自然语言处理(五)——单词纠错
一、概念
编辑距离(Edit Distance):是指两个字串之间,由一个转成另一个所需的最少编辑操作次数。
精准的定义就不多说了,直接上例子来理解这个编辑距离。编辑主要有三个操作:插入、删除、修改。例如:goood变为good,只需要删除一个o,因此编辑距离是1。gd变为god。只需要插入一个o,因此编辑距离是1。gwd变为god,只要修改w为o,因此编辑距离是1。
cutoff编辑距离(cut-off Edit Distance): 官方的概念我就不粘贴过来了,直接举个例子来说明什么是cutoff编辑距离。
例子如下:Y字符串是正确的字符串的一部分,X字符串是错误的字符串。两个字符串是从o开始不一样的。
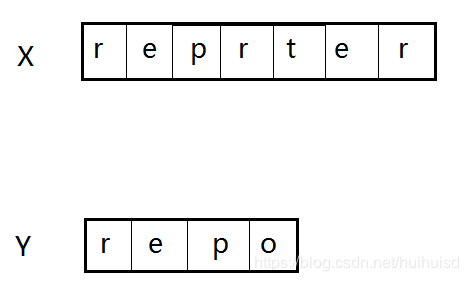
计算cutoff编辑距离的过程:
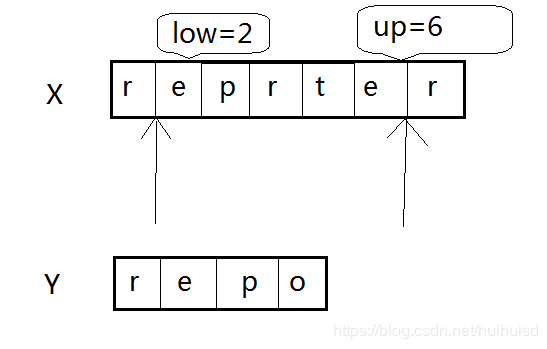
(1) 令 n = length(Y) (n为Y字符串的长度)显然这里的n=4。令m = length(X) ,显然这里的m=7。
(2) 令low = max(1,n-t) t是阈值,这里的不妨令t=2。令up = min(m,n+t)。带入数值可以得出 low = 2,up = 6。到此步变为下图。意思就是从第2个字符开始到第6个字符截止进行计算。
1) 计算字符串re和repo的编辑距离,ed(re,repo) = 2。
2) 计算字符串rep和repo的编辑距离,ed(rep,repo) = 1。
3) 计算字符串repr和repo的编辑距离,ed(repr,repo) = 1。
4) 计算字符串reprt和repo的编辑距离,ed(reprt,repo) = 2。
5) 计算字符串reprte和repo的编辑距离,ed(rep,repo) = 3。
(3) cutoff编辑距离就是在上述五步中最小的距离,在这个例子中: cutoff ed(reprter,repo) = 1
上述的内容就是编辑距离和cutoff编辑距离,可以明显的看出 cutoff编辑距离 <= 编辑距离 恒成立。
二、单词纠错
这里是用自动机来实现单词纠错,纠错也仅仅是想法,还没有做成一个成品。
首先,单词纠错第一个要解决的问题是判断输入的单词是否存在。
其次,要创建一个自动机,自动机就是一个图,这个图必然极其庞大,这里也不具体实现。
最后,如果这个单词不存在,根据创建的自动机来判断是否能够将这个错误的单词提示给用户可能正确的单词。举个例子:假如用户输入了hellp,就可以提示用户“你想输入的可能是hello”。这个自动机判断的过程我们具体展开阐释。
如下例子,有下面这么一个自动机,阈值为1(t=1,同时cutoff距离不超过1),输入了“ababa”(这个ababa肯定是错的,字符个数最起码是3的倍数才是正确的,所以要通过搜索这个自动机来纠错)。
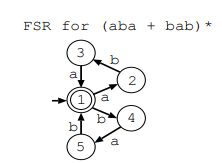
过程如下:
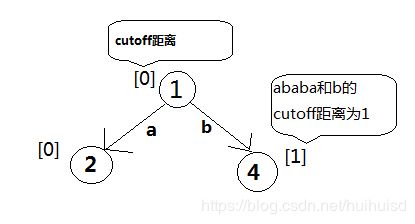
照这个规则继续往下搜索,直到cutoff距离大于阈值1。这里我就把原论文的图直接引用过来了。
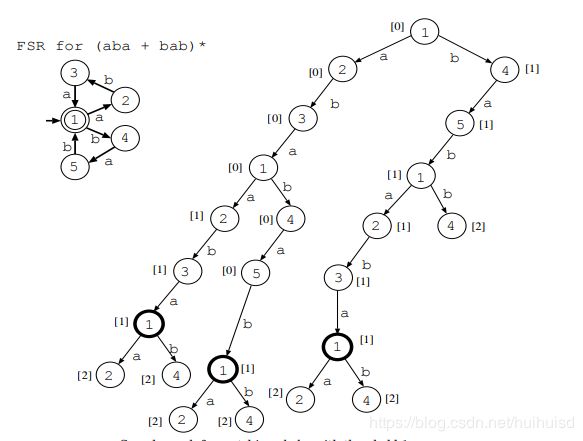
1是终止状态,且再往后遍历cutoff距离就都大于1,因此到此截止。但是还不能直接把这三个都当作纠错词。上面已经提到了cutoff距离永远小于等于编辑距离。因此必须再计算abaaba, ababab,bababa这三个字符串和ababa的编辑距离,如果编辑距离还是小于等于1,那么就可以将这个词提醒给用户,你输入错误,你想输入的可能是“abaaba, ababab,bababa”。显而易见,这三个字符串和ababa的编辑距离都是1。因此这三个字符串就可以提供给用户正确参考。
截止到此,单词纠错的总体思想也就完成了,这个自动机只是一个简单的样例,但是麻雀虽小五脏俱全,该有的方法都有。具体的实现还在能力范围之外。最后,本文可能会有致命性错误或者颠覆性错误,各位看到发现的话请不吝赐教。
参考的论文:Error-tolerant Finite State Recognition with Applications to Morphological Analysis and Spelling Correction,Kemal Oflazer Bilkent University,(1996)