摘要:入门一件新事物总是会有些无从下手的,看了本文希望可以给大家一些帮助和了解。
机器学习算法,特别是神经网络被认为是新的AI革命的起因。在这篇文章中,我将介绍增强学习的概念,不过技术细节有限,只能使具有不同背景的读者能够理解该技术的本质、功能和局限性。
在本文末尾,我将提供一些实现RL的资源链接。
什么是增强学习?
从广义上讲,数据驱动算法可以分为三类:监督式、非监督式和增强学习。
前两个通常用于执行诸如图像分类、检测等任务,虽然它们的精确度是显著的,但这些任务不同于我们所期望的“智能”。
这就是增强学习的来源。这个概念本身是很简单的,就像我们的进化过程:环境给agent一个正确的东西给予奖励,并且对于错误的东西来惩罚它。主要的挑战是培养学习数百万种可能的做事方法的能力。
Q Learning和Deep Q Learning
Q Learning是一种应用广泛的增强学习算法。如果不进行详细的数学运算,给定的动作质量取决于agent处于什么状态。agent通常执行给予最大回报的操作。详细的数学可以在这里找到。
在这个算法中,agent根据环境给予多少回报来学习每个动作的质量(称为Q值或策略)。每个环境的状态值以及Q值通常存储在表中。当agent与环境交互时,Q值从随机值更新到实际上有助于最大化回报的值。
Deep Q Learning
Q Learning使用表的问题在于它不能很好地扩展。如果状态数太高,该表将不适合于内存。这就是Deep Q Learning可以应用的地方。深度学习基本上是一种通用的近似机器,它能理解抽象的表示。深度学习可以用来近似Q值,也可以通过梯度下降学习Q值。
有趣的事情:
谷歌在Deep Q Learning的某些元素上有专利权:
https://www.google.com/patents/US20150100530
探索vs开发
通常情况下,agent记录一条路径,永远不会尝试探索任何其他路径。 一般来说,我们希望一个agent不仅可以利用良好的路径,而且有时会探索可以执行操作的新路径。因此,一个名为ε的超参数用于指导探索新路径的多少和如何利用旧路径。
经验回放
在训练神经网络时,数据不平衡起着非常重要的作用。如果一个模型被训练,当agent与环境交互时,就会出现不平衡。
因此,所有状态以及相关数据都存储在内存中,神经网络可以随机选取一批交互和学习(这使得它与监督学习非常相似)。
训练框架
这就是Deep Q Learning的整体框架。 注意,这代表了打折的回报。这是一个超参数,可以控制未来回报的重量。符号’表示下一个。 例如 s'表示下一个状态。
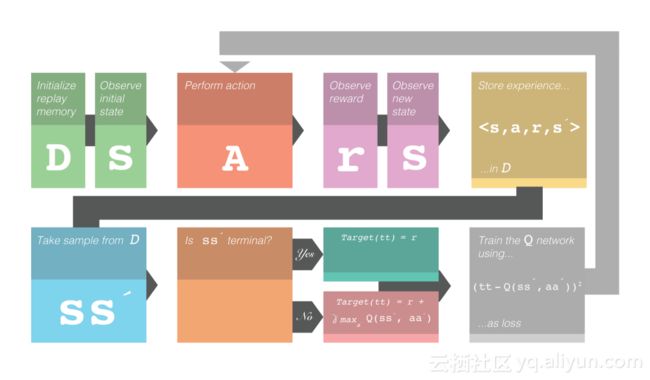
图1.Deep Q Learning训练框架。授权:Robert Aguilera
延伸的增强学习
增强学习能很好地处理许多事情(如AlphaGo),但是在反馈稀疏的地方通常会失败。agent不会长期探索实际有益的行为。 有时,为了自身的缘故(内在动机)而不是直接尝试解决问题,需要采取一些行动。
这样做可以让agent执行复杂的操作,基本上允许agent计划事情。分层学习允许这种抽象学习。
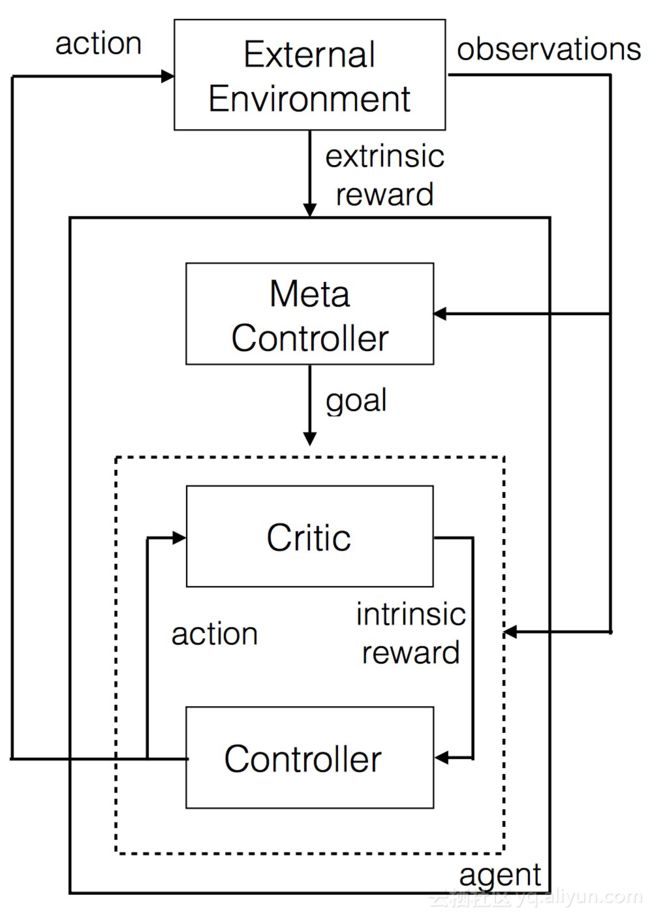
图2.分层Deep Q Learning
在这种设置中,有两个Q网络。它们被表示为控制器和元控制器。 元控制器查看原始状态并计算要遵循的“目标”。 控制器与目标一起进入状态,并输出策略来解决目标。critic检查是否达成目标,并向控制器给予回报。 当片段结束或达到目标时,控制器停止。 然后,元控制器选择一个新目标,并重复这个目标。
“目标”是最终帮助 agent获得最终回报的东西。这更好,因为它有可能Q Learning接着Q Learning以一个分层的方式。
增强学习的入门资源
下列对那些希望开始增强学习的人很有帮助:
1.Deep Q Learning基础。对理解强化学习的数学和过程很有帮助。
2.分层学习论文,对于那些想详细了解分层学习的人。
3.作者解说分层学习论文的视频。(需翻墙)
4.深度RL:概述。我认为是增强学习手册。它涵盖了理解当前研究水平所需要的RL的几乎每个方面。它深入探讨数学,而且还提供了高层次的概述。
5.用一个python脚本来实现深层次的学习。也许最简单的深层次的Q学习实现。这是很容易理解的,一个伟大的起点。

图3.在操作中的Deep Q Learning。第5点为Python脚本的输出
最后非常感谢Robert Aguilera制作了插图和流程图。
本文由北邮@爱可可-爱生活老师推荐,阿里云云栖社区组织翻译。
文章原标题《5 Ways to Get Started with Reinforcement Learning》
作者:Harshvardhan Gupta译者:TIAMO_ZN审阅:海棠
文章为简译,更为详细的内容,请查看原文附件为原文PDF