JDK1.8源码解析之ConcurrentHashMap
ConcurrentHashMap源码解析
- 概述
- 全局变量
- put方法
- initTable
- putAll
- addCount
- helpTransfer
- transfer
- size
概述
jdk1.8的concurrentHashMap废弃了1.7的segment,1.8使用table数组+Node+synchroinized+红黑树+treeNode实现,并发性能更好,尤其是在扩容方面,支持多线程并发扩容。
全局变量
private transient volatile int sizeCtl;
sizeCtl是通过值得大小表示不同含义,可以叫做大小控制变量。
| sizeCtl | purpose |
|---|---|
| -1 | table正在初始化 |
| <-1 | 正在忙于扩容的线程的数量的负数(ConcurrentHashMap支持并发扩容,所以提高了扩容的效率) |
| 0 | 此时table为空,0是默认值 |
| >0 | 下一次扩容的大小 |
private static final long SIZECTL;// sizeCtl偏移量,用来快速寻找到sizeCtl的大小
put方法
首先关注一下hash桶索引的计算,这里通过两层的计算得到一个hash,使用两层应该是为了减少hash碰撞几率的产生,来看一下如何计算的。
static final int spread(int h) {
return (h ^ (h >>> 16)) & HASH_BITS;
}
h>>>16 的意思是h不带符号向右移动16位,也就是说h的二进制数据的高16都是0,而int类型总长度是32位,^在java中是位异或运算符,两个二进制数表示的整数,从高位异或计算,对应的两位相同则结果为0,不同为1,了解了以上的计算规则,h ^ (h >>> 16) 其实它的思想就是h的高16位不变,后16位的结果变成h的高16位与h的低16位异或计算。在来看看HASH_BITS的值是啥。
static final int HASH_BITS = 0x7fffffff; // usable bits of normal node hash
换算成二进制就是0111 1111 1111 1111 1111 1111 1111 1111。
&是按位与运算符,同时为1,则为1,不同为0。通过二进制的计算可以减少hash碰撞,通过位计算可以提高计算效率。来看看putval()
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());// 计算hash值,通过两层二进制计算,减少hash碰撞的次数,碰撞减少则会是hash桶的链表长度变短,提高查询效率
int binCount = 0;
for (Node[] tab = table;;) {// table哈希桶是数组,长度是2的倍数,是懒加载,第一次插入元素时才会被初始化,被volatile修饰,在并发情况下保持多线程可见性。
Node f; int n, i, fh;
if (tab == null || (n = tab.length) == 0) // 第一次插入数据,出发table的初始化。
tab = initTable();// 看initTable方法的讲解
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {// 元素所在的table对应链表的第一个元素为空
if (casTabAt(tab, i, null,
new Node(hash, key, value, null)))// CAS赋值
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)// MOVED表示这个位置说明经历过resize,这个元素已经移动到新的位置
tab = helpTransfer(tab, f);//
else {
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node pred = e;
if ((e = e.next) == null) {
pred.next = new Node(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
Node p;
binCount = 2;
if ((p = ((TreeBin)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
initTable
直接上代码吧,这里很简单。
private final Node[] initTable() {
Node[] tab; int sc;
while ((tab = table) == null || tab.length == 0) { // 再次检查是否已经被其他线程初始化过了
if ((sc = sizeCtl) < 0) // 再次再次检查table的状态,小于零说明正在扩容
Thread.yield(); // 让出当前线程cpu资源,进入等待线程队列(从线程的状态而言,此时处于Runnable,更详细一点就是处于Runnable中的Ready状态,随时都有可能被分配个cpu时间分片执行,等到被唤醒后,如果table已经被初始化完毕之后,则退出while自旋,结束initTable的调用,这也是为什么使用自旋的原因。
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {// SIZECTL 和sc的大小一样,这设置sizeCtl=-1,表示正在初始化。
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node[] nt = (Node[])new Node[n];
table = tab = nt;
sc = n - (n >>> 2);// 计算下次扩容的大小,也就是扩容数量*0.75(扩容因子) ,我想这样 计算应该是为了速度吧,位计算比较快。
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}
putAll
public void putAll(Map m) {
tryPresize(m.size());
for (Map.Entry e : m.entrySet())
putVal(e.getKey(), e.getValue(), false);
}
tryPresize的目的为了使table能够容纳下集合m,来看下tryPresize
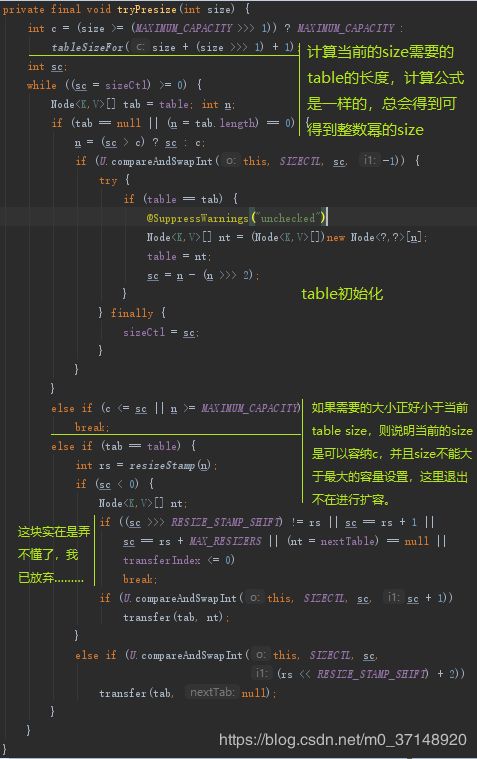
addCount
待更新
helpTransfer
待更新
transfer
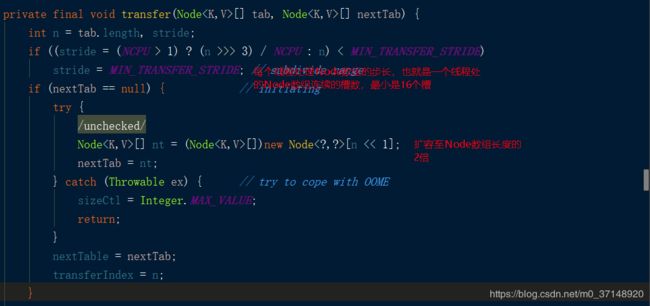

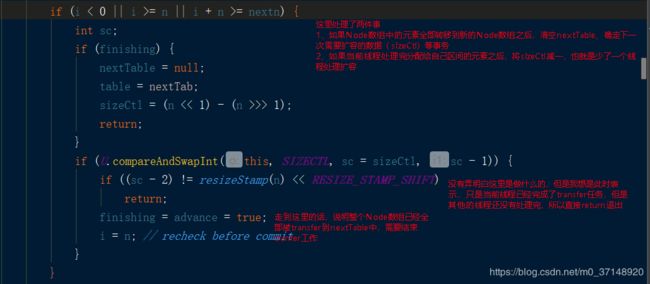
最后才是真正的transfer process

f就是当前Node,使用synchronized,在转移过程中,防止修改数据。

先来看看,Node数组的长度是怎么确定的?

初始化的过程,cap 要不是MAXIMUM_CAPACITY,要不就是tableSizeFor的结果。
![]()

所以无论是MAXIMUM,还是tableSizeFor,cap的大小肯定是2的多少次方。
runBit = fh & n fh是node的hash值,n是链表的长度,n是2的多少幂的值,总之n换成2进制之后只有一个1,这个1处于n的2次幂+1的位置,比如n=16 ,n的二进制是0000 0000 0000 0000 0000 0000 0001 0000那么2的幂是4,那么这个位置是从右往左第5位,我们这里称这个位置的为P。

当前线程扩容的的槽是15,链表的元素是:f->g->h->i->j。
绿色框代表节点的hash & n 值是1,红色框代表 hash & n 的值为0,因为n的二进制中只有一位是1,所以 hash & n 等与0 或者1,通过第一次链表的遍历获得runBit = 1 ,lastRun = i,将要产生的两个新的链表分别是hn和ln,hn用来表示 hash & n = 1的节点,也就是绿色的节点,进过遍历后,
hn链表的数据是:f->i->j
ln链表的数据是:h->g
最后将ln放置nextTable的i位置,将hn放置nextTable的i+n的位置上。nextTable此时的数据结构如下:

TreeBin的转移与链表的转化类似。
size
待更新
1.8的ConcurrrentHashMap还有一些细节没有搞明白,等了解后再更新,有些细节真的很难琢磨。