Java 1.8+Hadoop 2.7.3+Spark 2.1.1+Scala 2.11.8整合分布式部署
在写本文章前,假设三个Linux系统已经装好,分别为:
三个主机:
1、键入命令:
sudo vi /etc/hostnamemaster、slave1、slave2
IP地址分别为:
2、修改文件hosts
sudo vi /etc/hosts192.168.56.101 master
192.168.56.102 slave1
192.168.56.103 slave2
3、安装文件的路径
/usr/install/xxx
3.1、创建目录
mkdir -p /usr/install4、三个主机能互相ping通,以及和windows系统ping通
主要用NAT和Host-Only
虚拟机的网络设置如下
首先设值全局网络,在仅主机网络下添加一个Host-Only
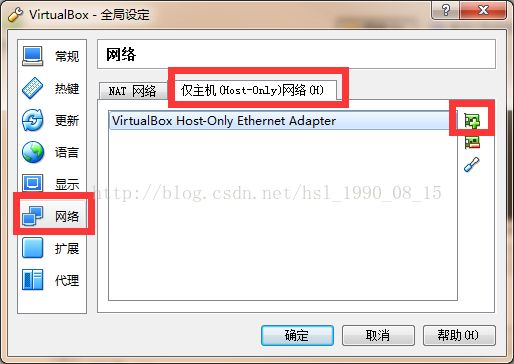
接下来的配置如下图
这个保持默认就可以

DHCP启用后,自己设置

在网络连接中,Host-Only中也保持默认
设置具体的每一个虚拟机的网络
网卡1设置为NAT模式
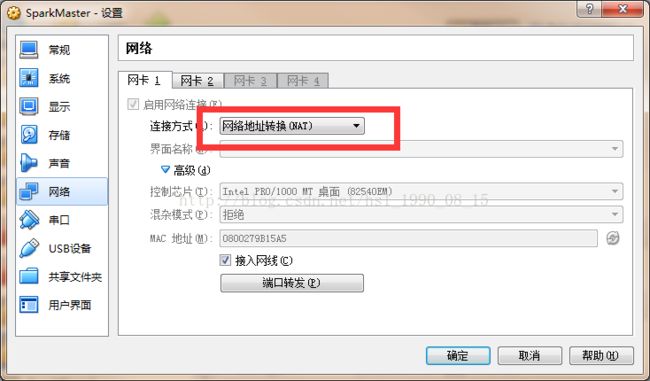
网卡2设置为Host-Only模式

这样宿主机就可以ping通了
5、安装jdk
虚拟机安装的是最小版本的,所以没有安装jdk
5.1、下载jdk1.8
jdk1.8
5.2、下载完后,上传到指定目录,敲入命令:
tar -zxvf jdk-8u131-linux-x64.tar.gz -C /usr/install/jdk
sudo vi /etc/profile由于我使用的账号不是管理员账号,所以在执行一些敏感的命令时需要加上dudo
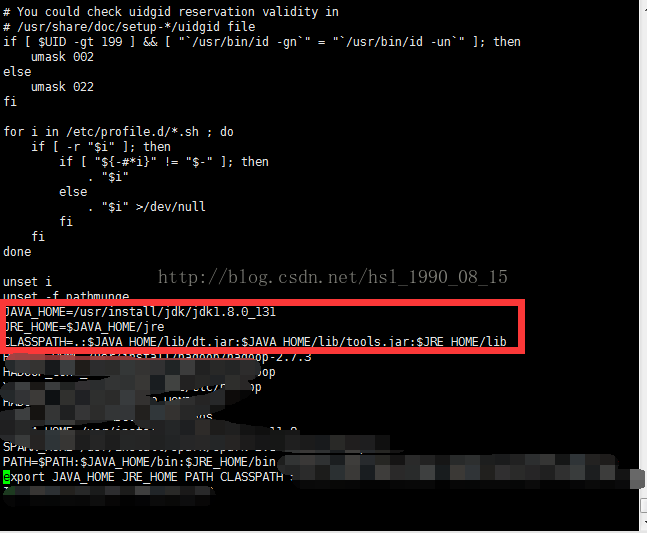
加上如上配置,保存并退出
刷新profile文件
sudo source /etc/profile刷新文件,使配置生效
5.4、测试jdk是否安装成功
java -version
说明已经安装成功了。
5.5、把配置好的jdk分别复制到另外两台机器上
sudo scp /etc/profile slave1:/etc
sudo scp /etc/profile slave2:/etc
sudo scp /usr/install/jdk/jdk1.8.0_131 slave1:/usr/install/jdk
sudo scp /usr/install/jdk/jdk1.8.0_131 slave2:/usr/install/jdk6、接下来安装hadoop
6.1、下载hadoop2.7.3
hadoop2.7.3
由于我安装的spark是2.1.1的版本,他=跟他匹配的hadoop版本是3.7.x
6.2、解压
tar hadoop-2.7.3.tar.gz -C /usr/install/hadoop6.3、解压完成后,进行环境配置
配置hadoop-env.sh
键入命令
sudo vi /usr/install/hadoop/hadoop-2.7.3/etc/hadoop/hadoop-env.sh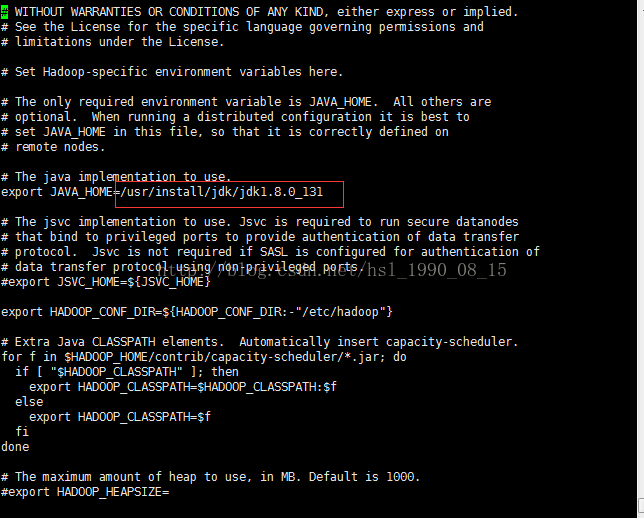
加入jdk的路径
配置core-site.xml
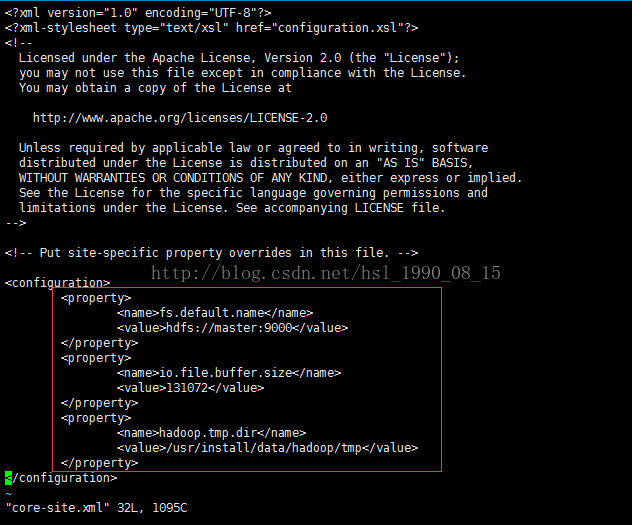
在configuration中加入内容如上
配置hdfs-site.xml

在configuration中加入内容如上
配置mapred-site.xml

在configuration中加入内容如上
配置yarn-site.xml

配置jdk路径
接下来配置yarn-site.xml

在configuration中加入内容如上
配置slaves
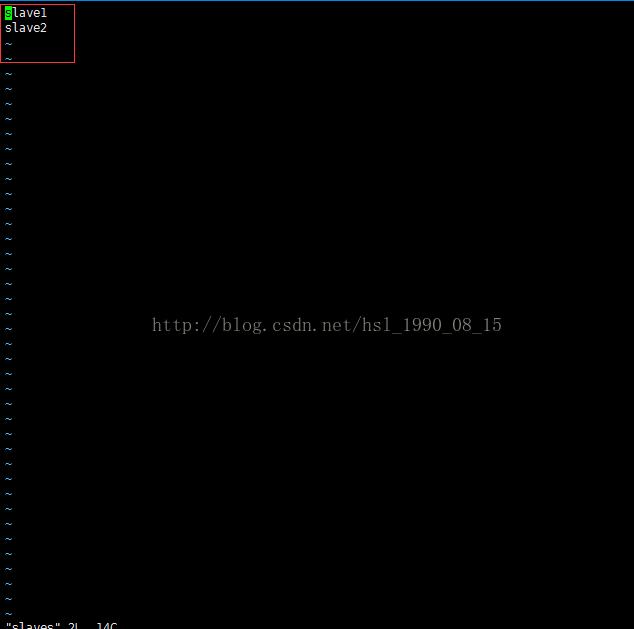
把localhost改为另外两台机器的机器名
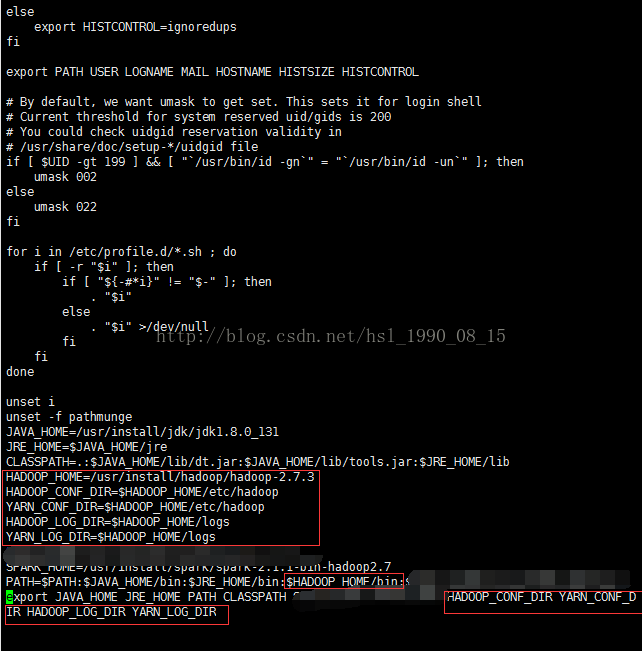
sudo source /etc/profile刷新文件,使配置生效
6.4、检查hadoop是否配置成功
hadoop version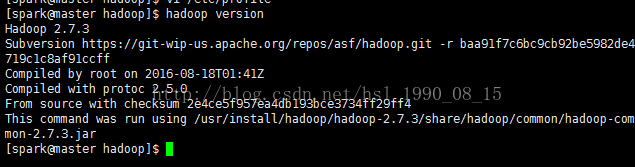
说明环境已经配置成功了
6.5、把配置好的hadoop分别复制到另外两台机器上
sudo scp /etc/profile slave1:/etc
sudo scp /etc/profile slave2:/etc
sudo scp /usr/install/hadoop/hadoop-2.7.3 slave1:/usr/install/hadoop
sudo scp /usr/install/hadoop/hadoop-2.7.3 slave2:/usr/install/hadoop
6.5、格式化环境
hadoop namenode -format这个过程可能会出现问题:
遇到的问题
1)、不能创建目录,设置install目录的权限
sudo chmod a+w /usr/install这个命令的意思是所有的用户都可以读写
2)、配置文件中配置的路径或者值有问题,仔细检查,并修改
3)、没有发现另外两台机器,查看hosts文件是否配置
4)、链接另外两台机器失败,首先我们配置无秘钥登录,接着关闭防火墙,无秘钥登录,我的另外一个博客
5)、报SafeModeException,需要退出安全模式
hadoop dfsadmin -safemode leave7、现在开始安装scala
在运行spark的shell脚本中,使用的就是scala语言,所以先安装scala才能保证运行spark,spark官网推荐的2.1.1版本的scala是2.11.8版本
下载scala
7.1、解压
tar -zxvf scala-2.11.8.tgz -C /usr/install/scala7.2、配置环境变量
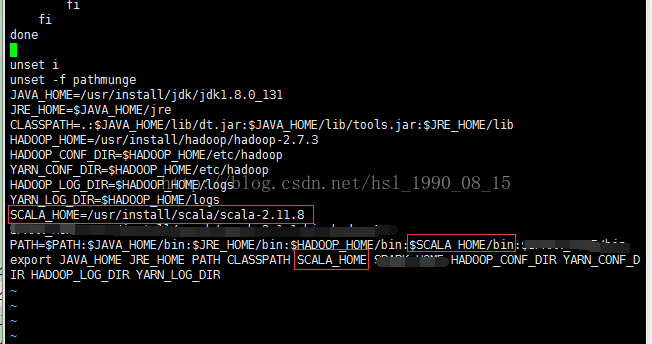
加入如上配置
sudo source /etc/profile刷新文件,使配置生效
7.3、检查是否配置成功

8、进入主题,安装spark
安装的spark的版本是2.1.1
下载spark
8.1、解压
tar -zxvf spark-2.1.1-bin-hadoop2.7.tar -C /usr/install/spark8.2、复制spark-env.sh.template到spark-env.sh,slaves.template到slaves
cd /usr/install/spark/spark-2.1.1-bin-hadoop2.7/conf
sudo cp spark-env.sh.template spark-env.shsudo cp slaves.template slaves8.3、配置spark-env.sh
加入如下配置

在slaves中加入如下内容

8.4、接着配置profile文件

sudo source /etc/profile刷新文件,使配置生效
8.5、把配置好的scala和spark分别复制到另外两台机器上
sudo scp /etc/profile slave1:/etc
sudo scp /etc/profile slave2:/etc
sudo scp /usr/install/spark/spark-2.1.1-bin-hadoop2.7 slave1:/usr/install/spark
sudo scp /usr/install/spark/spark-2.1.1-bin-hadoop2.7 slave2:/usr/install/spark8.6、测试spark是否安装成功
spark-shell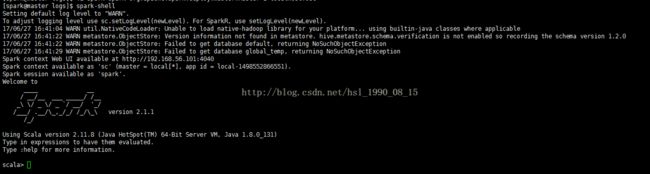
说明已经安装成功
8.7、遇到的问题
1)、无法连接另外的机器,设置无秘钥登录,关闭防火墙
2)、无法创建指定目录,设置权限
3)、无法删除某一个文件,可能hadoop进入了安全模式,不让访问文件这时可以执行退出安全模式
9、测试hadoop集群是否可以正常工作
9.1、在hadoop集群上上传一个文件
在home目录创建workcount.txt
sudo vi ~/workcount.txt输入内容
Hello hadoop
hello spark
hello bigdata
保存并退出
.2、上传文件到hdfs集群中
先在集群中创建一个目录/count/input
hadoop fs -mkdir -p /count/input接着进行上传
hadoop fs -put ~/workcount.txt /count/input运行wordcount例子
hadoop jar /usr/install/hadoop/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /count/input /count/output
9.3、查看hadoop记过统计得到的数据
hadoop fs -cat /count/output1/part-r-00000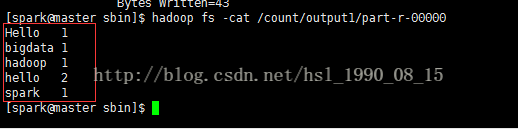
hadoop已经ok了
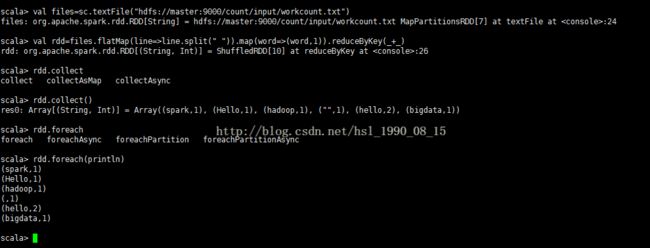
10、测试spark集群
10.1、进入spark命令行
spark-shellval files=sc.textFile("hdfs://master:9000/count/input/workcount.txt")
val rdd=files.flatMap(line=>line.split(" ")).map(word=>(word,1)).reduceByKey(_+_)
rdd.collect()
rdd.foreach(println)