生成对抗网络(GAN、DCGAN、ACGAN)-----学习笔记
生成对抗网络学习笔记
生成对抗网络有两个关键结构:生成模型、判别模型。
生成模型:输入是一个服从正态分布的N维向量,利用这个N维向量生成一张图片。
判别模型:对于生成模型输出的图像判别它是不是真的图像。
生成模型和判别模型的博弈关系在于:生成模型的目的是生成让判别模型无法判别真伪的图像,而判别模型的目的是判断输入图像的真伪。
结合代码来看生成对抗网络中,生成器和判别器的训练过程:
判别模型的训练过程:判别模型的输入是一张带标签的图片,输出为判别器对图片的识别结果(真图片1/假图片0)。将生成模型的输出结果和标签进行比较,如果判断错了,则继续对判别模型进行训练;如果判断正确,可以减少对判别模型的训练。
生成模型的训练过程:生成模型的训练用到判别模型输出结果。生成模型用N维向量生成假的图片输入到判别模型中,如果判别模型的输出为0,也就是判别模型识别出了图片是假的,那么就需要继续训练生成模型;如果判别模型的输出为1,说明生成模型已经生成了“以假乱真”的图片,则可以减少对生成模型的训练。
生成模型和判别模型的训练过程是分开进行的。
1.GAN
1、生成器和判别器的结构
在代码中:
生成器的结构
def build_generator(self):
model = Sequential()
model.add(Dense(256, input_dim=self.latent_dim))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(512))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(1024))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(np.prod(self.img_shape), activation='tanh'))
model.add(Reshape(self.img_shape))
noise = Input(shape=(self.latent_dim,))
img = model(noise)
return Model(noise, img)
生成器的输入是服从正态分布的N维向量noise;
输出是一张图片img
生成模型的网络结构:

用dense来构建网络结构进行特征提取。
程序中判别器的结构:
def build_discriminator(self):
model = Sequential()
# 输入一张图片
model.add(Flatten(input_shape=self.img_shape))
model.add(Dense(512))
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(256))
model.add(LeakyReLU(alpha=0.2))
# 判断真伪,用sigmoid分类器。1表示判别为真图像,0表示判别为假图像。
model.add(Dense(1, activation='sigmoid'))
img = Input(shape=self.img_shape)
validity = model(img)
return Model(img, validity)
从程序中得到判别器的输入是一张图片,输出是对图片真伪的判别结果,输出1或者0。sigmoid分类器用于分类网络。
判别模型的网络结构:

原始的生成对抗网络使用全连接网络进行特征提取
2、生成和判别器的训练方式
def train(self, epochs, batch_size=128, sample_interval=50):
(X_train, _), (_, _) = mnist.load_data()
X_train = X_train / 127.5 - 1.
X_train = np.expand_dims(X_train, axis=3)
使用Mnist数据集,把数据格式转化成特征层的表达形式:HWC
valid = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
建立标签:真的图片标签为1、假的图片标签为0.
在网络上训练之前,说一下训练的损失函数是交叉熵,loss='binary_crossentropy'
def __init__(self):
self.img_rows = 28
self.img_cols = 28
self.channels = 1
self.img_shape = (self.img_rows, self.img_cols, self.channels)
self.latent_dim = 100
optimizer = Adam(0.0002, 0.5)
self.discriminator = self.build_discriminator()
# loss:交叉熵
# 用于生成器和判别器的训练
self.discriminator.compile(loss='binary_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])
self.generator = self.build_generator()
gan_input = Input(shape=(self.latent_dim,))
img = self.generator(gan_input)
self.discriminator.trainable = False
validity = self.discriminator(img)
# 生成器的训练用到了判别器的结果
self.combined = Model(gan_input, validity)
self.combined.compile(loss='binary_crossentropy', optimizer=optimizer)
由于生成器的训练需要用到判别器的输出,首先对判别器进行训练。
idx = np.random.randint(0, X_train.shape[0], batch_size)
imgs = X_train[idx]
noise = np.random.normal(0, 1, (batch_size, self.latent_dim))
gen_imgs = self.generator.predict(noise)
d_loss_real = self.discriminator.train_on_batch(imgs, valid)
d_loss_fake = self.discriminator.train_on_batch(gen_imgs, fake)
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
训练判别器的时候调用build_discriminator,对于输入图像(有标签),如果图片是真,将判别器的输出结果与1进行比较,如果输出结果与1相差较大(说明判别器判断错误),那么继续对判别器进行训练。如果判别器判断正确,就减少对判别器的训练。
生成器的训练过程:
noise = np.random.normal(0, 1, (batch_size, self.latent_dim))
g_loss = self.combined.train_on_batch(noise, valid)
再重新生成一个N维向量,输入到判别模型中,得到输出结果如果结果为0(即判别器识别出了图像为假),则需要进一步训练生成器。
而且生成模型的训练和判别模型的训练是分开进行的。
至此就完成了生成对抗网络的训练,迭代30000次生成图片的结果如图所示:

GAN完整代码如下
from keras.datasets import mnist
from keras.layers import Input, Dense, Reshape, Flatten, Dropout
from keras.layers import BatchNormalization, Activation, ZeroPadding2D
from keras.layers.advanced_activations import LeakyReLU
from keras.models import Sequential, Model
from keras.optimizers import Adam
import matplotlib.pyplot as plt
import sys
import os
import numpy as np
class GAN():
def __init__(self):
self.img_rows = 28
self.img_cols = 28
self.channels = 1
self.img_shape = (self.img_rows, self.img_cols, self.channels)
self.latent_dim = 100
optimizer = Adam(0.0002, 0.5)
self.discriminator = self.build_discriminator()
self.discriminator.compile(loss='binary_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])
self.generator = self.build_generator()
gan_input = Input(shape=(self.latent_dim,))
img = self.generator(gan_input)
self.discriminator.trainable = False
validity = self.discriminator(img)
self.combined = Model(gan_input, validity)
self.combined.compile(loss='binary_crossentropy', optimizer=optimizer)
def build_generator(self):
model = Sequential()
model.add(Dense(256, input_dim=self.latent_dim))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(512))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(1024))
model.add(LeakyReLU(alpha=0.2))
model.add(BatchNormalization(momentum=0.8))
model.add(Dense(np.prod(self.img_shape), activation='tanh'))
model.add(Reshape(self.img_shape))
noise = Input(shape=(self.latent_dim,))
img = model(noise)
return Model(noise, img)
def build_discriminator(self):
model = Sequential()
model.add(Flatten(input_shape=self.img_shape))
model.add(Dense(512))
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(256))
model.add(LeakyReLU(alpha=0.2))
model.add(Dense(1, activation='sigmoid'))
img = Input(shape=self.img_shape)
validity = model(img)
return Model(img, validity)
def train(self, epochs, batch_size=128, sample_interval=50):
(X_train, _), (_, _) = mnist.load_data()
X_train = X_train / 127.5 - 1.
X_train = np.expand_dims(X_train, axis=3)
valid = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
for epoch in range(epochs):
idx = np.random.randint(0, X_train.shape[0], batch_size)
imgs = X_train[idx]
noise = np.random.normal(0, 1, (batch_size, self.latent_dim))
gen_imgs = self.generator.predict(noise)
d_loss_real = self.discriminator.train_on_batch(imgs, valid)
d_loss_fake = self.discriminator.train_on_batch(gen_imgs, fake)
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
noise = np.random.normal(0, 1, (batch_size, self.latent_dim))
g_loss = self.combined.train_on_batch(noise, valid)
print("%d [D loss: %f, acc.: %.2f%%] [G loss: %f]" % (epoch, d_loss[0], 100*d_loss[1], g_loss))
if epoch % sample_interval == 0:
self.sample_images(epoch)
def sample_images(self, epoch):
r, c = 5, 5
noise = np.random.normal(0, 1, (r * c, self.latent_dim))
gen_imgs = self.generator.predict(noise)
gen_imgs = 0.5 * gen_imgs + 0.5
fig, axs = plt.subplots(r, c)
cnt = 0
for i in range(r):
for j in range(c):
axs[i,j].imshow(gen_imgs[cnt, :,:,0], cmap='gray')
axs[i,j].axis('off')
cnt += 1
fig.savefig("images/%d.png" % epoch)
plt.close()
if __name__ == '__main__':
if not os.path.exists("./images"):
os.makedirs("./images")
gan = GAN()
gan.train(epochs=30000, batch_size=256, sample_interval=200)
2. DCGAN(特征提取的网络换成了卷积神经网络)
DCGAN的生成模型和判别模型的训练过程与GAN相同。
只是模型的特征提取网络发生了改变
生成模型的结构:
def build_generator(self):
model = Sequential()
model.add(Dense(32 * 7 * 7, activation="relu", input_dim=self.latent_dim))
model.add(Reshape((7, 7, 32)))
model.add(Conv2D(64, kernel_size=3, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(Activation("relu"))
model.add(UpSampling2D())
model.add(Conv2D(128, kernel_size=3, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(Activation("relu"))
model.add(UpSampling2D())
model.add(Conv2D(64, kernel_size=3, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(Activation("relu"))
model.add(Conv2D(self.channels, kernel_size=3, padding="same"))
model.add(Activation("tanh"))
noise = Input(shape=(self.latent_dim,))
img = model(noise)
return Model(noise, img)
网络结构如图:

判别模型的网络模型代码:
def build_discriminator(self):
model = Sequential()
model.add(Conv2D(32, kernel_size=3, strides=2, input_shape=self.img_shape, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(LeakyReLU(alpha=0.2))
model.add(Conv2D(64, kernel_size=3, strides=2, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(LeakyReLU(alpha=0.2))
model.add(ZeroPadding2D(((0,1),(0,1))))
model.add(Conv2D(128, kernel_size=3, strides=2, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(LeakyReLU(alpha=0.2))
model.add(GlobalAveragePooling2D())
model.add(Dense(1, activation='sigmoid'))
img = Input(shape=self.img_shape)
validity = model(img)
return Model(img, validity)
判别模型的网络结构如图所示:

总之,DCGAN网络的训练过程和GAN的训练过程相同,只是把特征提取网络变成了卷积。由于加了卷积后训练速度变慢了,用我的小笔记本只迭代了1000次,
生成的图片如图:

得出直观但不严谨的结论,经过相同的迭代次数,DCGAN生成的图片真的比GAN 生成的图片质量高:)
DCGAN完整代码:
from __future__ import print_function, division
from keras.datasets import mnist
from keras.layers import Input, Dense, Reshape, Flatten, Dropout
from keras.layers import BatchNormalization, Activation, ZeroPadding2D, GlobalAveragePooling2D
from keras.layers.advanced_activations import LeakyReLU
from keras.layers.convolutional import UpSampling2D, Conv2D
from keras.models import Sequential, Model
from keras.optimizers import Adam
import matplotlib.pyplot as plt
import sys
import os
import numpy as np
class DCGAN():
def __init__(self):
self.img_rows = 28
self.img_cols = 28
self.channels = 1
self.img_shape = (self.img_rows, self.img_cols, self.channels)
self.num_classes = 10
self.latent_dim = 100
optimizer = Adam(0.0002, 0.5)
self.discriminator = self.build_discriminator()
self.discriminator.compile(loss=['binary_crossentropy'],
optimizer=optimizer,
metrics=['accuracy'])
self.generator = self.build_generator()
z = Input(shape=(self.latent_dim,))
img = self.generator(z)
self.discriminator.trainable = False
valid = self.discriminator(img)
self.combined = Model(z, valid)
self.combined.compile(loss='binary_crossentropy', optimizer=optimizer)
def build_generator(self):
model = Sequential()
model.add(Dense(32 * 7 * 7, activation="relu", input_dim=self.latent_dim))
model.add(Reshape((7, 7, 32)))
model.add(Conv2D(64, kernel_size=3, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(Activation("relu"))
model.add(UpSampling2D())
model.add(Conv2D(128, kernel_size=3, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(Activation("relu"))
model.add(UpSampling2D())
model.add(Conv2D(64, kernel_size=3, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(Activation("relu"))
model.add(Conv2D(self.channels, kernel_size=3, padding="same"))
model.add(Activation("tanh"))
print('generator')
model.summary()
noise = Input(shape=(self.latent_dim,))
img = model(noise)
return Model(noise, img)
def build_discriminator(self):
model = Sequential()
model.add(Conv2D(32, kernel_size=3, strides=2, input_shape=self.img_shape, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(LeakyReLU(alpha=0.2))
model.add(Conv2D(64, kernel_size=3, strides=2, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(LeakyReLU(alpha=0.2))
model.add(ZeroPadding2D(((0,1),(0,1))))
model.add(Conv2D(128, kernel_size=3, strides=2, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(LeakyReLU(alpha=0.2))
model.add(GlobalAveragePooling2D())
model.add(Dense(1, activation='sigmoid'))
print('discriminator')
model.summary()
img = Input(shape=self.img_shape)
validity = model(img)
return Model(img, validity)
def train(self, epochs, batch_size=128, save_interval=50):
(X_train, _), (_, _) = mnist.load_data()
X_train = X_train / 127.5 - 1.
X_train = np.expand_dims(X_train, axis=3)
valid = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
for epoch in range(epochs):
idx = np.random.randint(0, X_train.shape[0], batch_size)
imgs = X_train[idx]
noise = np.random.normal(0, 1, (batch_size, self.latent_dim))
gen_imgs = self.generator.predict(noise)
d_loss_real = self.discriminator.train_on_batch(imgs, valid)
d_loss_fake = self.discriminator.train_on_batch(gen_imgs, fake)
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
g_loss = self.combined.train_on_batch(noise, valid)
print("%d [D loss: %f, acc.: %.2f%%] [G loss: %f]" % (epoch, d_loss[0], 100*d_loss[1], g_loss))
if epoch % save_interval == 0:
self.save_imgs(epoch)
def save_imgs(self, epoch):
r, c = 5, 5
noise = np.random.normal(0, 1, (r * c, self.latent_dim))
gen_imgs = self.generator.predict(noise)
gen_imgs = 0.5 * gen_imgs + 0.5
fig, axs = plt.subplots(r, c)
cnt = 0
for i in range(r):
for j in range(c):
axs[i,j].imshow(gen_imgs[cnt, :,:,0], cmap='gray')
axs[i,j].axis('off')
cnt += 1
fig.savefig("images/mnist_%d.png" % epoch)
plt.close()
if __name__ == '__main__':
if not os.path.exists("./images"):
os.makedirs("./images")
dcgan = DCGAN()
dcgan.train(epochs=1000, batch_size=256, save_interval=50)
3、ACGAN(在DCGAN基础上增加了图像标签)
ACGAN可以看做在原始的GAN基础上将特征提取网络变成了卷积,而且给图像增加了标签。在手写数字MNIST数据集中可以指定生成哪个数字的图片。
在ACGAN中,生成模型生成得图片是有标签的。
生成模型的结构:
def build_generator(self):
model = Sequential()
# 把输入的N维向量先全连接到32*7*7的维度上
model.add(Dense(32 * 7 * 7, activation="relu", input_dim=self.latent_dim))
# reshape成特征层的样式
model.add(Reshape((7, 7, 32)))
model.add(Conv2D(64, kernel_size=3, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(Activation("relu"))
model.add(UpSampling2D())
model.add(Conv2D(128, kernel_size=3, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(Activation("relu"))
model.add(UpSampling2D())
model.add(Conv2D(64, kernel_size=3, padding="same"))
model.add(BatchNormalization(momentum=0.8))
model.add(Activation("relu"))
model.add(Conv2D(self.channels, kernel_size=3, padding="same"))
model.add(Activation("tanh"))
model.summary()
noise = Input(shape=(self.latent_dim,))
label = Input(shape=(1,), dtype='int32')
label_embedding = Flatten()(Embedding(self.num_classes, self.latent_dim)(label))
model_input = multiply([noise, label_embedding])
img = model(model_input)
return Model([noise, label], img)
在生成模型中,ACGAN把输入的N维向量增加了标签Embedding(self.num_classes, self.latent_dim)(label)。函数Embedding的作用是将正整数(索引值)转换为固定尺寸的稠密向量。即输入到生成模型中的是带有标签的N维向量。生成网络的输出是一张带有标签的图片。
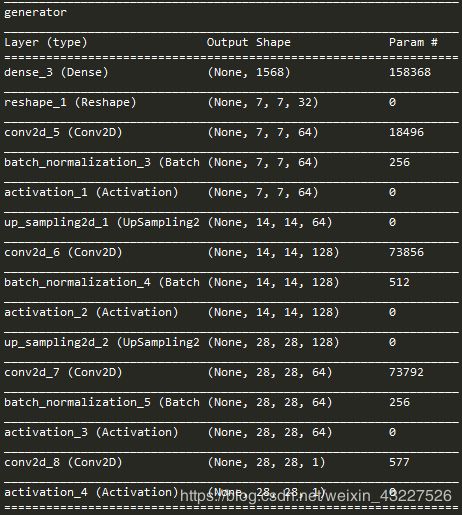
生成模型的网络结构如图所示:
判别模型的代码:
def build_discriminator(self):
model = Sequential()
model.add(Conv2D(16, kernel_size=3, strides=2, input_shape=self.img_shape, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(Conv2D(32, kernel_size=3, strides=2, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(BatchNormalization(momentum=0.8))
model.add(ZeroPadding2D(padding=((0,1),(0,1))))
model.add(Conv2D(64, kernel_size=3, strides=2, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(BatchNormalization(momentum=0.8))
model.add(Conv2D(128, kernel_size=3, strides=1, padding="same"))
model.add(LeakyReLU(alpha=0.2))
model.add(Dropout(0.25))
model.add(GlobalAveragePooling2D())
img = Input(shape=self.img_shape)
features = model(img)
validity = Dense(1, activation="sigmoid")(features)
label = Dense(self.num_classes, activation="softmax")(features)
return Model(img, [validity, label])
判别模型性的输入是一张图片img,输出模型是判别图像真伪的结果validity和图片所属类别label。
判别模型的网络结构:

判别模型的训练规则:
简而言之,判别模型的输入是一张有标签的图片,判别模型输出判断图像真伪的结果:如果判断错误则继续训练判别模型,如果判断正确1、判断结果为真图片:与真实图片和对应的标签进行比较;2、判断结果为假图片:与生成模型生成的假图片进行比较,得到图片所属类别(MNIST数据集中的数字0-9)。
生成器的训练过程和原始的GAN生成器的训练过程相同。只是增加了图像的标签,还有一步判别生成的图像是不是规定的生成图片的类别。
迭代了600次的输出图像:

感谢
https://blog.csdn.net/weixin_44791964/article/details/103729797