概念
1。目的
Micrometer是基于JVM的应用程序的metrics 工具库。它为最流行的监控系统的仪器客户端提供了一个简单的外观,使您无需锁定供应商即可测试基于JVM的应用程序代码。它旨在为您的指标收集活动增加很少或没有开销,同时最大限度地提高指标工作的可移植性。
Micrometer不是分布式追踪系统或事件记录器。Adrian Cole关于Observationbility 3 Ways的演讲在突出这些不同类型系统之间的差异方面做得非常出色。
2.支持的监控系统
Micrometer包含一个带有仪器SPI的核心模块,一套包含各种监测系统(每个称为注册表)的模块和一套测试工具。监控系统有三个重要特征,重要的是要了解:
·
Dimensionality。系统是否支持使用标记键/值对丰富的metric 标准名称。如果一个系统不是三维的,它是分层的,这意味着它只支持一个统一的metric 名称。将Micrometer 标准发布到分层系统时,Micrometer会将这组标签/键值对变平并将其添加到名称中。
·
| Dimensional |
Hierarchical |
| Atlas, Datadog, Datadog StatsD, Influx, Prometheus, SignalFx, Telegraf StatsD, Wavefront |
Graphite, Ganglia, JMX, Etsy StatsD |
·
Rate aggregation 在这种情况下,我们是指在规定的时间间隔内聚集一组样本。一些监测系统希望某些类型的离散样本(如计数)在发布前由应用程序转换为费率。有些人希望始终发送累积值。还有一些人对此没有任何意见。
·
| 客户端(Client-side) |
服务器端(Server-side) |
| Atlas, Datadog, Influx, Graphite, Ganglia, JMX, all StatsD flavors, SignalFx, Wavefront |
Prometheus |
·
Publishing 一些系统希望在应用程序中随时检查应用程序的指标,另一些系统则希望定期将指标推送给它们。
·
| 客户端推送(client pushes) |
服务器检查(Server polls) |
| Atlas, Datadog, Graphite, Ganglia, Influx, JMX, all StatsD flavors, SignalFx, Wavefront |
Prometheus |
从一个监控系统到另一个监控系统的预期还有其他更小的变化,比如他们对基本计量单位(特别是时间)的概念和度量标准的规范命名惯例。Micrometer 自定义您的指标以满足这些需求,并在每个注册表的基础上。
3.注册表
一个Meter是用于收集关于您的应用程序的一组度量(我们个别称为度量(metrics))的接口。Micrometer 中的Meters 由一个创建并保存MeterRegistry。每个支持的监控系统都有一个实现MeterRegistry。注册表的创建方式因每个实现而异。
Micrometer 打包内含SimpleMeterRegistry每个meter 的最新值,不会将数据导出到任何地方。如果您还没有首选的监控系统,则可以使用简单的注册表开始玩指标:
MeterRegistry registry = new SimpleMeterRegistry();
| 注意 |
A SimpleMeterRegistry在基于Spring的应用程序中为你自动装配。 |
3.1。Composite 注册
Micrometer 提供了一个CompositeMeterRegistry可添加多个注册表的程序,允许您将metrics 标准同时发布到多个监视系统。
CompositeMeterRegistry composite = new CompositeMeterRegistry();
Counter compositeCounter = composite.counter("counter");
compositeCounter.increment(); (1) SimpleMeterRegistry simple = new SimpleMeterRegistry(); composite.add(simple); (2)
compositeCounter.increment(); (3)
1、直到组合中存在注册表为止,递增才是NOOPd。此时计数器的计数仍然为0。
2、名为“计数器”的计数器已注册到简单注册表。
3、简单的注册表计数器会与组合中的任何其他注册表的计数器一起递增。
3.2。全局注册表
Micrometer提供了一个静态全局注册表Metrics.globalRegistry和一组静态构建器,用于基于此注册表生成计量表。globalRegistry是一个组合注册表。
class MyComponent {
Counter featureCounter = Metrics.counter("feature", "region", "test"); (1)
void feature() {
featureCounter.increment();
}
void feature2(String type) {
Metrics.counter("feature.2", "type", type).increment(); (2)
}
}class MyApplication {
void start() {
// wire your monitoring system to global static state
Metrics.addRegistry(new SimpleMeterRegistry()); (3)
}
}
1、只要有可能(特别是仪器性能至关重要),请将Meter实例存储在字段中,以避免在每次使用时查看其名称/标签。
2、当标签需要从本地环境中确定时,您别无选择,只能在方法体内构建/查找仪表。查找代价只是单个哈希查找,所以对于大多数用途它都可以接受。
3、在米创建之后添加注册表是可以的Metrics.counter(…)。这些仪表将被添加到每个注册表中,因为它绑定到全局组合。
Meters
Micrometer 包与支持组Meter原语包括:Timer,Counter,Gauge,DistributionSummary,LongTaskTimer,FunctionCounter,FunctionTimer,和TimeGauge。不同的meter 类型会产生不同数量的时间序列metrics。例如,尽管只有一个metric 标准代表a Gauge,但a Timer度量了计时事件的计数和所有事件计时的总时间。
meter 由其名称和尺寸唯一标识。我们可以互换使用术语尺寸和标签,而Micrometer 接口Tag仅仅是因为它更短。作为一般规则,应该可以将名称用作枢轴。维度允许将特定的指定指标切片以深入挖掘并推理数据。这意味着如果只选择了名称,用户可以使用其他维度和关于所显示值的理由向下钻取。
5.命名meters
Micrometer 采用命名约定,用'.'分隔单词。(点).由于不同的监控系统对命名约定有不同的建议,某些命名约定可能实际上是针对一个系统而非另一个系统的,所以每个用于监控系统的Micrometer 实施都会包含一个命名约定,该约定将点符号名称转换为建议的命名约定。另外,这个命名约定实现清理了特定字符的名称和标签,这些特殊字符是为他们设计的监视系统所不允许的。如果您想通过NamingConvention在注册表中实现和设置注册表,您可以覆盖注册表的默认命名约定:
registry.config().namingConvention(myCustomNamingConvention);
使用命名约定后,在Micrometer 中注册的以下计时器在各种监控系统中本质上看起来不错:
registry.timer("http.server.requests");
1、Prometheus - http_server_requests_duration_seconds
2、Atlas - httpServerRequests
3、Graphite - http.server.requests
4、InfluxDB - http_server_requests
通过遵守Micrometer的点符号惯例,您可以保证监控系统中metric 标准名称的最大程度的可移植性。
5.1。标签命名
假设我们试图测量http请求的数量和数据库调用的数量。
推荐的方法
registry.counter("database.calls", "db", "users")
registry.counter("http.requests", "uri", "/api/users")
这个变体提供了足够的上下文,所以如果只选择了这个名字,这个值就可以被推理出来,并且至少具有潜在的意义。例如,如果我们选择,database.calls我们可以看到所有数据库调用的总数。然后我们可以进行分组或选择db进一步深入分析或对每个数据库调用的贡献进行比较分析。
糟糕的做法
registry.counter("calls",
"class", "database",
"db", "users");
registry.counter("calls",
"class", "http",
"uri", "/api/users");
在这种方法中,如果我们选择,calls我们将获得一个值,该值是对数据库和我们的API端点的调用次数的总和。如果没有进一步的维度挖掘,这个时间序列就没有用。
5.2。常见标签
通用标记可以在注册表级别定义,并添加到报告给监视系统的每个metric 标准中。这通常用于在主机,实例,区域,堆栈等操作环境上进行维度挖掘。
registry.config().commonTags("stack", "prod", "region", "us-east-1");
registry.config().commonTags(Arrays.asList(Tag.of("stack", "prod"), Tag.of("region", "us-east-1"))); // equivalently
调用commonTags附加其他通用标签。
| 重要 |
如果你在Spring环境中,通过添加一个MeterRegistryCustomizerbean来添加通用标签,以确保在自动配置仪表活页夹之前应用通用标签。 |
5.3。标记值
标记值必须是非空的。
| 警告 |
注意来自用户提供的源的标签值可能会导致度量标准的基数。您应该始终仔细规范并限制用户提供的输入。有时候,原因是偷偷摸摸的。考虑用于在服务端点上记录HTTP请求的URI标记。如果我们不将404的值限制为像NOT_FOUND这样的值,那么度量的维数将随着每个找不到的资源而增加。 |
6.Meter过滤器
每个注册表都可以配置仪表过滤器,使您可以更好地控制仪表注册的方式和时间以及它们发出的统计类型。仪表过滤器有三个基本功能:
Deny (拒绝/接受)meters 被注册。
Transform meter ID(例如更改名称,添加或删除标签,更改描述或基本单位)。
Configure 为某些电表类型配置分布统计。
MeterFilter以编程方式将注册表的实现添加到注册表中:
registry.config()
.meterFilter(MeterFilter.ignoreTags("too.much.information"))
.meterFilter(MeterFilter.denyNameStartsWith("jvm"));
Meter 过滤器是按顺序应用的,并且转换或配置仪表的结果是链接的。
6.1。拒绝/接受meters
接受/拒(accept/deny)绝过滤器的详细形式是:
new MeterFilter() {
@Override
public MeterFilterReply accept(Meter.Id id) {
if(id.getName().contains("test")) {
return MeterFilterReply.DENY;
}
return MeterFilterReply.NEUTRAL;
}
}
MeterFilterReply 有三种可能的状态:
DENY - 不要让这个仪表被注册。当您尝试在注册表中注册计量器并且过滤器返回DENY时,注册表将返回该计量器的NOOP版本(例如NoopCounter,NoopTimer)。您的代码可以继续与NOOP流量计进行交互,但记录的任何内容都会立即丢弃,并且花费最小。
NEUTRAL- 如果没有其他仪表过滤器返回DENY,则仪表正常注册。
ACCEPT- 如果过滤器返回ACCEPT,仪表立即注册,不询问任何其他过滤器的接受方法。
6.1.1。便利的方法
MeterFilter 为拒绝/接受类型过滤器提供了几种便利的静态构建器:
accept() - 接受每一个米,覆盖任何后续过滤器的决定。
accept(Predicate
acceptNameStartsWith(String) - 接受每个meter 的匹配前缀。
deny() - 拒绝每一个meter,覆盖任何后续过滤器的决定。
denyNameStartsWith(String) - 拒绝每一个具有匹配前缀的meter 。MeterBinder由Micrometer提供的所有开箱即用的实现都具有通用前缀的名称,以便在UI中进行简单的分组可视化,但也可以使它们作为具有前缀的组disable/enable 。例如,您可以拒绝所有JVM指标MeterFilter.denyNameStartsWith("jvm")
deny(Predicate
maximumAllowableMetrics(int) - 在注册表达到一定数量的meter 后拒绝任何计量器。
maximumAllowableTags(String meterNamePrefix, String tagKey, int maximumTagValues, MeterFilter onMaxReached) - 对由匹配系列产生的标签数量设置上限。
白名单仅对某组指标进行白名单是监视昂贵系统的一种特别常见的情况。这可以通过静态来实现:
denyUnless(Predicate
6.1.2。链接否认/接受meters
Meter 过滤器按照它们在注册表中配置的顺序进行应用,因此可以堆栈拒绝/接受(deny/accept)过滤器来实现更复杂的规则:
registry.config()
.meterFilter(MeterFilter.acceptNameStartsWith("http"))
.meterFilter(MeterFilter.deny()); (1)
这通过将两个滤波器堆叠在一起实现了另一种白名单形式。此注册表中只有“http”度量标准存在。
6.2。转换指标
转换过滤器如下所示:
new MeterFilter() {
@Override
public Meter.Id map(Meter.Id id) {
if(id.getName().startsWith("test")) {
return id.withName("extra." + id.getName()).withTag("extra.tag", "value");
}
return id;
}
}
该过滤器将名称前缀和附加标记有条件地添加到名称为“test”的仪表中。
MeterFilter 为许多常见的转换案例提供便利建造者:
commonTags(Iterable
ignoreTags(String…) - 从每个meter丢弃匹配的标签键。当标签明显变得过于高基数并开始压迫您的监控系统或花费太多时,这一点特别有用,但您无法快速更改所有检测点。
replaceTagValues(String tagKey, Function
renameTag(String meterNamePrefix, String fromTagKey, String toTagKey) - 为每个以给定前缀开头的度量重命名标签密钥。
6.3。配置分布统计
Timer并DistributionSummary含有除可通过过滤器进行配置数,总,和最大的基础一套可选的分布统计。这些分布统计信息包括预先计算的百分位数,SLA和直方图。
new MeterFilter() {
@Override
public DistributionStatisticConfig configure(Meter.Id id, DistributionStatisticConfig config) {
if (id.getName().startsWith(prefix)) {
return DistributionStatisticConfig.builder()
.publishPercentiles(0.9, 0.95)
.build()
.merge(config);
}
return config;
}
};
一般来说,你应该创建一个新DistributionStatisticConfig的只有你想要配置的部分,然后merge使用输入配置。这使您可以下载注册表提供的默认分布统计信息并将多个过滤器链接在一起,每个过滤器配置一些分布统计信息的一部分(例如,您可能希望所有http请求都有100ms的SLA,但只有几个关键的百分位直方图端点)。
MeterFilter 为以下方面提供便利建设者:
maxExpected(Duration/long) - 管理从计时器或摘要发送的百分位直方图桶的上限。
minExpected(Duration/long) - 管理从定时器或摘要发送的百分位直方图桶的下限。
Spring Boot提供基于属性的过滤器,用于按名称前缀配置SLA,百分位数和百分位柱状图。
7.速率聚合
Micrometer 知道特定的监控系统是否要求在指标发布之前发生客户端速率聚合,或者在服务器端作为查询的一部分进行临时性聚合。它根据监控系统预期的风格累积指标。
并不是所有的测量值都被报告或最好被视为一个速率。例如,量表值和长任务计时器活动任务不是速率。
7.1。服务器端
执行服务器端数学计算的监视系统期望在每个发布时间间隔报告绝对值。例如,自应用程序开始以来计数器的所有增量绝对计数均在每个发布时间间隔发送。
假设我们有一个稍微正偏向的随机游走,每10毫秒选择一次计数器。如果我们在像Prometheus这样的系统中查看原始计数器值,我们会看到逐步增加的单调递增函数(步长的宽度是Prometheus轮询或抓取数据的时间间隔)。
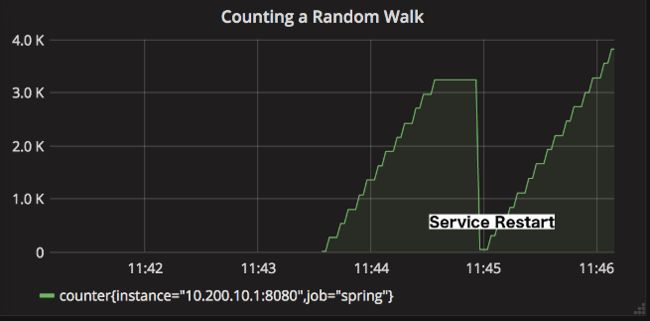
在某个时间窗口内表示没有汇率汇总的计数器很少有用,因为该表示是计数器递增的快速度和服务的寿命的函数。在我们上面的例子中,在服务重启时计数器会回落到零。只要新实例(比如生产部署)投入使用,汇率图就会返回到55左右的值。
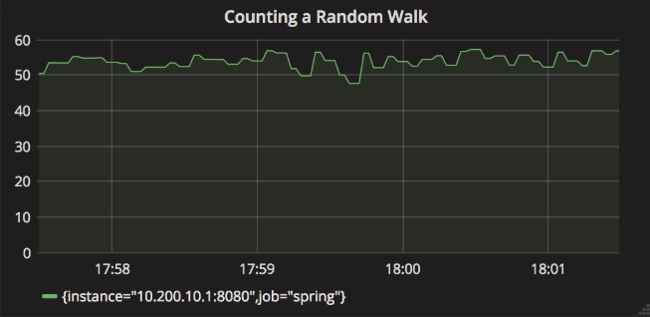
如果您已实现零宕机时间部署(例如通过红黑部署),则您应该能够在费率聚合图上轻松设置最低警报阈值,而不必重新启动服务,导致计数器值骤降。
| 重要 |
对于大多数生产目的而言,无论是警报,自动化canary 分析等,都是基于汇率数据的自动化。 |
7.2。客户端
另一类监控系统:
预计汇率数据。鉴于对大多数生产目的的关键洞察力,我们应该根据利率而不是绝对价值来确定我们的决策,这样的系统受益于不必花数学来满足查询。
只有相对较少的数学运算或没有数据运算,可以让我们通过查询来评估数据。对于这些系统,发布预先汇总的数据是构建有意义表示的唯一方法。
Micrometer 通过累积当前发布间隔数据的步长值高效地维护速率数据。当轮询步长值时(例如发布时),如果步长值检测到当前时间间隔已过,则会将当前数据移至“前一个”状态。之前的状态是直到下一次当前数据覆盖它为止所报告的状态。下面是当前状态和先前状态以及轮询的交互情况的示意图:
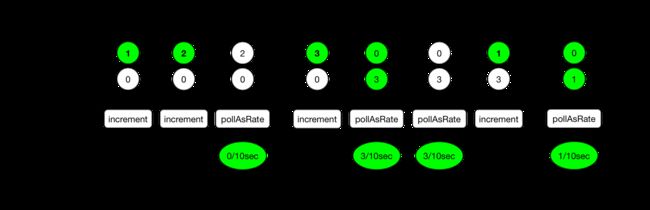
轮询函数返回的值始终是每秒*间隔的速率。如果上面说明的步长值代表计数器的值,我们可以说计数器在第一个时间间隔中看到了“每秒0.3个增量”,在第二个时间间隔的任何时间都可以报告给后端。
Micrometer 定时器作为单独的测量值追踪至少一个计数和总时间。假设我们以10秒为间隔配置发布,并且我们看到了20个请求,每个请求耗时100毫秒。然后在第一个时间间隔内:
count = 10秒*(20次请求/ 10秒)= 20次请求
totalTime = 10秒*(20 * 100毫秒/ 10秒)= 2秒
该count统计是有意义的站立单独-它是衡量吞吐量。totalTime表示间隔中所有请求的总延迟。另外:
totalTime / count = 2秒/ 20次请求= 0.1秒/请求= 100毫秒/请求
这是平均延迟的一个有用的度量。当同样的想法应用到totalAmount和count从分发概要发出,该措施被称为分布平均。平均延迟仅仅是一个分布总结的分布平均值(一个计时器)。犹如擎天一些监测系统计算从这些统计分布平均提供设施和Micrometer 将船totalTime和count作为单独统计。其他像Datadog这样的内置操作并没有,并且Micrometer会计算出分配的平均客户端并发送它。
运送发布时间间隔的速率足以推断任何时间窗口内的速率大于或等于发布时间间隔。在我们的例子中,如果一个服务继续收到20个请求,每个请求在一个给定的分钟内每隔10秒间隔需要100ms,那么我们可以说:
千分尺count每隔10秒报告一次“20次请求” 。监控系统简单地总结这六个10秒的时间间隔,并得出120个请求/分钟的结论。请注意,这是进行此总和的监控系统,而不是千分尺。
千分尺报告totalTime每隔10秒间隔“2秒” 。监控系统可以在一分钟内累计所有总时间统计数据,以在分钟间隔内产生总时间的“12秒”。然后,平均延迟与我们预期的一样:12秒/ 120次请求= 100毫秒/请求。
8.计数器
计数器报告一个指标,一个计数。该Counter接口允许您通过一个固定的量,它必须为正递增。
| 小费 |
永远不要计算你可以用一个Timer或一个总结的东西DistributionSummary!双方Timer并DistributionSummary始终发布除了其他的测量事件的计数。 |
当在柜台外建立图表和警报时,通常您应该对测量某个事件在给定时间间隔内发生的速率感兴趣。考虑一个简单的队列。计数器可以用来衡量项目被插入和删除的速度。
人们很容易在第一次怀孕可视化绝对数值,而不是速度,但绝对数量通常是一个既与一些使用快速性的功能和应用程序实例的下仪表的使用寿命。构建仪表盘和每隔一段时间计数器计数率的警报无视应用程序的使用寿命,让您在应用程序启动后很长时间内看到异常行为。
| 注意 |
请务必在跳转到使用计数器之前仔细阅读计时器部分,因为计时器记录计时事件的计数,作为进入计时的度量套件的一部分。对于那些你想要的代码段,你不需要单独添加一个计数器。 |
下面的代码模拟一个真实的计数器,它的速率在短时间窗内显示出一些扰动。
Normal rand = ...; // a random generator
MeterRegistry registry = ...
Counter counter = registry.counter("counter"); (1)
Flux.interval(Duration.ofMillis(10))
.doOnEach(d -> {
if (rand.nextDouble() + 0.1 > 0) { (2)
counter.increment(); (3)
}
})
.blockLast();
大多数计数器可以使用名称和可选的一组标签在注册表本身之外创建。
稍有积极偏向的随机游走。
这就是你如何与柜台互动。您也可以counter.increment(n)在一次操作中调用增加1以上。
在Counter界面本身还有一个流畅的计数器生成器,可以访问基本单元和描述等较少使用的选项。您可以通过拨打电话注册计数器作为其结构的最后一步register。
Counter counter = Counter
.builder("counter")
.baseUnit("beans") // optional
.description("a description of what this counter does") // optional
.tags("region", "test") // optional
.register(registry);
8.1。功能跟踪计数器
Micrometer 还提供了一种更不经常使用的计数器模式,用于跟踪单调增加的函数(一个函数保持不变或随时间增加,但从不减少)。一些监控系统,如Prometheus,将计数器的累计值推送到后端,但其他监控系统则公布计数器在推送间隔内递增的速率。通过采用这种模式,您可以让您的监测系统使用Micrometer 来选择是否对计数器进行标准化,并且您的计数器可以在不同类型的监测系统中保持可移植性。
Cache cache = ...; // suppose we have a Guava cache with stats recording on
registry.more().counter("evictions", tags, cache, c -> c.stats().evictionCount()); (1)
evictionCount() 是一个单调递增的函数,随着从其生命开始时每次缓存逐出逐渐增加。
函数跟踪计数器与监视系统的速率规范化功能(无论这是查询语言的工件还是数据推送到系统的方式)一致,在函数的累积值之上增加了一层丰富性本身。可以推论的速率在其值在增加,这样的速度是否在一个可接受的结合,增加或降低随着时间的推移等。
| 警告 |
Micrometer 不能保证你的功能的单调性。通过使用这个签名,你基于你对它的定义的了解来断言它的单调性。 |
在FunctionCounter接口本身还有一个功能计数器的流畅构建器,可以访问基本单元和描述等较少使用的选项。您可以通过拨打电话注册计数器作为其结构的最后一步register(MeterRegistry)。
MyCounterState state = ...;
FunctionCounter counter = FunctionCounter
.builder("counter", state, state -> state.count())
.baseUnit("beans") // optional
.description("a description of what this counter does") // optional
.tags("region", "test") // optional
.register(registry);
9.仪表
量表是获取当前值的句柄。量表的典型示例是集合或映射的大小或处于运行状态的线程数。
| 小费 |
仪表对于监视具有自然上限的事物很有用。我们不建议使用计量器来监视诸如请求计数之类的事情,因为它们可以在应用程序实例的生命周期内不受限制地增长。 |
| 小费 |
决不衡量的东西,你可以用一个数Counter! |
Micrometer 采取的立场是仪表应该被采样而不是设置,所以没有关于样品之间可能发生的信息。毕竟,在量表值被报告给量度后端时,在量表上设置的任何中间值都会丢失,所以在设置这些中间值时似乎没有什么价值。
如果有帮助的话,可以把它Gauge看作是一个“海森计(heisen-gauge)” - 一种只有在观察时才会改变的meter 。其他每种其他meter 类型都可以累积中间计数,以便将数据发送到metrics 后端。
该MeterRegistry界面包含建立测量仪以观察数值(values),函数(functions),collections和maps的方法。
List
List
Map
一种稍微更常见的量表是监视一些非数字对象的量表。最后一个参数建立了用于确定量表观察时量表值的函数。
(1)的一种更方便的形式,因为当你只是想监视收藏大小时。
创建量表的所有不同形式只保留对被观察对象的弱引用,以免阻止对象的垃圾收集。
9.1。手动递增/递减量表
量规可制成以跟踪任何java.lang.Number亚型即设定,如AtomicInteger和AtomicLong中发现的java.util.concurrent.atomic和类似的类型,如番石榴的AtomicDouble。
AtomicInteger n = registry.gauge("numberGauge", new AtomicInteger(0));
n.set(1);
n.set(2);
请注意,在这种形式下,与其他meter 类型不同,在创建一个Gauge 时,没有得到对Gauge 的引用,而是observed。。这是因为海森计划( heisen-gauge principal)的原因; gauge 一旦创建就是自给自足的,所以你永远不需要与它互动。这使我们能够只给你装备的对象,它允许快速创建一个可以创建要观察的对象并为其设置metrics 标准的内衬。
这种模式应该比DoubleFunction表格少一些。请记住,经常将观察Number结果设置为大量永远不会发布的中间值。只有发布时间的量表瞬时值才会发送到监控系统。
| 警告 |
试图用一个原始数字或其一个java.lang对象形式构造一个标尺总是不正确的。这些数字是不可改变的,因此量表不能改变。试图用一个不同的号码“重新注册”仪表将不起作用,因为注册管理机构对于每个唯一的名称和标签组合只维持一米。 |
9.2。衡量流利的建造者
该界面包含一个流畅的gauges生成器:
Gauge gauge = Gauge
.builder("gauge", myObj, myObj::gaugeValue)
.description("a description of what this gauge does") // optional
.tags("region", "test") // optional
.register(registry);
通常情况下,返回的Gauge实例除了在测试中没有用处,因为已经设置了gauge在注册时自动跟踪值。
9.3。为什么我的Gauge 报告NaN或消失(disappearing)?
您有责任持续强调您正在测量的状态对象Gauge。Micrometer 注意不要对可能被垃圾收集的物体产生有力的参考。一旦测量对象被取消参考并进行垃圾收集,根据注册表的实施情况,Micrometer将开始报告NaN或没有任何数据。
如果您看到您的仪表报告几分钟,然后消失或报告NaN,那么几乎可以肯定地表明所测量的潜在对象已被垃圾收集。
10.定时器
定时器可用于测量短时间延迟和此类事件的频率。Timer报告的所有实现至少将事件的总时间和次数作为单独的时间序列。
作为一个例子,考虑一个图表,显示一个典型的Web服务器的请求延迟。预计服务器可以快速响应许多请求,因此计时器将每秒更新多次。
出于充分的理由,定时器的适当基本单位因指标后端而异。Micrometer 对此无疑是毫无意义的,但由于混淆的可能性,TimeUnit在与Timers 相互作用时需要一个。Micrometer 知道每个实施的偏好,并根据实施将您的时间存储在适当的基本单元中。
public interface Timer extends Meter {
...
void record(long amount, TimeUnit unit);
void record(Duration duration);
double totalTime(TimeUnit unit);
}
界面包含定时器的流畅构建器:
Timer timer = Timer
.builder("my.timer")
.description("a description of what this timer does") // optional
.tags("region", "test") // optional
.register(registry);
10.1。记录代码块
该Timer接口暴露了一些方便过载的内嵌录制时间,例如:
timer.record(() -> dontCareAboutReturnValue());
timer.recordCallable(() -> returnValue());
Runnable r = timer.wrap(() -> dontCareAboutReturnValue()); (1)
Callable c = timer.wrap(() -> returnValue());
包装Runnable或Callable返回仪器化版本以备后用。
| 注意 |
A Timer实际上只是一个专门的分发摘要,它知道如何将持续时间缩放到每个监控系统的基本时间单位,并且具有自动确定的基本单位。在任何你想测量时间的情况下,你应该使用一个Timer而不是一个DistributionSummary。 |
10.2。存储开始状态Timer.Sample
您也可以将开始状态存储在稍后可以停止的示例实例中。该示例记录了基于注册表时钟的开始时间。启动样品后,执行要定时的代码并通过调用stop(Timer)样品完成操作。
Timer.Sample sample = Timer.start(registry);// do stuff
Response response = ...
sample.stop(registry.timer("my.timer", "response", response.status()));
请注意我们如何确定我们正在累积样本的计时器,直到停止采样为止。这使我们能够从我们计时的操作的最终状态动态地确定某些标签。
10.3。该@Timed注解
这些micrometer-core模块包含一个@Timed注释,框架可以使用该注释来为任何特定类型的方法(例如为Web请求端点提供服务的方法)或通常为所有方法添加时序支持。
| 警告 |
Micrometer的Spring Boot配置无法识别@Timed任意方法。 |
还包括一个孵化的AspectJ方面micrometer-core,您可以通过编译/加载时AspectJ编织或通过以其他方式(例如Spring AOP)解释AspectJ方面和代理目标方法的框架工具在您的应用程序中使用。以下是一个Spring AOP配置示例:
@Configuration
public class TimedConfiguration {
@Bean
public TimedAspect timedAspect(MeterRegistry registry) {
return new TimedAspect(registry);
}
}
应用TimedAspect使@Timed任何方法都可用。
10.4。功能跟踪定时器
Micrometer 还提供了一种更少使用的定时器模式,可跟踪两个单调增加的功能(一个功能保持不变或随时间增加,但从不减少):计数功能和总时间功能。像普罗米修斯(Prometheus)这样的一些监控系统会将计数器的累计值(在这种情况下适用于计数和总时间函数)推送到后端,但其他监控系统会公布计数器在推送时间间隔内递增的速率。通过采用这种模式,您可以让您的监测系统使用Micrometer 实现选择是否对计时器进行标准化,并且您的计时器可以在不同类型的监测系统中保持可移植性。
IMap cache = ...; // suppose we have a Hazelcast cache
registry.more().timer("cache.gets.latency", Tags.of("name", cache.getName()), cache,
c -> c.getLocalMapStats().getGetOperationCount(), (1)
c -> c.getLocalMapStats().getTotalGetLatency(),
TimeUnit.NANOSECONDS (2)
);
getOperationCount() 是一个单调增加的函数,每个缓存从其生命的开始就会增加。
这代表的是由时间单位表示的时间单位getTotalGetLatency()。每个注册表实现都指定了其预期的基本时间单位,报告的总时间将缩放到此值。
函数跟踪计时器与监控系统的速率规范化功能(无论这是查询语言的工件还是数据推送到系统的方式)一致,在功能的累积值之上增加了一层丰富性他们自己。您可以推断吞吐量和延迟的速率,无论该速率是否在可接受范围内,随着时间的推移而增加或减少等。
| 警告 |
Micrometer 不能保证计数和总时间函数的单调性。通过使用这个签名,你基于你对他们的定义的了解而断言他们的单调性。 |
在FunctionTimer接口本身还有一个功能定时器的流利构建器,可以访问基本单元和描述等较少使用的选项。您可以通过调用将计时器注册为其构建的最后一步register(MeterRegistry)。
IMap cache = ...
FunctionTimer.builder("cache.gets.latency", cache,
c -> c.getLocalMapStats().getGetOperationCount(),
c -> c.getLocalMapStats().getTotalGetLatency(),
TimeUnit.NANOSECONDS)
.tags("name", cache.getName())
.description("Cache gets")
.register(registry);
10.5。暂停检测
Micrometer使用LatencyUtils软件包来补偿协调的省略 - 系统和VM暂停导致的额外延迟,使您的延迟统计数据向下倾斜。像百分比和SLA计数这样的分布统计受暂停检测器实现的影响,该暂停检测器实现在这里和那里增加额外的等待时间以补偿暂停。
Micrometer 支持两种暂停检测器实现:基于时钟漂移的检测器和NOOP检测器。默认情况下,千分表配置时钟漂移检测器,以报告尽可能准确的指标,无需进一步配置。
基于时钟漂移的检测器具有可配置的睡眠间隔和暂停阈值。CPU消耗与成本成反比sleepInterval,暂停检测精度也是如此。默认情况下,这两个值都会设置为100ms,以提供长时间暂停事件的体面检测,同时消耗可忽略不计的CPU时间。
您可以使用以下自定义暂停检测器:
registry.config().pauseDetector(new ClockDriftPauseDetector(sleepInterval, pauseThreshold));
registry.config().pauseDetector(new NoPauseDetector());
将来,我们可能会提供更多的检测器实现。在某些情况下,可能会从GC日志记录中推断出一些暂停,例如,不需要恒定的CPU负载,但是最小。未来的JDK也可能提供对暂停事件的直接访问。
10.6。内存足迹估计
定时器是消耗内存最多的meter,它们的总占用空间会根据您选择的选项而发生显着变化。以下是基于使用各种功能的内存消耗表。这些数字假设没有标签和环形缓冲区长度为3.添加标签当然会增加总量,增加缓冲区长度也是如此。根据注册表的实施情况,总存储量也可能有所不同。
R =环形缓冲区长度。我们假设在所有示例中缺省为3。R被设置Timer.Builder#distributionStatisticBufferLength。
B =总直方图桶。可以是SLA边界或百分位直方图桶。默认情况下,定时器被限制为1ms的最小期望值和30秒的最大期望值,在适用的情况下,产生66个百分桶直方图桶。
I =暂停补偿的区间估计器。1.7 kb
M =最大时间衰减 104字节
Fb =固定的边界直方图。30b * B * R
Pp =百分比精度。缺省值为1.通常在[0,3]范围内。Pp设置为Timer.Builder#percentilePrecision。
Hdr(Pp)=高动态范围直方图。
当Pp = 0时:1.9kb * R + 0.8kb
当Pp = 1时:3.8kb * R + 1.1kb
当Pp = 2时:18.2kb * R + 4.7kb
当Pp = 3时:66kb * R + 33kb
| 暂停检测 |
客户端百分点 |
直方图和/或SLA |
式 |
例 |
| 是 |
没有 |
没有 |
I + M |
〜1.8kb的 |
| 是 |
没有 |
是 |
I + M + Fb |
对于默认百分直方图,约7.7kb |
| 是 |
是 |
是 |
I + M + Hdr(Pp) |
除此之外,还有一个0.95的百分位,默认值为〜14.3kb |
| 没有 |
没有 |
没有 |
中号 |
〜0.1kb |
| 没有 |
没有 |
是 |
M + Fb |
对于默认的百分直方图,大约6kb |
| 没有 |
是 |
是 |
M + Hdr(Pp) |
除此之外,还有一个0.95的百分位,默认值为〜12.6kb |
| 注意 |
这些估计是基于在Micrometer 1.0.3中所做的改进,并假定至少该版本。 |
| 注意 |
对于Prometheus来说,R 总是等于1,而不管你如何配置它Timer.Builder。这是Prometheus的特例,因为它预计累积直方图数据永远不会翻转。 |
11.分发摘要
分发摘要用于跟踪事件的分布。它在结构上类似于计时器,但记录的值不代表时间单位。例如,可以使用分发摘要来度量到达服务器的请求的有效负载大小。
要创建分发摘要:
DistributionSummary summary = registry.summary("response.size");
该界面包含流畅的构建器,用于发布摘要:
DistributionSummary summary = DistributionSummary
.builder("response.size")
.description("a description of what this summary does") // optional
.baseUnit("bytes") // optional (1)
.tags("region", "test") // optional
.scale(100) // optional (2)
.register(registry);
添加基座以实现最大的便携性 - 基座是某些监控系统的命名约定的一部分。如果你忘记了它,违反命名规则将不会产生不利影响。
或者,您可以提供一个缩放因子,每个记录的样本在记录时将被倍增。
11.1。缩放和直方图
Micrometer的预选百分直方图桶都是从1到最大长度的整数。目前minimumExpectedValue并maximumExpectedValue用来控制斗集的基数。如果我们尝试检测您的最小/最大值产生一个小范围,并将预选存储区域缩放到摘要范围,那么我们没有另一个杠杆来控制存储桶基数。
相反,如果摘要的域名受到更多限制,请按固定因子缩放摘要的范围。我们迄今为止所听到的用例是其域名为[0,1]的比率总结。然后:
DistributionSummary.builder("my.ratio").scale(100).register(registry)
通过这种方式,比例在[0,100]范围内,我们可以将其设置maximumExpectedValue为100.如果您关心特定比率,请将其与自定义SLA边界配对:
DistributionSummary.builder("my.ratio")
.scale(100)
.sla(70, 80, 90)
.register(registry)
11.2。内存足迹估计
根据您选择的选项,分发摘要的总内存占用量可能会有很大差异。以下是基于使用各种功能的内存消耗表。这些数字假设没有标签和环形缓冲区长度为3.添加标签当然会增加总量,增加缓冲区长度也是如此。根据注册表的实施情况,总存储量也可能有所不同。
R =环形缓冲区长度。我们假设在所有示例中缺省为3。R被设置DistributionSummary.Builder#distributionStatisticBufferLength。
B =总直方图桶。可以是SLA边界或百分位直方图桶。默认情况下,汇总没有最小和最大期望值,因此将所有276个预定直方图存储区发货。您应该始终使用a minimumExpectedValue和maximumExpectedValue当您打算发送百分比直方图时限制发行摘要。
M =最大时间衰减 104字节
Fb =固定的边界直方图。30b * B * R
Pp =百分比精度。缺省值为1.通常在[0,3]范围内。Pp设置为DistributionSummary.Builder#percentilePrecision。
Hdr(Pp)=高动态范围直方图。
当Pp = 0时:1.9kb * R + 0.8kb
当Pp = 1时:3.8kb * R + 1.1kb
当Pp = 2时:18.2kb * R + 4.7kb
当Pp = 3时:66kb * R + 33kb
| 客户端百分点 |
直方图和/或SLA |
式 |
例 |
| 没有 |
没有 |
中号 |
〜0.1kb |
| 没有 |
是 |
M + Fb |
对于夹持到66个桶的百分位直方图,〜6kb |
| 是 |
是 |
M + Hdr(Pp) |
除此之外,还有一个0.95的百分位,默认值为〜12.6kb |
| 注意 |
这些估计是基于在Micrometer 1.0.3中所做的改进,并假定至少该版本。 |
| 注意 |
对于Prometheus来说,R 总是等于1,而不管你如何配置它DistributionSummary.Builder。这是Prometheus的特例,因为它预计累积直方图数据永远不会翻转。 |
12.长时间任务计时器
长时间任务计时器是一种特殊类型的计时器,可让您在测量事件仍在运行的同时测量时间。计时器不会记录任务完成前的持续时间。
现在考虑一个后台进程来刷新数据存储中的元数据。例如,Edda可以缓存AWS资源,例如实例,卷,自动扩展组等。通常所有数据都可以在几分钟内刷新。如果AWS服务有问题,则可能需要更长的时间。长时间定时器可用于跟踪刷新元数据的总时间。
例如,在Spring应用程序中,通常需要使用这种长时间运行的进程@Scheduled。测微仪提供了一个特殊的@Timed注释,用于通过长时间的任务计时器来测量这些过程。
@Timed(value = "aws.scrape", longTask = true)@Scheduled(fixedDelay = 360000)void scrapeResources() {
// find instances, volumes, auto-scaling groups, etc...
}
这取决于应用程序框架以使事情发生@Timed。如果您选择的框架不支持它,您仍然可以使用长任务计时器:
LongTaskTimer scrapeTimer = registry.more().longTaskTimer("scrape");void scrapeResources() {
scrapeTimer.record(() => {
// find instances, volumes, auto-scaling groups, etc...
});
}
如果我们想要在此过程超过阈值时发出警报,并且有一个长时间的任务计时器,我们将在超过阈值后的第一个报告间隔收到该警报。使用普通定时器,我们不会收到警报,直到过程完成后的第一个报告间隔超过一个小时!
该界面包含用于长任务计时器的流畅构建器:
LongTaskTimer longTaskTimer = LongTaskTimer
.builder("long.task.timer")
.description("a description of what this timer does") // optional
.tags("region", "test") // optional
.register(registry);
13.直方图和百分位数
定时器和发布摘要支持收集数据以观察其百分比分布。有两种查看百分位数的主要方法:
百分位直方图(Percentile histograms) - Micrometer 将值累加到基础直方图并将预定的一组水桶运送到监控系统。监控系统的查询语言负责计算此直方图的百分数。目前,只有普罗米修斯(Prometheus )和Atlas支持基于直方图的百分位近似值,通过histogram_quantile和:percentile分别。如果以Prometheus或Atlas为目标,则更喜欢这种方法,因为您可以汇总跨维度的直方图(通过简单汇总一组维度中的存储区的值)并从直方图中导出可汇总的百分位数。
客户端百分点 (Client-side percentiles)- Micrometer 计算每个仪表ID(名称和标签集)的百分比近似值,并将百分位数值发送给监控系统。这不像百分比直方图那么灵活,因为不可能汇总标签间的百分比近似值。尽管如此,它为监视系统的百分位分布提供了一些洞察,这些监视系统不支持基于直方图的服务器端百分比计算。
以下是用直方图构建计时器的示例:
Timer.builder("my.timer")
.publishPercentiles(0.5, 0.95) // median and 95th percentile
.publishPercentileHistogram()
.sla(Duration.ofMillis(100))
.minimumExpectedValue(Duration.ofMillis(1))
.maximumExpectedValue(Duration.ofSeconds(10))
publishPercentiles - 这用于发布您的应用中计算的百分比值。这些值在整个维度上不可聚合。
publishPercentileHistogram- 这用于发布适用于计算Prometheus中使用histogram_quantile和Atlas使用的聚合(跨维)百分比近似值的直方图:percentile。生成的直方图中的存储桶由Micrometer根据Netflix经验确定的发生器进行预设,以产生大多数真实世界定时器和发布摘要的合理误差界限。发生器默认产生276个桶,但是千分尺仅运送在minimumExpectedValue和由maximumExpectedValue(包括)设置的范围内的那些桶。默认情况下,测微器将定时器固定在1毫秒到1分钟的范围内,每个定时器尺寸产生73个直方图桶。publishPercentileHistogram对不支持可聚合百分比近似值的系统没有影响 - 这些系统不提供直方图。
sla - 用您的SLA定义的桶发布累积直方图。与publishPercentileHistogram支持可聚合百分位数的监视系统一起使用时,此设置会在发布的直方图中添加更多的存储桶。在不支持可聚合百分位数的系统上使用时,此设置会导致仅使用这些存储桶发布直方图。
minimumExpectedValue/ maximumExpectedValue- 控制发货桶的数量,publishPercentileHistogram并控制底层HdrHistogram结构的准确性和内存占用。
由于向监控系统传送百分比会生成额外的时间序列,因此通常最好不要将它们配置为作为应用程序依赖关系包含的核心库中。相反,应用程序可以通过仪表过滤器为某些定时器/发布摘要集打开此行为。
例如,假设我们在一个公共库中有一些定时器。我们已经为这些计时器名称加上了前缀myservice:
registry.timer("myservice.http.requests").record(..);
registry.timer("myservice.db.requests").record(..);
我们可以通过仪表过滤器为两个定时器启用客户端百分比:
registry.config().meterFilter(
new MeterFilter() {
@Override
public HistogramConfig configure(Meter.Id id, HistogramConfig config) {
if(id.getName().startsWith("myservice")) {
return HistogramConfig.builder()
.percentiles(0.95)
.build()
.merge(config);
}
return config;
}
});