ECCV2020 | FReLU:旷视提出一种新的激活函数,实现像素级空间信息建模
点击上方“AI算法修炼营”,选择“星标”公众号
精选作品,第一时间送达

这篇文章收录于ECCV2020,是旷视科技和香港理工大学发表一篇关于新的激活函数的文章。主要的创新点是在激活函数阶段实现像素级的空间信息建模能力,能够用于目标检测、语义分割等目标识别任务,简单又高效!
论文地址:https://arxiv.org/pdf/2007.11824.pdf
代码地址:https://github.com/megvii-model/FunnelAct
本文提出了一种用于图像识别任务的简单但有效的激活函数,称为Funnel 激活函数(FReLU),它通过增加可忽略的空间条件开销将ReLU和PReLU扩展为2D激活函数。ReLU和PReLU分别表示为y = max(x,0)和y = max(x,px)的形式,而FReLU的形式为y = max(x,T(x)),其中T(·)是二维空间条件(2D spatial condition)。此外,空间条件spatial condition以简单的方式实现了像素级建模能力,并通过常规卷积捕获了复杂的视觉layouts。最后,对ImageNet数据集、COCO数据集检测任务和语义分割任务进行了实验,展示了FReLU激活函数在视觉识别任务中的巨大改进和鲁棒性。
简介
卷积神经网络(CNN)在许多视觉识别任务(例如图像分类,目标检测和语义分割)中均达到了最先进的性能。在CNN中主要的层是卷积层和非线性激活层,在卷积层中,自适应地捕获空间相关性是一个挑战,因此,研究者已经提出了许多更复杂和有效的卷积来在图像中自适应地捕获局部上下文信息,这在密集的预测任务(例如,语义分割和目标检测)上取得了不错的性能提升。但随着卷积的复杂性也带来了一个问题:常规的卷积能否达到类似的精度,以掌握具有挑战性的复杂图像呢?
其次,通常就在卷积层线性捕捉空间依赖性后,再由激活层进行非线性变换。目前最广泛使用的激活仍然是ReLU激活函数,于是有了另一个问题:能否设计一种专门针对视觉任务的激活函数?
为了回答上面提出的两个问题,本文表明简单但有效的视觉激活函数以及常规卷积也可以对密集和稀疏预测任务(例如图像分类,见图1)都能实现显著改善。为了实现这一结果,作者认为激活函数中的空间不敏感是阻碍视觉任务实现显著改善的主要原因,并基于此提出了一种新的视觉激活函数,以消除这一障碍。
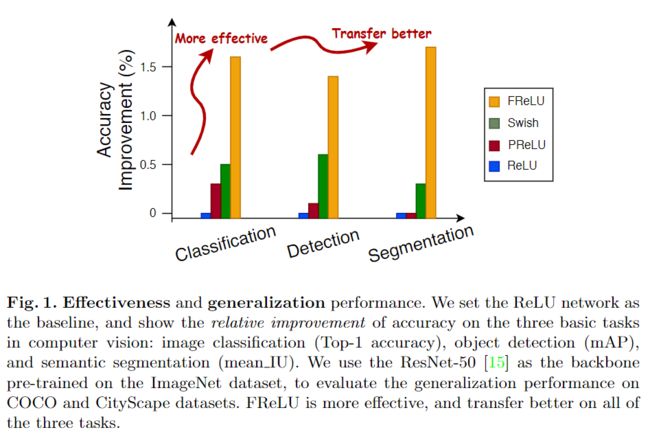
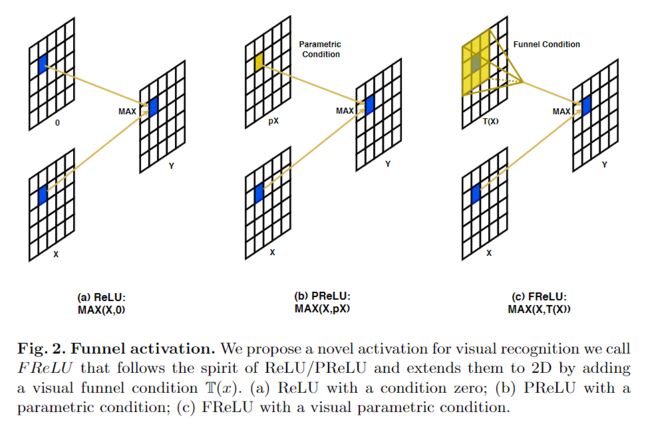
本文的方法被称为Funnel激活函数(FReLU),通过增加一个空间条件(见图2)来扩展ReLU/PReLU函数,它的实现很简单,只增加了一个可以忽略不计的计算开销。该激活函数的形式是y=max(x,T(x)),其中T(x)代表简单高效的空间上下文特征提取器。由于使用了空间条件,FReLU简单地将ReLU和PReLU扩展为具有像素化建模能力的视觉参数化ReLU。
本文提出的视觉激活函数是一种有效的方法,但是比以前的激活函数更有效。为了证明所提出的视觉激活函数的有效性,实验环节中,在分类网络中替换了正常的ReLU,并使用经过预训练的主干网络来显示其在其他两个基本视觉任务上的通用性:目标检测和语义分割。结果表明,FReLU不仅可以提高单个任务的性能,而且可以很好地迁移到其他视觉任务。
ReLU和PReLU
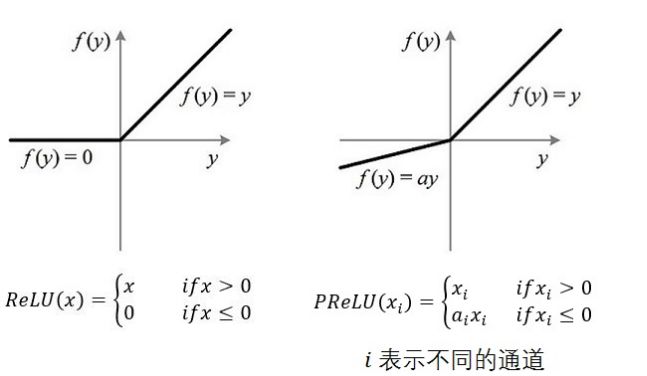
如果ai=0,那么PReLU退化为ReLU;如果ai是一个很小的固定值(如ai=0.01),则PReLU退化为Leaky ReLU(LReLU)。有实验证明,与ReLU相比,LReLU对最终的结果几乎没什么影响。
PReLU只增加了极少量的参数,也就意味着网络的计算量以及过拟合的危险性都只增加了一点点。特别的,当不同channels使用相同的ai时,参数就更少了。
BP更新ai时,采用的是带动量的更新方式,如下图:

上式的两个系数分别是动量和学习率。
需要特别注意的是:更新ai时不施加权重衰减(L2正则化),因为这会把ai很大程度上push到0。事实上,即使不加正则化,实验中ai也很少有超过1的。原始论文中,ai被初始化为0.25。
本文方法:Funnel Activation
FReLU是专门为视觉任务而设计的,概念上很简单:ReLU的条件是一个手工设计的零值,PReLU的条件是一个参数化的px,对此FReLU将其修改为一个依赖于空间上下文的二维漏斗状条件,视觉条件有助于提取物体的精细空间布局。接下来,将介绍FReLU的关键部分,包括漏斗条件funnel condition和像素化建模能力,这些都是ReLU及其变体中缺少的主要部分。
FReLU函数采用与简单非线性函数相同的max(·)。对于条件部分,FReLU将其扩展为二维条件,具体取决于每个像素的空间上下文(可参见上面图2)。这与其他最近的方法不同,其他方法的条件通常取决于像素本身或通道上下文。然后,使用max(·)获得x和条件之间的最大值。
作者将 funnel condition定义为T(x)。为了实现空间条件spatial condition,使用参数化池窗口(Parametric Pooling Window)来创建空间依赖性(使用高度优化的深度可分离卷积算符和BN层来实现),具体来说,定义激活函数为:
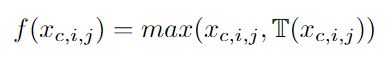

Pixel-wise modeling capacity逐像素建模能力
funnel条件的定义使得网络可以在每个像素的非线性激活中产生空间条件。该网络同时进行非线性变换并产生空间依赖性,而通常的做法是在卷积层创建空间依赖性,并分别进行非线性变换。在通常做法下,激活过程不明确地依赖于空间条件;而在funnel条件的情况下,它们依赖于空间条件。
因此,pixel-wise condition使得网络具有像素化的建模能力,函数max(·)给每个像素提供了一个看空间背景或不看空间背景的选择。具体地,考虑一个有n个FReLU层的网络{F1,F2,...,Fn},每个FReLU层Fi有k×k个参数窗口。为了简洁起见,只分析FReLU层,而不考虑卷积层。由于最大选择在1×1和k×k之间,所以F1之后的每个像素都有一个激活函数集{1,1+r}(r=k-1)。在Fn层之后,该集合变成了{1,1 +r,1 + 2r,...,1 +nr},这给每个像素提供了更多的选择,如果n足够大,可以近似于任何布局。有许多不同大小的方块时,不同大小的方块可以近似于斜线和弧线的形状(见图3)。
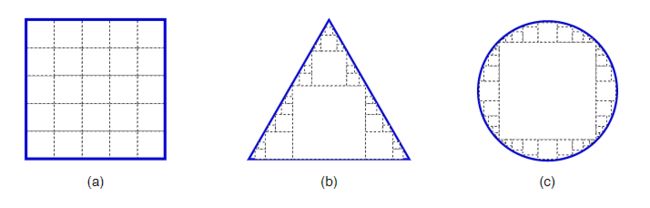
图3 描述了funnel条件如何实现像素化建模能力。图中不同大小的正方形代表了顶部激活层中每个像素的不同激活场。(a)正常的激活场,每像素的方块大小相等,只能描述水平和垂直布局。与此相反,max(·)允许每个像素选择在每层中寻找或不寻找,在足够多的层数后,它们有许多不同大小的方块。因此,不同大小的方块可以近似于(b)斜线的形状,(c)弧线的形状,这些都是比较常见的自然物体布局。
我们知道,图像中物体的布局通常不是水平或垂直的,它们通常是斜线或弧线的形状,因此提取物体的空间结构可以通过空间条件提供的像素化建模能力自然解决。通过实验表明,在复杂的任务中,它能较好地捕捉到不规则和详细的物体布局(见图4)。
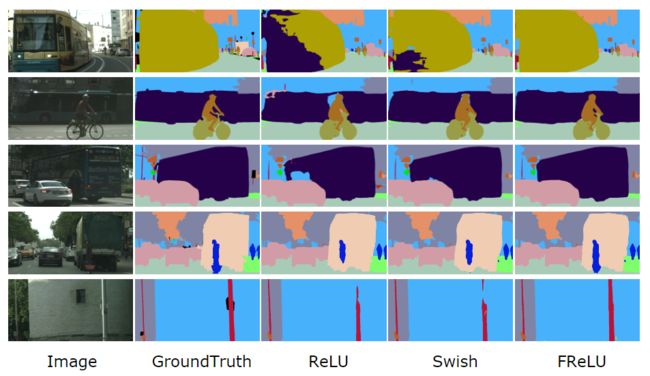
图4.具有不同激活函数的ResNet-50-PSPNet上语义分割效果的可视化。裁剪了CityScape图像以使差异更加清晰(更好的视图放大图像)。FReLU具有更好的上下文捕获能力,因此对大型或细长的对象和小型的对象有更好的理解。在复杂情况下,它可以更好地捕获不规则和详细的对象布局。很多网络框架已对ReLU进行了优化,但是,仅更改主干就具有明显的改进,因此,如果重新设计视觉激活函数框架,则有可能获得进一步的收益。
class FReLU(M.Module):
r""" FReLU formulation. The funnel condition has a window size of kxk. (k=3 by default)
"""
def __init__(self, in_channels):
super().__init__()
self.conv_frelu = M.Conv2d(in_channels, in_channels, 3, 1, 1, groups=in_channels)
self.bn_frelu = M.BatchNorm2d(in_channels)
def forward(self, x):
x1 = self.conv_frelu(x)
x1 = self.bn_frelu(x1)
x = F.maximum(x, x1)
return x实验与结果
1、 Image Classification任务
数据集:ImageNet 2012 classification dataset
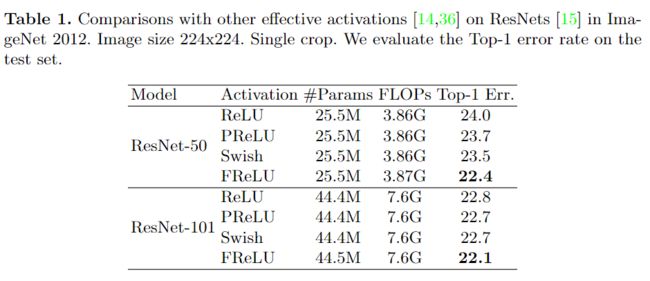
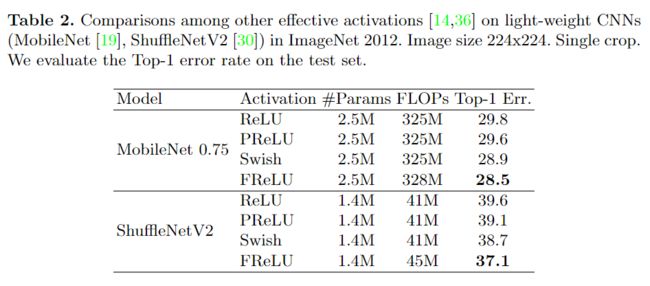
2、目标检测任务
数据集:COCO dataset
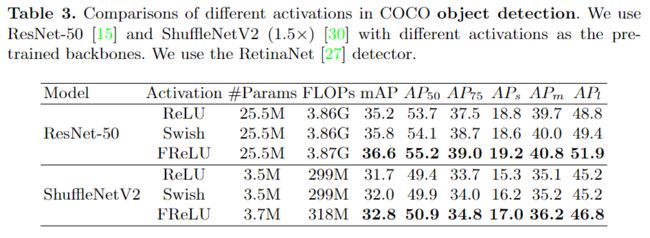
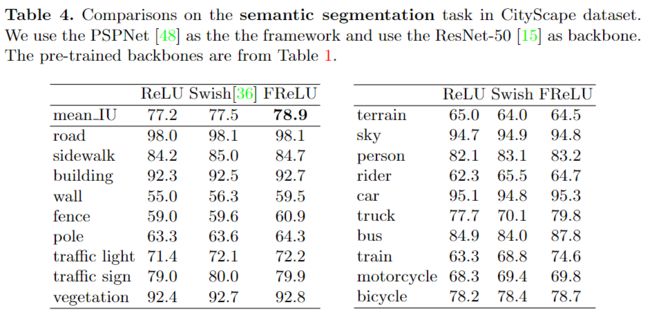
3、语义分割任务
数据集:CityScapes
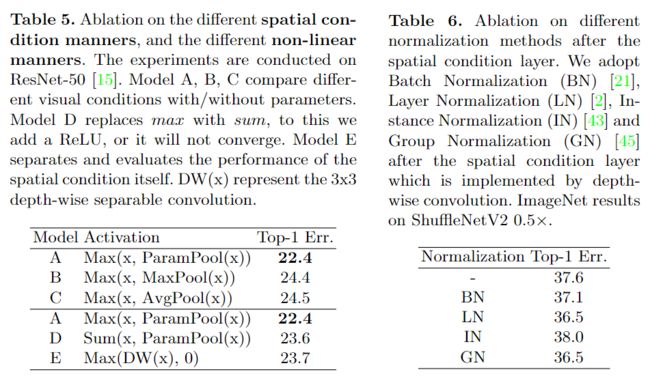
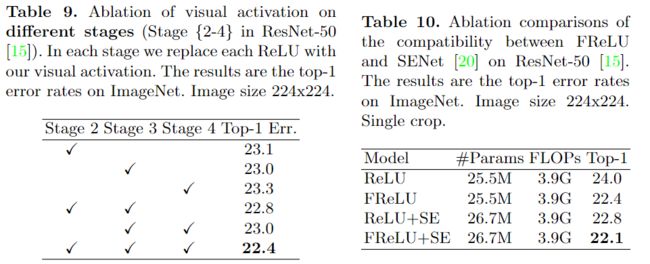
消融实验

更多细节可参考论文原文。
![]()

