Spark:RDD操作和持久化
创建RDD
进行Spark核心编程时,首先要做的第一件事,就是创建一个初始的RDD。该RDD中,通常就代表和包含了Spark应用程序的输入源数据。然后在创建了初始的RDD之后,才可以通过Spark Core提供的transformation算子,对该RDD进行转换,来获取其他的RDD
Spark Core提供了三种创建RDD的方式
- 使用程序中的集合创建RDD
- 使用本地文件创建RDD
- 使用HDFS文件创建RDD
并行化集合创建RDD
如果要通过并行化集合来创建RDD,需要针对程序中的集合,调用SparkContext的parallelize()方法。Spark会将集合中的数据拷贝到集群上去,形成一个分布式的数据集合,也就是一个RDD。相当于是,集合中的部分数据会到一个节点上,而另一部分数据会到其他节点上。然后就可以用并行的方式来操作这个分布式数据集合,即RDD。
public class ParallelizeCollection {
public static void main(String[] args) {
// 创建SparkConf
SparkConf conf = new SparkConf().setAppName("ParallelizeCollection").setMaster("local");
// 创建JavaSparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
// 要通过并行化集合的方式创建RDD,那么就调用SparkContext以及其子类,的parallelize()方法
JavaRDD numberRDD = sc.parallelize(Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10));
// 执行reduce算子操作
// 相当于,先进行1 + 2 = 3;然后再用3 + 3 = 6;然后再用6 + 4 = 10。。。以此类推
int sum = numberRDD.reduce(new Function2() {
private static final long serialVersionUID = 1L;
@Override
public Integer call(Integer num1, Integer num2) throws Exception {
return num1 + num2;
}
});
// 输出累加的和
System.out.println("1到10的累加和:" + sum);
// 关闭JavaSparkContext
sc.close();
}
}
object ParallelizeCollection {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("ParallelizeCollection")
val sc = new SparkContext(conf)
val numberRDD = sc.parallelize(Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10), 5)
val sum = numberRDD.reduce(_ + _)
println(sum)
}
}
调用parallelize()时,有一个重要的参数可以指定,就是要将集合切分成多少个partition。Spark会为每一个partition运行一个task来进行处理。
Spark官方的建议是,为集群中的每个CPU创建2~4个partition。Spark默认会根据集群的情况来设置partition的数量。但是也可以在调用parallelize()方法时,传入第二个参数,来设置RDD的partition数量。
使用本地文件和HDFS创建RDD
Spark是支持使用任何Hadoop支持的存储系统上的文件创建RDD的,比如说HDFS、Cassandra、HBase以及本地文件。通过调用SparkContext的textFile()方法,可以针对本地文件或HDFS文件创建RDD。
注意事项:
- 如果是针对本地文件的话,如果是在windows上本地测试,windows上有一份文件即可;如果是在spark集群上针对linux本地文件,那么需要将文件拷贝到所有worker节点上。
- Spark的textFile()方法支持针对目录、压缩文件以及通配符进行RDD创建
- Spark默认会为hdfs文件的每一个block创建一个partition,但是也可以通过textFile()的第二个参数手动设置分区数量,只能比block数量多,不能比block数量少。
public class HDFSFile {
public static void main(String[] args) {
// 创建SparkConf
// 修改:去除setMaster()设置,修改setAppName()
SparkConf conf = new SparkConf().setAppName("HDFSFile");
// 创建JavaSparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
// 使用SparkContext以及其子类的textFile()方法,针对HDFS文件创建RDD
// 只要把textFile()内的路径修改为hdfs文件路径即可
JavaRDD lines = sc.textFile("hdfs://spark1:9000/spark.txt");
// 统计文本文件内的字数
JavaRDD lineLength = lines.map(new Function() {
private static final long serialVersionUID = 1L;
@Override
public Integer call(String v1) throws Exception {
return v1.length();
}
});
int count = lineLength.reduce(new Function2() {
private static final long serialVersionUID = 1L;
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
System.out.println("文件总字数是:" + count);
// 关闭JavaSparkContext
sc.close();
}
}
object LocalFile {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("LocalFile").setMaster("local")
val sc = new SparkContext(conf)
val lines = sc.textFile("spark.txt", 5)
val counts = lines.map(line => line.length()).reduce(_ + _)
println(counts)
}
}
Spark的textFile()除了可以针对上述几种普通的文件创建RDD之外,还有一些特列的方法来创建RDD:
- SparkContext.wholeTextFiles()方法
可以针对一个目录中的大量小文件,返回 - SparkContext.sequenceFileK, V方法
可以针对SequenceFile创建RDD,K和V泛型类型就是SequenceFile的key和value的类型。K和V要求必须是Hadoop的序列化类型,比如IntWritable、Text等。 - SparkContext.hadoopRDD()方法
对于Hadoop的自定义输入类型,可以创建RDD。该方法接收JobConf、InputFormatClass、Key和Value的Class。 - SparkContext.objectFile()方法
可以针对之前调用RDD.saveAsObjectFile()创建的对象序列化的文件,反序列化文件中的数据,并创建一个RDD。
操作RDD
Spark支持两种RDD操作:transformation和action。transformation操作会针对已有的RDD创建一个新的RDD;而action则主要是对RDD进行最后的操作,比如遍历、reduce、保存到文件等,并可以返回结果给Driver程序。
transformation的特点就是lazy特性。lazy特性指的是,如果一个spark应用中只定义了transformation操作,那么即使你执行该应用,这些操作也不会执行。也就是说,transformation是不会触发spark程序的执行的,它们只是记录了对RDD所做的操作,但是不会自发的执行。只有当transformation之后,接着执行了一个action操作,那么所有的transformation才会执行。Spark通过这种lazy特性,来进行底层的spark应用执行的优化,避免产生过多中间结果。
action操作执行,会触发一个spark job的运行,从而触发这个action之前所有的transformation的执行。这是action的特性。

常用transformation介绍
| 操作 | 介绍 |
|---|---|
| map | 将RDD中的每个元素传入自定义函数,获取一个新的元素,然后用新的元素组成新的RDD |
| filter | 对RDD中每个元素进行判断,如果返回true则保留,返回false则剔除。 |
| flatMap | 与map类似,但是对每个元素都可以返回一个或多个新元素。 |
| gropuByKey | 根据key进行分组,每个key对应一个Iterable |
| reduceByKey | 对每个key对应的value进行reduce操作。 |
| sortByKey | 对每个key对应的value进行排序操作。 |
| join | 对两个包含 |
| cogroup | 同join,但是是每个key对应的Iterable都会传入自定义函数进行处理。 |
常用action介绍
| 操作 | 介绍 |
|---|---|
| reduce | 将RDD中的所有元素进行聚合操作。第一个和第二个元素聚合,值与第三个元素聚合,值与第四个元素聚合,以此类推。 |
| collect | 将RDD中所有元素获取到本地客户端。 |
| count | 获取RDD元素总数。 |
| take(n) | 获取RDD中前n个元素。 |
| saveAsTextFile | 将RDD元素保存到文件中,对每个元素调用toString方法 |
| countByKey | 对每个key对应的值进行count计数。 |
| foreach | 遍历RDD中的每个元素。 |
transformation操作
map
map算子,是对任何类型的RDD,都可以调用的,java中,map算子接收的参数是Function对象,创建的Function对象,一定会让你设置第二个泛型参数,这个泛型类型,就是返回的新元素的类型,同时call()方法的返回类型,也必须与第二个泛型类型同步,在call()方法内部,就可以对原始RDD中的每一个元素进行各种处理和计算,并返回一个新的元素,新的元素就会组成一个新的RDD
JavaRDD multipleNumberRDD = numberRDD.map(new Function() {
private static final long serialVersionUID = 1L;
// 传入call()方法的,就是1,2,3,4,5
// 返回的就是2,4,6,8,10
@Override
public Integer call(Integer v1) throws Exception {
return v1 * 2;
}
});
val multipleNumberRDD = numberRDD.map { num => num * 2 }
filter
filter算子,传入的也是Function,其他的使用注意点,实际上和map是一样的,但是,唯一的不同,就是call()方法的返回类型是Boolean,每一个初始RDD中的元素,都会传入call()方法,此时你可以执行各种自定义的计算逻辑来判断这个元素是否是你想要的,如果你想在新的RDD中保留这个元素,那么就返回true;否则,不想保留这个元素,返回false
JavaRDD evenNumberRDD = numberRDD.filter(new Function() {
private static final long serialVersionUID = 1L;
// 在这里,1到10,都会传入进来
// 但是根据我们的逻辑,只有2,4,6,8,10这几个偶数,会返回true
// 所以,只有偶数会保留下来,放在新的RDD中
@Override
public Boolean call(Integer v1) throws Exception {
return v1 % 2 == 0;
}
});
val evenNumberRDD = numberRDD.filter { num => num % 2 == 0 }
flatMap
flatMap算子,在java中,接收的参数是FlatMapFunction,需要自己定义FlatMapFunction的第二个泛型类型,即,代表了返回的新元素的类型,call()方法,返回的类型不是U,而是Iterable<>,这里的U也与第二个泛型类型相同,flatMap其实就是,接收原始RDD中的每个元素,并进行各种逻辑的计算和处理,可以返回多个元素,即封装在Iterable集合中,可以使用ArrayList等集合,新的RDD中,即封装了所有的新元素;也就是说,新的RDD的大小一定是 >= 原始RDD的大小
JavaRDD words = lines.flatMap(new FlatMapFunction() {
private static final long serialVersionUID = 1L;
// 在这里会,比如,传入第一行,hello you
// 返回的是一个Iterable(hello, you)
@Override
public Iterable call(String t) throws Exception {
return Arrays.asList(t.split(" "));
}
});
val words = lines.flatMap { line => line.split(" ") }
gropuByKey
groupByKey算子,返回的JavaPairRDD,JavaPairRDD的第一个泛型类型不变,第二个泛型类型变成Iterable这种集合类型,也就是说,按照了key进行分组,那么每个key可能都会有多个value,此时多个value聚合成了Iterable
// 模拟集合
List> scoreList = Arrays.asList(
new Tuple2("class1", 80),
new Tuple2("class2", 75),
new Tuple2("class1", 90),
new Tuple2("class2", 65));
JavaPairRDD scores = sc.parallelizePairs(scoreList);
JavaPairRDD> groupedScores = scores.groupByKey();
val scoreList = Array(Tuple2("class1", 80), Tuple2("class2", 75),Tuple2("class1", 90), Tuple2("class2", 60))
val scores = sc.parallelize(scoreList, 1)
val groupedScores = scores.groupByKey()
reduceByKey
reduceByKey,接收的参数是Function2类型,它有三个泛型参数,实际上代表了三个值,第一个泛型类型和第二个泛型类型,代表了原始RDD中的元素的value的类型,因此对每个key进行reduce,都会依次将第一个、第二个value传入,将值再与第三个value传入,因此此处,会自动定义两个泛型类型,代表call()方法的两个传入参数的类型。第三个泛型类型,代表了每次reduce操作返回的值的类型,默认也是与原始RDD的value类型相同的。
JavaPairRDD totalScores = scores.reduceByKey(new Function2() {
private static final long serialVersionUID = 1L;
// 对每个key,都会将其value,依次传入call方法
// 从而聚合出每个key对应的一个value
// 然后,将每个key对应的一个value,组合成一个Tuple2,作为新RDD的元素
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
val totalScores = scores.reduceByKey(_ + _)
sortByKey
sortByKey其实就是根据key进行排序,可以手动指定升序,或者降序。
JavaPairRDD sortedScores = scores.sortByKey(false);
val sortedScores = scores.sortByKey(false)
join
join,会根据key进行join并返回JavaPairRDD,JavaPairRDD的第一个泛型类型是之前两个JavaPairRDD的key的类型,因为是通过key进行join的,第二个泛型类型,是Tuple2
例:两个RDD
- RDD1 (1, 1) (1, 2) (1, 3)
- RDD2 (1, 4) (2, 1) (2, 2)
join 结果: (1 (1, 4)) (1, (2, 4)) (1, (3, 4))
// 模拟集合
List> studentList = Arrays.asList(
new Tuple2(1, "leo"),
new Tuple2(2, "jack"),
new Tuple2(3, "tom"));
List> scoreList = Arrays.asList(
new Tuple2(1, 100),
new Tuple2(2, 90),
new Tuple2(3, 60));
// 并行化两个RDD
JavaPairRDD students = sc.parallelizePairs(studentList);
JavaPairRDD scores = sc.parallelizePairs(scoreList);
JavaPairRDD> studentScores = students.join(scores);
val studentScores = students.join(scores)
cogroup
相当于是,一个key join上的所有value,都给放到一个Iterable里面去了
List> studentList = Arrays.asList(
new Tuple2(1, "leo"),
new Tuple2(2, "jack"),
new Tuple2(3, "tom"));
List> scoreList = Arrays.asList(
new Tuple2(1, 100),
new Tuple2(2, 90),
new Tuple2(3, 60),
new Tuple2(1, 70),
new Tuple2(2, 80),
new Tuple2(3, 50));
// 并行化两个RDD
JavaPairRDD students = sc.parallelizePairs(studentList);
JavaPairRDD scores = sc.parallelizePairs(scoreList);
JavaPairRDD, Iterable>> studentScores = students.cogroup(scores)
val studentScores = students.cogroup(scores)
action操作
reduce
reduce操作对集合中的数字进行累加,就是聚合,将多个元素聚合成一个元素
原理:
首先将第一个和第二个元素,传入call()方法,进行计算,会获取一个结果,比如1 + 2 = 3
接着将该结果与下一个元素传入call()方法,进行计算,比如3 + 3 = 6
以此类推
int sum = numbers.reduce(new Function2() {
private static final long serialVersionUID = 1L;
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
val sum = numbers.reduce(_ + _)
collect
collect,将分布在远程集群上的结果RDD的数据拉取到本地,一般不建议使用,因为如果rdd中的数据量比较大的话,性能会比较差,从远程走大量的网络传输,将数据获取到本地,在rdd中数据量特别大的情况下,发生oom异常,内存溢出。
List doubleNumberList = doubleNumbers.collect();
for (Integer num : doubleNumberList) {
System.out.println(num);
}
val doubleNumberList = numbers.map(number => number * 2).collect()
for (num <- doubleNumberList) {
println(num)
}
count
对rdd使用count操作,统计它有多少个元素
List numberList = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
JavaRDD numbers = sc.parallelize(numberList);
long count = numbers.count();
System.out.println(count);
val count = numbers.count()
take
take操作,与collect类似,也是从远程集群上,获取rdd的数据,collect是获取rdd的所有数据,take只是获取前n个数据
List top3Numbers = numbers.take(3);
for (Integer num : top3Numbers) {
System.out.println(num);
}
val top3Numbers = numbers.take(3)
saveAsTextFile
直接将rdd中的数据,保存在HFDS文件中,注意,我们这里只能指定文件夹,也就是目录
List numberList = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
JavaRDD numbers = sc.parallelize(numberList);
// 使用map操作将集合中所有数字乘以2
JavaRDD doubleNumbers = numbers.map(new Function() {
private static final long serialVersionUID = 1L;
@Override
public Integer call(Integer v1) throws Exception {
return v1 * 2;
}
});
// 保存为目录中的/double_number/part-00000文件
doubleNumbers.saveAsTextFile("hdfs://spark1:9000/double_number");
val doubleNumbers = numbers.map(number => number * 2)
doubleNumbers.saveAsTextFile("hdfs://spark1:9000/double_number.txt")
countByKey
统计每个key对应的元素个数,countByKey返回的类型,直接就是Map
List> scoreList = Arrays.asList(
new Tuple2("class1", "leo"),
new Tuple2("class2", "jack"),
new Tuple2("class1", "marry"),
new Tuple2("class2", "tom"),
new Tuple2("class2", "david"));
JavaPairRDD students = sc.parallelizePairs(scoreList);
Map studentCounts = students.countByKey();
val studentCounts = students.countByKey()
RDD持久化
不使用RDD持久话会出现什么呢?

Spark最重要的一个功能,就是在不同操作间,持久化(或缓存)一个数据集在内存中。当你持久化一个RDD,每一个结点都将把它的计算分块结果保存在内存中,并在对此数据集(或者衍生出的数据集)进行的其它动作中重用。这将使得后续的动作(action)变得更加迅速(通常快10倍)。缓存是用Spark构建迭代算法的关键。RDD的缓存能够在第一次计算完成后,将计算结果保存到内存、本地文件系统或者Tachyon(分布式内存文件系统)中。通过缓存,Spark避免了RDD上的重复计算,能够极大地提升计算速度。

如何持久化
要持久化一个RDD,只要调用其cache()或者persist()方法即可。在该RDD第一次被计算出来时,就会直接缓存在每个节点中。而且Spark的持久化机制还是自动容错的,如果持久化的RDD的任何partition丢失了,那么Spark会自动通过其源RDD,使用transformation操作重新计算该partition。实际上cache()是使用persist(MEMORY_ONLY)的快捷方法。如果需要从内存中清楚缓存,那么可以使用unpersist()方法。
Spark自己也会在shuffle操作时,进行数据的持久化,比如写入磁盘,主要是为了在节点失败时,避免需要重新计算整个过程。
SparkConf conf = new SparkConf().setAppName("Persist").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
// cache()或者persist()的使用,是有规则的
// 必须在transformation或者textFile等创建了一个RDD之后,直接连续调用cache()或persist()才可以
// 如果你先创建一个RDD,然后单独另起一行执行cache()或persist()方法,是没有用的
// 而且,会报错,大量的文件会丢失
JavaRDD lines = sc.textFile("spark.txt").cache();
RDD持久化策略
RDD持久化是可以手动选择不同的策略的。比如可以将RDD持久化在内存中、持久化到磁盘上、使用序列化的方式持久化,多持久化的数据进行多路复用。只要在调用persist()时传入对应的StorageLevel即可。
cache()方法使用了默认的存储级别—StorageLevel.MEMORY_ONLY
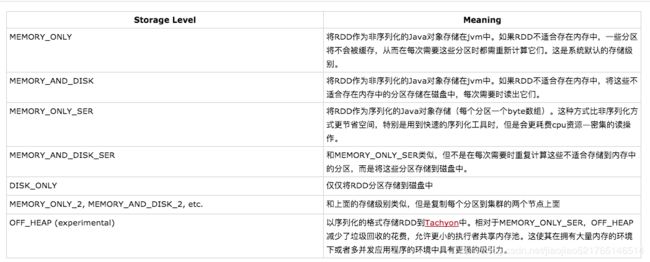
存储级别的选择
Spark的多个存储级别意味着在内存利用率和cpu利用效率间的不同权衡。推荐通过下面的过程选择一个合适的存储级别:
- 优先使用MEMORY_ONLY,如果可以缓存所有数据的话,那么就使用这种策略。因为纯内存速度最快,而且没有序列化,不需要消耗CPU进行反序列化操作。
- 如果MEMORY_ONLY策略,无法存储的下所有数据的话,那么使用MEMORY_ONLY_SER,将数据进行序列化进行存储,纯内存操作还是非常快,只是要消耗CPU进行反序列化
- 如果需要进行快速的失败恢复,那么就选择带后缀为_2的策略,进行数据的备份,这样在失败时,就不需要重新计算了。
- 能不使用DISK相关的策略,就不用使用,有的时候,从磁盘读取数据,还不如重新计算一次。

注意只能设置一种:不然会抛异常: Cannot change storage level of an RDD after it was already assigned a level
如何使用缓存
//内存
JavaRDD lines = sc.textFile("spark.txt").persist(StorageLevel.MEMORY_ONLY());

//磁盘存储
JavaRDD lines = sc.textFile("spark.txt").persist(StorageLevel.DISK_ONLY())

清除缓存
lines.unpersist();
