被使用,即可当做“垃圾”,而当有位置引用它时,引用计数器加1,不再引用时将引用计数器减1。这种算法存在一个弊端,那就是无法检测“循环引用”,即两个对象相互引用,它们的引用计数都不为0,因此无法回收,实际上这两个对象已没有其他位置引用,是可以释放的对象。该方法并没有被Java采用。

- 可达性分析
可达性分析基本思路是把所有引用的对象想象成一棵树,从树的根结点 GC Roots 出发,持续遍历找出所有被连接的对象,这些对象则被称为“可达”对象,或称“存活”对象。不能到达的则被视为“垃圾”,成为可回收对象。

GC Roots对象(非堆对象)的位置:
(1).虚拟机栈中引用的对象;
(2).方法区中静态属性引用的对象;
(3).方法区中常量引用的对象;
(4).本地方法栈中JNI引用的对象;