BCPNet:用于实时语义分割的双向上下文传播网络

论文地址:https://arxiv.org/pdf/2005.11034.pdf
代码地址:暂无
空间细节和上下文相关性是语义分割的两类关键信息。一般来说,空间细节最可能存在于浅层,而上下文关联最可能存在于深层。为了同时利用这两种方法,目前的方法大多选择将空间细节前向传输到深层。我们发现空间细节传输的计算量很大,并且大大降低了模型的执行速度。针对这一问题,我们提出了一种新的双向上下文传播网络(BCPNet),该网络能够实时进行语义分割。不同于以往的方法,我们的BCPNet有效地将上下文信息回传到浅层,这在计算上更加保守。大量的实验证明,我们的BCPNet在精度和速度之间取得了很好的平衡。在准确性方面,我们的BCPNet在城市景观测试集上达到了68.4%的MIU,在CamVid测试集上达到了67.8%。在速度上,我们的BCPnet可以达到每幅图像585.9 FPS和1.7ms的运行时间。
关键字:语义分割、逐层上下文、多层上下文
01 Introduction
语义分割是计算机视觉中最具挑战性的任务之一,其目的是根据每个像素的类别将图像分割成几个互不重叠的区域。由于其在视觉处理中的独特作用,许多现实应用都依赖于该技术,如无人驾驶汽车[17,18]、医学图像分析[6,7]和图像编辑[19]。其中一些应用不仅要求较高的切分精度,而且要求较快的执行速度,这使得语义切分的任务更具挑战性。然而,近年来,分割精度和分割速度之间的平衡仍然不尽如人意。
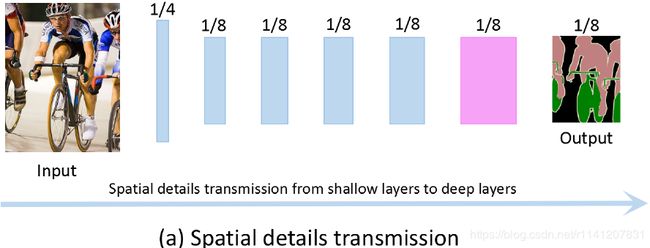
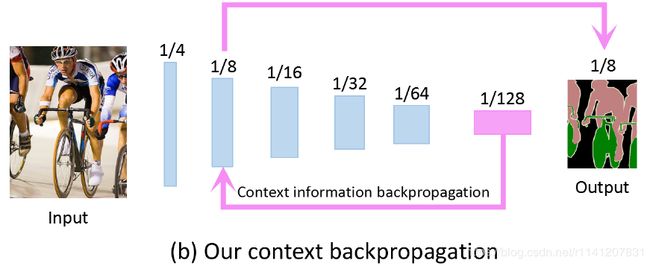
图1:先前空间细节传输和我们的上下文反向传播机制的插图。
语义分割算法有两个关键点:1)空间细节保持;2)上下文信息聚合。一般来说,空间细节更可能存在于浅层,而上下文信息更可能存在于深层。目前的大多数方法通过1)将高分辨率特征图保存在网络管道中以维护空间细节和;2)使用扩展卷积[22]来聚合上下文信息(例如[3,8,11,23,25])来实现这两个关键点。这些方法可以看作是信息传输的任务:空间细节从浅层传输到深层,如图1(A)所示。大量的研究已经证明,适当配合低层空间细节和高层上下文信息可以使语义分割更加准确。然而,在深度神经网络中保持相对高分辨率的特征映射往往会带来较高的计算代价。此外,这将大大降低模型的执行速度。为了量化特征分辨率在网络管道中的影响,我们在著名的ResNet[9]框架上进行了一个简单的实验。为了进行公平比较,删除了ResNet的最后一个完全连接层。如图2所示,当特征分辨率增大时,模型的错误大大增加,相应地,模型的执行速度也会大大降低。
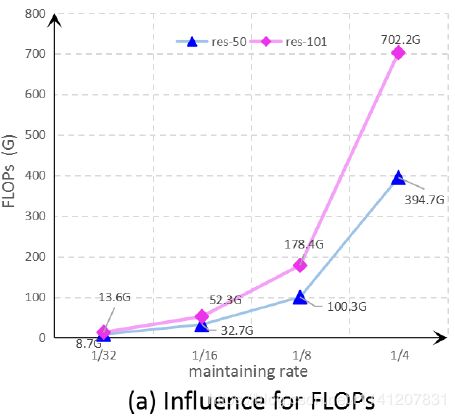
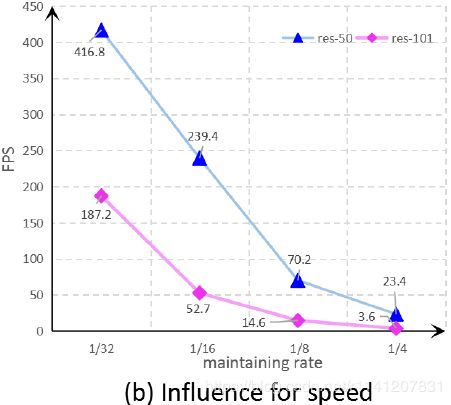
图2:网络管道中维护的功能分辨率对FLUPS和速度的影响。“维持率”表示最终维护的特征地图与输入图像之间的分辨率。“RES-50”代表ResNet-50网络。“RES-101”代表ResNet-101网络。
考虑到维持空间细节所达到的精度和速度之间的较差平衡,我们提出了一种新的双向上下文传播网络(BCPNet)。与以前传输空间细节的方法不同,我们的BCPNet被设计为在网络管道内有效地反向传播上下文信息,如图1(B)所示。通过将从深层聚集的上下文信息反向传播到浅层,浅层特征变得足够感知上下文,如图4所示。因此,可以直接使用浅层特征进行最终预测。传输信息类型和传输方向的改变消除了在网络管道中保持高分辨率特征图的需要。这使得我们可以设计一个具有较少的FLOP和较快的执行速度,但具有相对较高的分割精度的网络。基于所提出的上下文反向传播机制,我们提出了一种新的双向上下文传播网络(BCPNet),如图3所示。我们的BCPNet的关键组件是双向上下文传播(BCP)模块,如图3(B)所示,它使用自上而下和自下而上的路径将上下文信息反向传播到浅层。我们的BCPNet是轻量级的,总共只包含大约0.61M个参数。大量实验证明,我们的BCPNet在切分精度和执行速度之间取得了很好的平衡。例如,在执行速度上,我们的BCPNet可以在360×640FPS的输入图像上达到585.9 FPS。即使对于1024×2048个输入图像,我们的BCPNet仍然可以达到55FPS。在分割准确率方面,我们的BCPNet在城市景观[5]测试集上达到了68.4%的MIU,在CamVid[2]测试集中达到了67.8%。
本文的主要贡献:
首先,与以往在网络管道内转发空间细节的方法相比,我们引入了一种新的上下文反向传播机制。这有利于提高精度和速度之间的平衡。
其次,在提出的上下文反向传播机制的基础上,提出了一种新的BCPNet,它采用自上而下和自下而上的路径,有效地实现了上下文的反向传播。
第三,我们的BCPNet在准确性和速度方面达到了最先进的平衡。
本文的其余部分组织如下。首先介绍了第二节中的相关工作,然后在第三节中详细介绍了我们的方法,然后在第四节中进行了实验。最后,在第五节中,我们对本文进行了总结。
02 Related Work
在本节中,我们将回顾与我们相关的方法。首先,我们回顾了基于网络管道传输空间细节的方法。然后,我们回顾了以提高执行速度为重点的方法。
2.1空间细节传输
DilatedNet[22]是基于空间细节传输的开创性工作。针对在网络管道中转发空间细节(图1(A)),[22]引入了膨胀卷积。扩展的卷积通过在卷积核上插入孔来扩大卷积运算的接受范围。因此,可以在网络中删除一些下采样操作,如合并。这避免了特征分辨率的降低和空间细节的丢失。继[22]之后,提出了大量的变体,如[3,8,23,25]。特别地,这些方法中的大多数都关注于进一步改善最后卷积层的上下文表示。例如,[25]引入了金字塔池模块(PPM),在该模块中,多个并行平均池分支被应用于最后一卷积层,目的是聚集更多上下文相关性。[3]通过进一步引入扩张卷积[22],将PPM扩展到Atrus空间金字塔池(ASPP)模块。通过使用字典学习来学习全局上下文嵌入,[23]引入了EncNet。最近,他等人。[8]提出了自适应金字塔上下文网络(APCNet),其中自适应上下文模块(ACM)用于聚合金字塔上下文信息。
讨论:然而,为了同时使用空间细节和上下文相关性,上述方法都选择将空间细节从深层传输到浅层,如图1(A)所示。网络管道内的空间细节传输的计算代价很高,并且大大降低了模型的执行速度(如图2所示)。虽然这些方法提高了分割精度,但精度和速度之间的平衡还远远不能令人满意。以DeepLab[3]为例。基于一幅512×1024的输入图像,共包括457.8个G触发器。它的速度只能达到0.25FPS。这意味着,对于每个映像,它将花费4000毫秒的运行时间(表1和表2)。
2.2提高执行速度
一些现实世界的应用,如自动驾驶汽车,不仅需要准确的分割,而且需要快速的执行速度。因此,在精度和速度之间取得更好的平衡至关重要。例如,[1]通过将网络扩展到较小的网络来建议SegNet。SegNet包含29.5M参数,在640×360输入图像上可以达到14.7FPS。此外,在城市景观测试集上取得了56.1%的效果。[14]通过采用严密的框架建议ENET。以太网包含0.4M参数,基于360×640的图像可以达到135.4帧/秒。此外,ENET在城市景观测试集上达到了58.3%的MIU。[24]提出了采用多尺度输入、级联框架的策略构建轻量级网络的ICNet。ICNet包含26.5M参数,基于1024×2048输入图像可以达到30.3FPS。此外,ICNet在CamVid[2]测试集上的MIU达到了67.1%。[21]通过独立构建空间路径和上下文路径,提出了BiSeNet。上下文路径用于提取高层上下文信息,空间路径用于维护低级空间细节。在768×1536幅城市景观测试集上,BiSeNet在72.3FPS下取得了68.4%的MIU值。最近,[10]提出了基于特征重用策略的DFANet。在1024×1024幅城市景观测试集的输入图像上,DFANet在100FPS时达到了71.3%的MIU值。通过采用非对称卷积结构和密集连接,[12]提出了只包含0.68M参数的EDANet。EDANet可以在512×1024个输入图像的基础上实现81.3FPS。此外,在城市景观测试集上仍然达到了68.4%的Miou。
讨论:现有的提高执行速度的方法通常忽略了上下文信息的重要作用。他们中的大多数都致力于将网络扩展到一个较小的网络,如[1,10,14,24]。虽然BiSeNet[21]构造了一个空间路径和一个上下文路径来分别学习空间细节和上下文相关性,但这在计算上仍然很昂贵。例如,BISeNet-1包含4.8 M参数,BISeNet-2包含49 M参数。对于768×1536个输入图像,BiSeNet-1涉及14.8G Flops,BiSeNet-2涉及55.3G Flops。与这些方法不同的是,本文的目标是利用所提出的上下文传播机制构建一个实时的语义分割框架。
3 Proposed Method
在本节中,我们将介绍我们的方法。首先,我们对我们的BCPNet进行概述。然后,详细介绍了其中的关键组件BCP模块。
3.1 Architecture of BCPNet
如图3所示,我们的BCPNet是编解码器框架的变体。在编码器方面,我们选择了MobileNet[16]作为我们的骨干网。在骨干网中,我们不使用任何膨胀卷积来保持特征图的分辨率。取而代之的是,特征地图被快速下采样到输入图像的1/32分辨率。这使得网络的计算量很小。考虑到轻量级网络不能学习复杂的上下文表示,我们选择了一种简单的上下文聚合方法,如[25]。但不同的是,首先,我们以串行的方式而不是并行的方式来制定上下文聚合的过程。其次,我们选择最大池化来聚合上下文信息,而不是平均池化。对于我们的网络,我们发现使用最大池化来聚合上下文会产生更好的性能(表5)。如图3所示,骨干网的输出被连续馈送到两个最大合用操作中,其中内核大小设置为3×3,跨度设置为2。因此,上下文映射进一步压缩为1/128,更具全局性。然后,使用提出的BCP模块(图3(B))将聚集的上下文信息反向传播到浅层,从而有效地使浅层特征具有足够的上下文感知能力。在我们的实验中,我们将第三层设置为传输中的最后一层浅层。最后,我们直接使用第三层的特征来输出最终的预测。
我们的BCPNet只包含0.61M个参数。这意味着它甚至适用于移动设备,如手机。基于轻量级结构,我们的BCPNet在360×640FPS的输入图像上可以达到585.9帧/秒。这意味着,对于一个图像,它只需要1.7ms的运行时间。虽然我们的BCPNet是轻量级的,但它在准确率方面仍然取得了很好的性能。例如,在城市景观测试集上达到了68.4%的MIU,在CamVid测试上达到了67.8%。
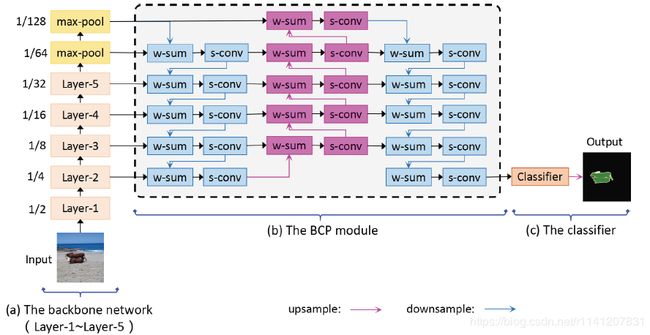
图3:我们的BCPNet概述。“w-sum”表示加权和。“S-conv”表示可分离卷积。
3.2 Details of BCP module
我们的BCPNet的关键组件是BCP模块,如图3(B)所示。我们的BCP模块由两条自上而下的路径和一条自下而上的路径组成。自上而下的路径被设计成将上下文信息反向传播到浅层。自下而上的路径旨在夸耀空间细节和上下文信息之间的融合过程。特别地,如图3(B)所示,我们以交替的方式制定自上而下路径和自下而上路径。对于自上而下和自下而上路径的每一层,它包含两个分量,即加权和和可分离卷积[4]。正如公式1所描述的那样,加权和通过使用可学习的比例因子来总结相邻层的信息。
![]()
其中,Sl表示第l个特征,包含相对较多的空间细节,Cl+1表示包含更多上下文相关性的第(l+1)个特征。Θl和σl+1分别是Sl和Cl+1的学习因子。
我们的BCP模块也很轻,只有0.18M个参数。但BCP模块的有效性是。我们将BCP模块处理前后的功能图可视化,如图4所示。我们发现,在BCP模块处理之前,特征地图(图4(B))包含大量细节,如轮廓和纹理。但它不能用于最终预测。原因可以概括为两个方面。首先,它包含了太多的噪声,严重干扰了最终分类器的推理。第二,缺乏上下文信息,使得分类器对语义区域的感知能力较差。但是,经过BCP模块的处理后,特征映射(图4(C))获得了更多的语义感知。例如,他们更多地关注一些显著的语义区域,如人、车、树。此外,它的噪音明显较少。4.4节的消融也验证了我们的BCP模型的有效性。
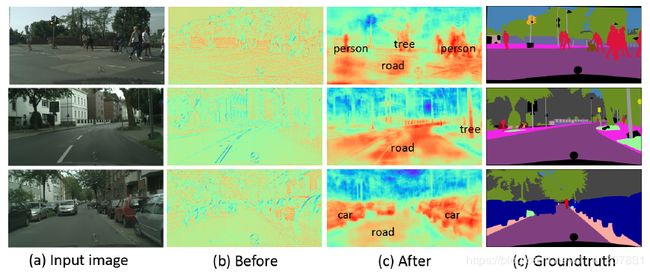
图4:我们的BCP模块处理前和处理后的第三层功能地图的可视化。特别地,对于(B)和(C),红色(蓝色)表示像素具有较高(较低)响应。
4 Experiments
在这一部分中,我们进行了明示实验来验证我们方法的有效性。首先,我们提供基于参数和浮点、速度和精度的分析。在此基础上,进行了烧蚀实验,考察了各组分对烧蚀效果的影响。
4.1 Parameters and FLOPs analysis
参数个数和FLOP个数是实时语义分割的重要评价标准。因此,在本节中,我们为我们的方法提供了广泛的参数和FLOP分析,如表1所示。为了更好地进行比较,我们将现有的相关方法分为四类,即大模型、中模型、小模型和小模型。1)大模型表示网络参数大于200M,FLOPS大于300G。2)中间模型表示网络的FLOP在100G到300G之间。3)小模型表示网络参数在1M到100M之间,或者FLOP在10G到100G之间。4)微型模型表示网络参数小于1M,FLOP小于10G。我们的BCPNet总共包含0.61M的参数。(2)中间模型是指网络的FLOP在100G到300G之间。3)小模型是指网络的参数在1M到100M之间,或者FLOP在10G到100G之间。即使对于1024×2048个输入图像,也只需要4.5G触发器。因此,如表1所示,我们将我们的BCPNet归类为微型模型。
表1:我们方法的FLOPS分析。
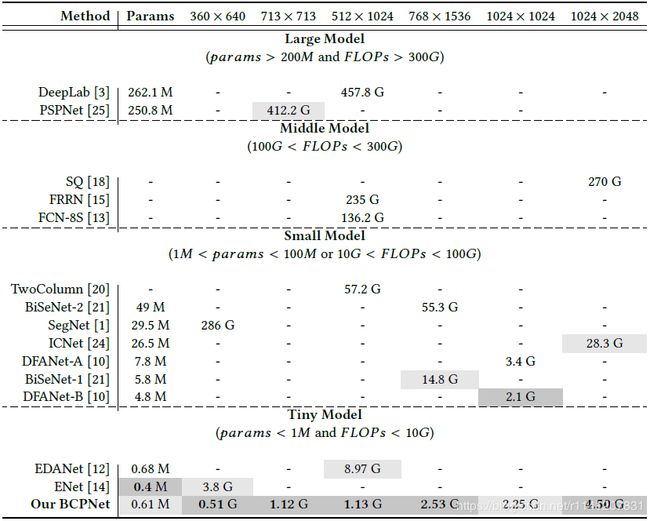
与小模型相比,我们的BCPNet表现出了一致的更好的性能。例如,对于两列[20],它的失败大约是我们的50倍。至于BiSeNet[21],我们的BCPNet只有大约1.2%的参数和4.5%的Flops的BiSeNet-2,而大约有10%的参数和17%的Flops的BiSeNet-1。对于ICNet[24],我们的BCPNet减少了大约98%的参数和84%的FLOP。至于DFANET的两个版本[10],我们的FLOP是可以比较的。但是我们的参数要少得多,例如,我们的BCPNet只有大约13%的DFANet-B和8%的DFANet-A的FLOP。
与其他微型模型相比,我们的BCPNet仍有更好的性能。至于ENET[14],虽然我们的BCPNet有更多的参数(大约多了0.2M),但它只有大约13%的ENET FLOP。对于EDANet[12],我们的参数数目是可以比较的。但是我们的BCPNet只有大约13%的EDANet故障。
4.2 Speed analysis
在这一部分中,我们为我们的方法提供了广泛的速度分析,如表2所示。特别是,对于表2,所有速度结果都是在单个GTX Titan X GPU卡上计算的。
与小模型相比,我们的BCPNet呈现出一致的更快的执行速度。例如,对于两列[20],我们的BCPNet在512×104输入图像的基础上实现了大约235.7 FPS的速度。至于BiSeNet的两个版本[21],我们的BCPNet对于所有不同的输入分辨率都更快。例如,基于360×640FPS的输入图像,我们的BCPNet比BISeNet-2快了约456.5 FPS,比BISeNet-1快了382.4 FPS。基于720×1280幅输入图像,我们的BCPNet比BiSeNet-2快86.9FPS,比BiSeNet-1快52.5FPS。至于ICNet[24],它在1024×2048个输入图像的基础上已经达到了30.3FPS,我们的BCPNet的速度大约是25FPS。对于两个版本的DFANet[10],基于720×960输入图像,我们的BCPNet比DFANet-A快了约60FPS,比DFANet-B快了20FPS。对于1024×1024的输入图像,BCPNet和DFANet-B相当,但比DFANet-A快约16FPS。
表2:我们的BCPNet的速度分析。具体地说,所有执行速度的结果都是在单个Titan X GPU卡上计算的。

与微小模型相比,我们的方法仍然产生了更好的性能。例如,对于ENET,基于360×630的输入图像,我们的BCPNet已经实现了大约450FPS的速度;基于720×1280的输入图像,我们的BCPNet已经实现了大约88FPS的速度。对于EDANet,基于512×1024的输入图像,我们的BCPNet的速度大约是169FPS。
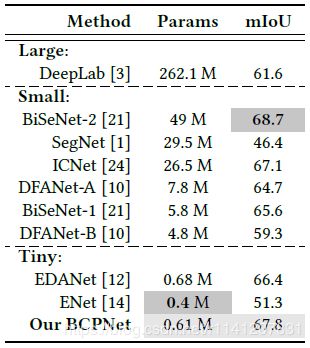
表3我们的方法在城市景观测试集上的结果 表4我们的方法在CamVid测试集上的结果。
4.3 Accuracy analysis
在这一部分中,我们对我们的方法进行了精度分析。首先,我们介绍了实验的实现细节。然后,我们在城市景观[5]和CamVid[2]数据集上将我们的方法与当前最先进的方法进行了比较。
4.3.1 Implement details
我们基于pytorch平台1构建代码。lr=init_lr×(1-itertotal_iter)power![]() 。对于所有实验,我们将初始学习率设置为0.1,幂设置为0.9。为了减少过拟合的风险,我们在实验中采用了数据增强的方法。例如,我们将输入图像从0.5随机翻转和缩放为2。我们选择随机梯度下降(SGD)作为我们的训练优化器,其中动量设置为0.9,权重衰减设置为0.00001。对于CamVid数据集,我们将裁剪大小和小批量设置为720×720和48。对于城市景观数据集,我们将裁剪大小设置为1024×1024。但是,由于GPU资源有限,我们将小批量设置为36。对于所有的实验,训练过程将在200个迭代之后结束。
。对于所有实验,我们将初始学习率设置为0.1,幂设置为0.9。为了减少过拟合的风险,我们在实验中采用了数据增强的方法。例如,我们将输入图像从0.5随机翻转和缩放为2。我们选择随机梯度下降(SGD)作为我们的训练优化器,其中动量设置为0.9,权重衰减设置为0.00001。对于CamVid数据集,我们将裁剪大小和小批量设置为720×720和48。对于城市景观数据集,我们将裁剪大小设置为1024×1024。但是,由于GPU资源有限,我们将小批量设置为36。对于所有的实验,训练过程将在200个迭代之后结束。
4.3.2 Cityscapes
城市景观[5]数据集由5,000张注释精细的图像和20000张注释粗略的图像组成。在我们的实验中,只使用了经过精细注释的子集。该数据集共包括30个语义类。在[25,26]之后,我们只使用了其中的19个类。精细注释子集包含2975个用于训练的图像、500个用于验证的图像和1525个用于测试的图像。
Performance:与中间模型相比,我们的方法的精度稍差一些,但仍然足够好。例如,对于SQ[18],它的FLOP是我们的60倍,我们的BCPNet的准确率仍然高出8.6%左右。对于FRRM[15],它的准确率比我们的BCPNet提高了3.4%。但是我们的BCPNet只有0.5%的FRRN故障。此外,基于512×1024幅输入图像,我们的BCPNet比FRRN快了约248 FPS。对于FCN-8S[13],其FLOP约为我们的120倍,BCPNet的准确率仍高出约5.3%。
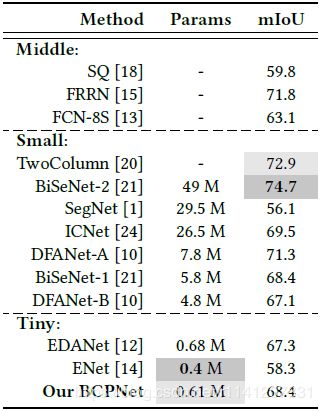
与小模型相比,BCPNet达到了与ICNet[24]、DFANet-B[10]和BiSeNet-1[21]相当的精度。但是我们的BCPNet的参数要少得多。例如,ICNet的参数大约是我们的43倍,DFANet-B的参数大约是我们的7.8倍,BiSeNet-1的参数大约是我们的9.5倍。对于两列[20],其错误率约为我们的50倍,我们的BCPNet的准确率降低了约4.5%。对于参数约为我们80倍的BiSeNet-2[21],我们的BCPNet准确率降低了6.3%左右。但是我们发现,我们的BCPNet比Twocolum和BiSeNet-2要快得多。例如,基于512×1024幅输入图像,我们的方法比两列快约235FPS。基于360×640幅输入图像,我们的方法达到了大约456FPS的速度。然而,我们发现我们的方法的精度仍然远远高于SegNet[1](大约比我们高12.3%),后者的参数和FLOP分别是我们的48倍和560倍。
与其他微型模型相比,BCPNet呈现出一致更好的性能。例如,对于ENET[14],我们的方法的准确率提高了约10.1%。对于EDANet[12],我们的方法的准确率提高了约1.1%。
我们在图5中可视化了我们方法的一些分割结果。

图5:我们的方法在城市景观数据集上的可视化分割结果。
4.3.3 CamVid
CamVid数据集[2]是从道路感官的高分辨率视频序列中收集的。该数据集包含367个用于训练的图像、101个用于验证的图像和233个用于测试的图像。该数据集共包括32个语义类。但在文献[10,24]之后,我们的实验中只使用了其中的11个类别。
Performance:虽然我们的BCPNet包含轻量级的参数和FLOP,但它的准确性比大多数当前最先进的方法都要高。与DeepLab[3]相比,BCPNet的准确率仍高出6.2%左右。DeepLab[3]的参数和FLOP大约是DeepLab[3]的429倍和408倍。与SegNet[1]相比,我们的BCPNet的准确率仍然提高了12.3%左右。SegNet的参数和浮点数分别是我们的48倍和560倍。与ICNet[24]相比,我们的BCPNet的准确率提高了0.7%左右。ICNet的参数和浮点数分别是我们的43倍和6.2倍。与DFANet的两个版本[10]相比,我们的BCPNet呈现出一致的更好的性能。例如,对于参数大约是我们的12.7倍的DFANet-A,我们的方法的准确率高达67.8%。对于参数是我们的7.8倍左右的DFANet-B,我们的方法的准确率提高了8.5%左右。与两个微小模型相比,我们的方法比EDANet[12]提高了约1.1%的精度,比ENET[14]提高了约10.1%。虽然我们的方法的准确率比BiSeNet-2[21]低6.3%左右,但是我们的BCPNet只有大约1.2%的BiSeNet-1参数。此外,与参数约为我们9倍的BiSeNet-2相比,我们的BCPNet的准确率提高了1.3%左右。
4.4 Ablation study
在这一部分,我们进行一项消融研究,以调查我们的方法的组成部分对最终准确性的影响。如表5所示,我们发现在没有我们的上下文反向传播机制čň的情况下,包含0.43M个参数的骨干网络在城市景观验证集上只能达到58.891%的MIU。应用该模型,在仅增加0.18M参数的情况下,模型精度提高到67.842%MIU(提高约9%)。这证明了我们的BCP模块的有效性。我们进一步研究了上下文聚合中使用的不同池操作的影响。我们发现,使用3×3最大值的池化可以产生更好的性能。当我们用3×3平均池化代替3×3最大池化时,性能下降到67.311%MIU(大约降低0.5%)。当我们用5×5最大池化代替3×3最大池化时,性能下降到65.763%MIU(大约降低2%)。我们认为这是由于(相对)较大的核大小和(相对)较小的特征分辨率之间的不匹配造成的。正如文献[8]所提到的,作物大小对最终的精度起着重要的作用。我们发现,使用更大的作物大小会产生更好的性能。当我们在训练过程中采用1024×1024作物大小时,性能提高到68.626%MIU。
表5:我们的方法在城市景观验证集上的消融研究。

5 Conclusion
本文基于提出的上下文反向传播机制,提出了一种新的双向上下文传播网络(BCPNet)。我们发现,与传统的空间细节传输方法相比,将上下文信息反向传播到浅层在计算上更为谦虚。这使得我们的BCPNet能够实时地进行语义切分。广泛的实验证明,我们的BCPNet在精度和速度之间达到了最新的平衡。