Spark中RDD、DataFrame和DataSet的区别 ?
今天的三个问题是:
1.Spark1.0和2.0有什么区别?(真心不想重装2.0,但是没有办法啊)
2.Spark RDD、DataFrame和DataSet的区别 ?(往期第33题写过一次,但没有解释清楚)
3.如何选择RDD还是DataFrame/DataSet?
话不多说,直接上干货,最后附上了原文参考文献,觉得有翻译不到位的地方可以看看原文,欢迎各位指出更正。
首先,Spark RDD、DataFrame和DataSet是Spark的三类API,下图是他们的发展过程:

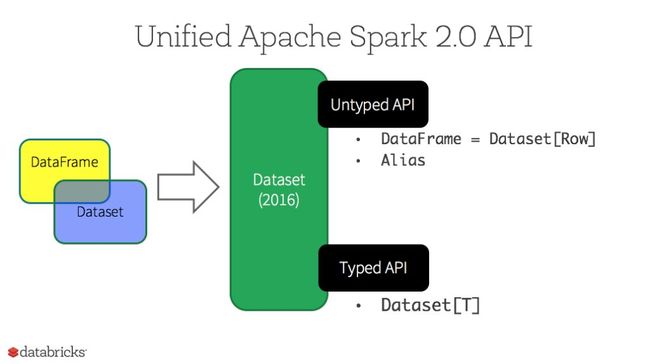
DataFrame是spark1.3.0版本提出来的,spark1.6.0版本又引入了DateSet的,但是在spark2.0版本中,DataFrame和DataSet合并为DataSet。
那么你可能会问了:那么,在2.0以后的版本里,RDDs是不是不需要了呢?
答案是:NO!首先,DataFrame和DataSet是基于RDDs的,而且这三者之间可以通过简单的API调用进行无缝切换。
下面,依次介绍这三类API的特点
一、RDD
RDD的优点:
1.相比于传统的MapReduce框架,Spark在RDD中内置很多函数操作,group,map,filter等,方便处理结构化或非结构化数据。
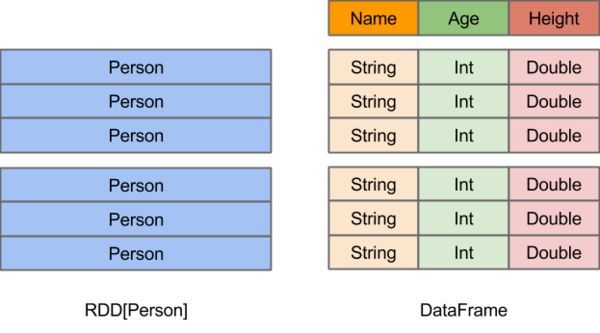
2.面向对象编程,直接存储的java对象,类型转化也安全
RDD的缺点:
1.由于它基本和hadoop一样万能的,因此没有针对特殊场景的优化,比如对于结构化数据处理相对于sql来比非常麻烦
2.默认采用的是java序列号方式,序列化结果比较大,而且数据存储在java堆内存中,导致gc比较频繁
二、DataFrame
DataFrame的优点:
1.结构化数据处理非常方便,支持Avro, CSV, elastic search, and Cassandra等kv数据,也支持HIVE tables, MySQL等传统数据表
 2.有针对性的优化,如采用Kryo序列化,由于数据结构元信息spark已经保存,序列化时不需要带上元信息,大大的减少了序列化大小,而且数据保存在堆外内存中,减少了gc次数,所以运行更快。
2.有针对性的优化,如采用Kryo序列化,由于数据结构元信息spark已经保存,序列化时不需要带上元信息,大大的减少了序列化大小,而且数据保存在堆外内存中,减少了gc次数,所以运行更快。

3.hive兼容,支持hql、udf等
DataFrame的缺点:
1.编译时不能类型转化安全检查,运行时才能确定是否有问题
2.对于对象支持不友好,rdd内部数据直接以java对象存储,dataframe内存存储的是row对象而不能是自定义对象
三、DateSet
DateSet的优点:
1.DateSet整合了RDD和DataFrame的优点,支持结构化和非结构化数据
2.和RDD一样,支持自定义对象存储
3.和DataFrame一样,支持结构化数据的sql查询
4.采用堆外内存存储,gc友好
5.类型转化安全,代码友好
四、new DateSet
自Spark2.0之后,DataFrame和DataSet合并为更高级的DataSet,新的DataSet具有两个不同的API特性:1.非强类型(untyped),DataSet[Row]是泛型对象的集合,它的别名是DataFrame;2.强类型(strongly-typed),DataSet[T]是具体对象的集合,如scala和java中定义的类

注: 因为Python和R没有编译阶段,所以只有无类型的API,即DataFrame。
1.静态类型和运行时类型安全
例如,在用Spark SQL进行查询时,直到运行时才会发现(syntax error)语法错误(这样成本太高),而采用DataFrame和DataSet时,可以在编译时就可以发现错误(从而节省开发时间和成本)。换句话说,如果你在DataFrame中调用的一个函数不是API的一部分,编译器会捕获这个错误。但是,对于一个不存在的列名,在编译期是检测不出来的。
由于DataSet都表示为lambda匿名函数和JVM类型对象,所以编译时会检测到类型参数的任何不匹配。另外,在使用DataSet时,也可以在编译时检测到分析错误,从而节省开发人员的时间和成本。
2.结构化和半结构化数据的高级抽象和自定义视图
DataFrames作为一个行式数据集的集合,可以将半结构化的数据以结构化的视图呈现出来。例如,您有一个海量的物联网设备数据集,以JSON表示。由于JSON是一种半结构化的格式,可以通过DataSet[DeviceIoTData]将强类型数据表达出来。
JSON串:{"device_id": 198164, "device_name": "sensor-pad-198164owomcJZ", "ip": "80.55.20.25", "cca2": "PL", "cca3": "POL", "cn": "Poland", "latitude": 53.080000, "longitude": 18.620000, "scale": "Celsius", "temp": 21, "humidity": 65, "battery_level": 8, "c02_level": 1408, "lcd": "red", "timestamp" :1458081226051}
可以通过Scala定义一个类-DeviceIoTData:
case class DeviceIoTData (battery_level: Long, c02_level: Long, cca2: String, cca3: String, cn: String, device_id: Long, device_name: String, humidity: Long, ip: String, latitude: Double, lcd: String, longitude: Double, scale:String, temp: Long, timestamp: Long)
这样,我们就可以从JSON文件中读取数据了:
// read the json file and create the dataset from the case class DeviceIoTData
// ds is now a collection of JVM Scala objects DeviceIoTData
val ds = spark.read.json(“/databricks-public-datasets/data/iot/iot_devices.json”).as[DeviceIoTData]
上述代码,经历了三段过程:
1.Spark读取了JSON文件,并根据定义的结构,创建了一个DataFrame的数据集
2.在这个DataFrame的数据集,即Dataset[Row]中,实际是一个个的行对象,因为它并不知道各自的类型
3.最后,spark将Dataset[Row]转换为Dataset[DeviceIoTData],每一行数据被转化为了一个个的实例对象
3.API结构的易用性
虽然结构化会限制Spark对数据的操作,但是DataSet引入了丰富的API来对高结构化的数据进行控制,例如,在进行agg, select, sum, avg, map, filter, 或者groupBy操作时,DataSet比RDD更简单。
// This operation results in another immutable Dataset. The query is simpler to //read,andexpressive
val dsAvgTmp = ds.filter(d => {d.temp > 25}).map(d => (d.temp, d.humidity, d.cca3)).groupBy($"_3").avg()
//display the resulting dataset
display(dsAvgTmp)
4.性能和优化
因为DataFrame和DataSet的API是建立在Spark SQL引擎之上的,无论是java、scala还是python,所有涉及到关系型查询的语句,都会经历相同的逻辑优化和执行计划。不同的是, Dataset[T]类的API更适合数据工程任务,Dataset[Row](即DataFrame)类的API则更适合交互式分析。而且,spark作为一种编译器可以理解DataSet中的JVM对象,可以通过Tungsten编码,将这些对象进行快速的序列化和反序列化。

五、我们应该什么时候使用DataFrame或DataSet呢?
1.如果你想要丰富的语义、高层次的抽象,和特定情景的API,使用DataFrame或DataSet。
2.如果你的处理要求涉及到filters, maps, aggregation, averages, sum, SQL queries, columnar access或其他lambda匿名函数,使用DataFrame或DataSet。
3.如果希望在编译时获得更高的类型安全性,需要类型化的JVM对象,利用Tungsten编码进行高效的序列化、反序列化,使用DataSet。
4.如果你想统一和简化spark的API,使用DataFrame或DataSet。
5.如果你是一个R用户,使用DataFrame。
6.如果你是一个Python用户,使用DataFrame,如果你需要更多的控制功能,尽量回到RDD。
注意:如果想从DataFrame或DataSet回到RDD,记得调用.rdd这个方法,如:
// select specific fields from the Dataset, apply a predicate using the where() method,
// convert to an RDD, and show first 10 RDD rows
val deviceEventsDS = ds.select($"device_name", $"cca3", $"c02_level").where($"c02_level" > 1300)
// convert to RDDs and take the first 10 rows
val eventsRDD = deviceEventsDS.rdd.take(10)
六、如何选择RDD还是DataFrame/DataSet?
前者提供低级别的功能和更多的控制,后者允许自定义视图和结构,提供高级和特定领域的操作,节省空间,并能够以极高的速度执行。
参考资料:
1.https://www.zhihu.com/question/48684460
2.https://databricks.com/blog/2016/07/14/a-tale-of-three-apache-spark-apis-rdds-dataframes-and-datasets.html
以上.
听说,爱点赞的人运气都不会太差哦
如果有任何意见和建议,也欢迎在下方留言~
关注这个公众号,定期会有大数据学习的干货推送给你哦~

点击这里查看往期精彩内容:
每日三问(0105)
每日三问(0106)
每日三问(0107)