聚类之K-Means++算法
文章目录
- 前言
- 1. K-Means算法的不足之二
- 2. K-Means++算法
- 3. 代码实现
- 4. sklearn实现K-Means++
- 结束语
前言
K-Means算法的原理很简单:初始化 k k k个聚类中心之后,不断计算样本与 k k k个聚类中心的距离,离哪个聚类中心最近,相应的该样本就属于这个聚类中心所属的类别,然后重新计算聚类中心,直至其不再发生变化,具体步骤请参阅我的上篇博客。
当然,此算法也有一定的局限和不足之处,想必其中一点已经很清楚了,那就是需要首先确定聚类中心的个数 k k k,即需要先验知识。如果有一大批数据,我事先不知道其有几个类别,那 k k k的大小该如何确定呢?这个问题我想放在下篇博客分享。
本篇博客主要分享一下如何解决K-Means的另一个不足之处:聚类中心的初始化
1. K-Means算法的不足之二
K-Means在初始化聚类中心时是在最小值和最大值之间随机取一个值作为其聚类中心,这样的随机取值会导致聚类中心可能选择的不好,最终对结果会产生很大的影响。经过测试,如果样本类别区分度较明显,按照K-Means初始化聚类中心,对结果的影响并不大;反之,如果样本的类别区分度不大,聚类结果会有较大的不同。下面用周志华老师的《机器学习》这本书里的西瓜数据集来说明。
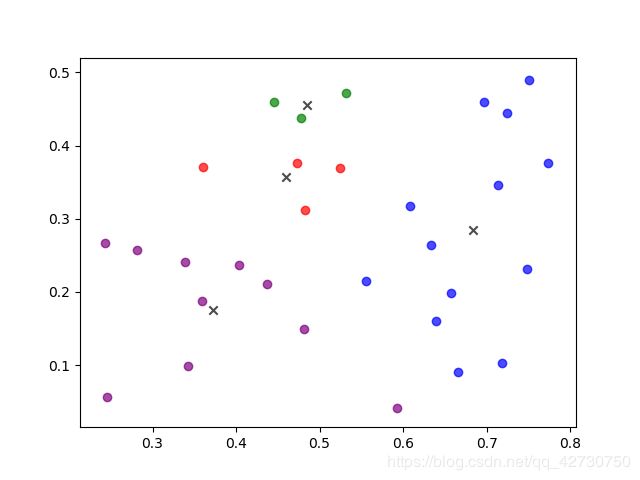
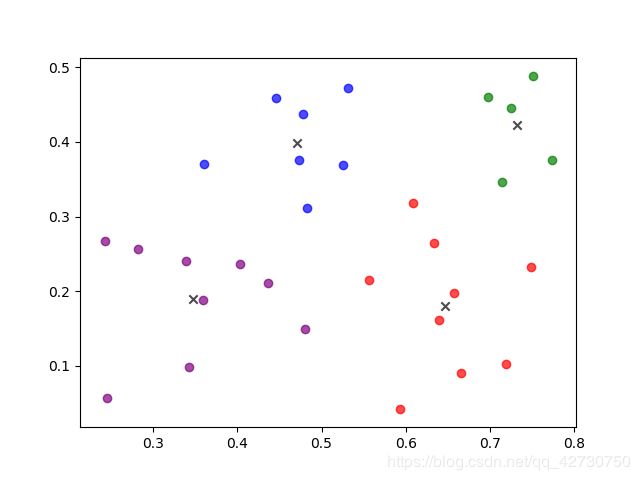
上述两张图可以说明,对于同一数据集,不同的初始聚类中心其产生的结果会有较大的不同。因此,K-Means++算法被提出了。
2. K-Means++算法
K-Means++算法是K-Means算法的改进版,主要是为了选择出更优的初始聚类中心。其基本思路如下:
- 在数据集中随机选择一个样本作为第一个初始聚类中心;
- 选择出其余的聚类中心:
- 计算数据集中的每一个样本与已经初始化的聚类中心之间的距离,并选择其中最短的距离,记为 d i d_i di;
- 以概率选择距离最大的样本作为新的聚类中心,重复上述过程,直到 k k k个聚类中心都被确定。
- 对 k k k个初始的聚类中心,利用K-Means算法计算出最终的聚类中心。
对“以概率选择距离最大的样本作为新的聚类中心”的理解:
即初始的聚类中心之间的相互距离应尽可能的远。假如有 3 、 5 、 15 、 10 、 2 3、5、15、10、2 3、5、15、10、2这五个样本的最小距离 d i d_i di,则其和 s u m sum sum为 35 35 35,然后乘以一个取值在 [ 0 , 1 ) [0, 1) [0,1)范围的值,即概率,也可以称其为权重,然后这个结果不断减去样本的距离 d i d_i di,直到某一个距离使其小于等于0,这个距离对应的样本就是新的聚类中心。比如上述的例子,假设 s u m sum sum乘以 0.5 0.5 0.5得到结果 17.5 17.5 17.5, 17.5 − 3 = 14.5 > 0 , 14.5 − 5 = 9.5 > 0 , 9.5 − 15 = − 5.5 < 0 17.5-3=14.5>0,14.5-5=9.5>0,9.5-15=-5.5<0 17.5−3=14.5>0,14.5−5=9.5>0,9.5−15=−5.5<0,则距离 d i d_i di为15的样本点距离最大,做为新的的聚类中心。
3. 代码实现
代码和上篇博客里里面的代码基本一致,不同之处就是更换了初始化聚类中心的函数。
import numpy as np
import random
import matplotlib.pyplot as plt
def load_data(file_path):
"""
将txt里面的数据转换成矩阵
:param file_path:
:return:
"""
data_list = []
with open(file_path, 'r') as f:
lines = f.readlines()
for line in lines:
data_row = []
line = line.strip().split('\t')
for x in line:
data_row.append(float(x))
data_list.append(data_row)
data_arr = np.array(data_list)
return data_arr
def o2_distance(vecA, vecB):
"""
计算向量vecA和向量vecB之间的欧氏距离的平方
:param vecA: 向量vecA的坐标
:param vecB: 向量vecB的坐标
:return:
"""
# .T 对一个矩阵转置
distance = np.dot((vecA - vecB), (vecA - vecB).T)
return distance
def nearest_distance(data_arr, cluster_centers):
min_distance = 100
# 当前已经初始化的聚类中心之间的距离
dim = np.shape(cluster_centers)[0]
for i in range(dim):
# 计算point与每个聚类中心之间的距离
distance = o2_distance(data_arr, cluster_centers[i])
# 选择最短距离
if distance < min_distance:
min_distance = distance
return min_distance
def get_centroids(data_arr, k):
dim_m, dim_n = np.shape(data_arr)
cluster_centers = np.array(np.zeros(shape=(k, dim_n)))
# 随机选择一个样本点为第一个聚类中心
index = np.random.randint(0, dim_m)
cluster_centers[0] = data_arr[index]
# 初始化一个距离的序列
distance = [0.0 for _ in range(dim_m)]
for i in range(1, k):
sum_all = 0
for j in range(dim_m):
# 对每一个样本找到最近的聚类中心点
distance[j] = nearest_distance(data_arr[j], cluster_centers[0:i])
# 将所有的最短距离相加
sum_all += distance[j]
# 取得sum_all之间的随机值
sum_all *= random.random()
# 以概率获得距离最远的样本点作为聚类中心
for id, dist in enumerate(distance):
sum_all -= dist
if sum_all > 0:
continue
cluster_centers[i] = data_arr[id]
break
return cluster_centers
def kmeans(data_arr, k, centroids):
"""
聚类计算
:param data_arr:
:param k:
:param centroids:
:return: sub_centroids [类别, 最小距离]
"""
# (样本个数, 特征维度)
dim_m, dim_n = np.shape(data_arr)
# 初始化每一个样本所属的类别
sub_center = np.array(np.zeros(shape=(dim_m, 2)))
# 更新标志
flag = True
while flag:
flag = False
for i in range(dim_m):
# 设置样本与聚类中心之间的初始最小距离, 初始值为无穷
min_distance = np.inf
# 设置所属的初始类别
min_index = 0
for j in range(k):
# 计算样本i和每个聚类中心之间的距离
distance = o2_distance(data_arr[i], centroids[j])
if distance < min_distance:
min_distance = distance
min_index = j
if sub_center[i, 0] != min_index:
flag = True
sub_center[i] = np.array([min_index, min_distance])
# 重新计算聚类中心
for j in range(k):
sum_all = np.array(np.zeros(shape=(1, dim_n)))
# 每个类别中的样本个数
counter = 0
for i in range(dim_m):
# 计算第j个类别
if sub_center[i, 0] == j:
sum_all += data_arr[i]
counter += 1
for t in range(dim_n):
try:
centroids[j, t] = sum_all[0, t] / counter
except Exception as err:
print('样本数为0')
return sub_center
def draw_picture(data_arr, sub_center, centroids):
x = sub_center[:, 0]
dots1 = data_arr[x == 0.0]
dots2 = data_arr[x == 1.0]
dots3 = data_arr[x == 2.0]
dots4 = data_arr[x == 3.0]
plt.figure()
plt.scatter(dots1[:, 0], dots1[:, 1], marker='o',
color='blue', alpha=0.7, label='dots1 samples')
plt.scatter(dots2[:, 0], dots2[:, 1], marker='o',
color='green', alpha=0.7, label='dots2 samples')
plt.scatter(dots3[:, 0], dots3[:, 1], marker='o',
color='red', alpha=0.7, label='dots3 samples')
plt.scatter(dots4[:, 0], dots4[:, 1], marker='o',
color='purple', alpha=0.7, label='dots4 samples')
plt.scatter(centroids[:, 0], centroids[:, 1], marker='x',
color='black', alpha=0.7, label='centroids')
plt.savefig('./result_plus.png')
plt.show()
if __name__ == '__main__':
k = 4
file_path = './西瓜数据集.txt'
data_arr = load_data(file_path)
centroids = get_centroids(data_arr, k)
sub_center = kmeans(data_arr, k, centroids)
draw_picture(data_arr, sub_center, centroids)
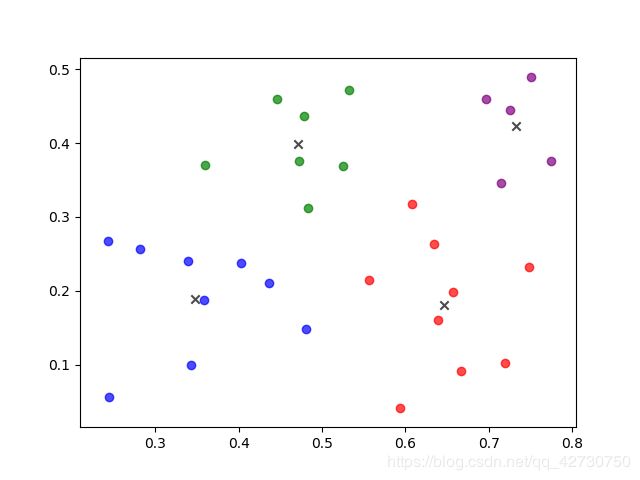
运行结果如图所示:
4. sklearn实现K-Means++
本代码主要使用sklearn.cluster.KMeans,部分参数已注释,更详细的说明,请参考官方文档。
from sklearn.cluster import KMeans
import numpy as np
import matplotlib.pyplot as plt
def load_data(file_path):
"""
将txt里面的数据转换成矩阵
:param file_path:
:return:
"""
data_list = []
with open(file_path, 'r') as f:
lines = f.readlines()
for line in lines:
data_row = []
line = line.strip().split('\t')
for x in line:
data_row.append(float(x))
data_list.append(data_row)
data_arr = np.array(data_list)
return data_arr
def draw_picture(data_arr, cluster_centers, labels):
dots1 = data_arr[labels == 0]
dots2 = data_arr[labels == 1]
dots3 = data_arr[labels == 2]
dots4 = data_arr[labels == 3]
plt.figure()
plt.scatter(dots1[:, 0], dots1[:, 1], marker='o',
color='blue', alpha=0.7, label='dots1 samples')
plt.scatter(dots2[:, 0], dots2[:, 1], marker='o',
color='green', alpha=0.7, label='dots2 samples')
plt.scatter(dots3[:, 0], dots3[:, 1], marker='o',
color='red', alpha=0.7, label='dots3 samples')
plt.scatter(dots4[:, 0], dots4[:, 1], marker='o',
color='purple', alpha=0.7, label='dots4 samples')
plt.scatter(cluster_centers[:, 0], cluster_centers[:, 1], marker='x',
color='black', alpha=0.7, label='centroids')
plt.savefig('./result_plus_skl.png')
plt.show()
if __name__ == '__main__':
file_path = './西瓜数据集.txt'
data_arr = load_data(file_path)
# n_clusters 聚类中心数目k, 默认为8
# init 聚类中心的初始化方法, 默认为k-means++
# n_init 算法执行的次数, 默认为10
# max_iter 最大迭代次数, 默认300
# tol 算法收敛的阈值, 默认0.0001
# verbose 0不打印日志, 1打印日志
# random_state 随机数生成器的种子
# n_jobs 任务使用的CPU数量
kmeans = KMeans(n_clusters=4, init='k-means++', n_init=10, max_iter=300,
tol=1e4, verbose=0, random_state=1024, n_jobs=1)
kmeans.fit(X=data_arr)
# 聚类中心
cluster_centers = kmeans.cluster_centers_
# 各个样本的类别
labels = kmeans.labels_
draw_picture(data_arr, cluster_centers, labels)
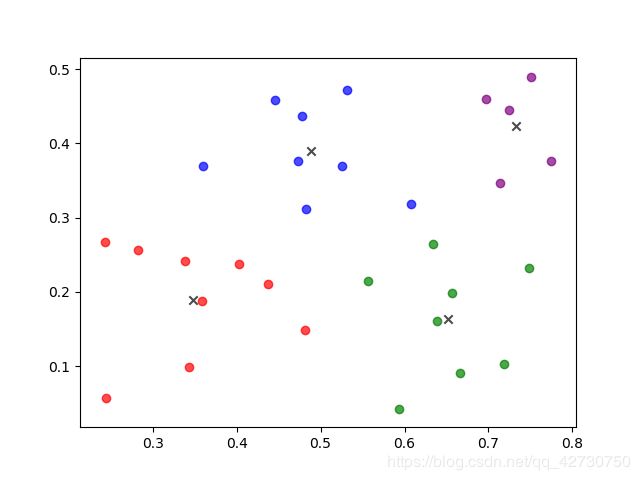
运行结果如图所示:
结束语
本篇博客主要分享了K-Means++算法的原理及两种代码实现,能力有限,如有错误的地方,欢迎交流哦,O(∩_∩)O哈哈~