问题
压测时发现系统的瓶颈在于cpu,那么考虑为啥瓶颈在cpu,以及如何优化?
发现过程
测试环境使用jmeter进行接口压测,然后逐步调大并发度,观察系统吞吐量,然后在ares平台(类似skywalking)上监测JVM内存,CPU,线程状态等
然后发现,gc信息和内存信息很稳定,但是cpu会达到90%,这时查看jvm的线程状态,发现又70%左右的线程处于waiting或者timed_waiting状态;
初步推算会不会是线程过多导致cpu过高。
问题分析
首先分析接口的执行流程以及线程池的使用场景

简单的描述一下:客户端发来一个请求,由容器线程接收,然后通过common线程池创建多个线程去并发执行,然后通过latch进行等待,等所有的common线程执行完在合并然后返回给客户端;每一个common线程是一个小任务可以称为“单品查佣”,common线程会首先使用select线程池创建4个并行任务进行参数转换,并且通过latch进行等待然后合并,紧接着继续并发进行查询,此时也是使用select线程池先去并发查询然后再common线程里面合并计算结果。
上图颜色相同的表示在同一个线程或者线程池,通过上图可以大概得出common线程池和select线程池线程个数比为1:5(是不是真的这么去设置线程池大小呢?)。
希望本文对你有所帮助,加入我们,了解更多,642830685,领取最新软件测试大厂面试资料和Python自动化、接口、框架搭建学习资料!技术大牛解惑答疑,同行一起交流
开始压测
压测环境和结果
说明:由于之前做过一次优化,基本将DB和ES的压力因素去除了,JVM中的内存,带宽因素基本也排除了,目的就是为了看CPU压力。
环境:首先根据业务场景,分析由于整个流程中有多次的RPC调用或者Redis等数据请求所以初步将任务定义为IO等待型,目标机器配置2C4G * 2 ,同用的测试参数
工具:Jmeter
压测结果:

结果分析
1、在common,select线程数分别为5,25时(第一组数据),随着并发数的上升cpu并没有徒增,稳定在80%左右,但是tps并没有线性增长,平均响应时间也明显下降了不少,但是 发现并发数的提高没有将 CPU 压到极限 ,开始怀疑是业务线程相关了。
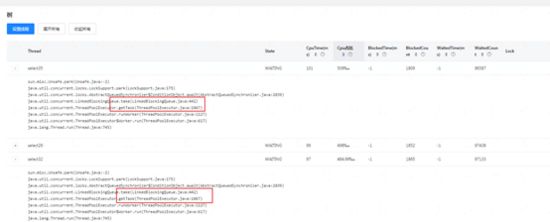
这个时候通过ares平台分析JVM线程状态,发现如下:

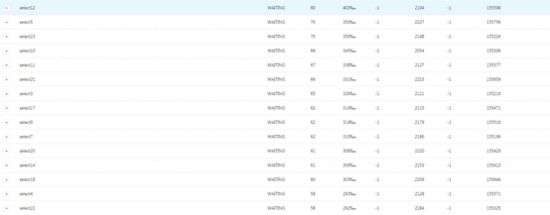
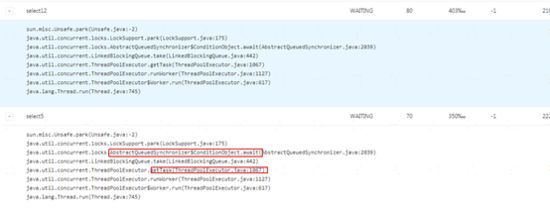
然后查看等待状态的线程,发现大部分是select的线程,而且大部分处于getTask方法上面,熟悉线程池运行原理的同学都知道,这个是在获取任务,因为没有任务了所以阻塞等待了,所以可以指定select的线程个数明显设置过多。从另一方面也说明,common和select的线程个数比不对,不是按照分析1:5 设置。因此下面的测试降低select的线程数。
2、common和select线程数分别为5,10时,减少了select线程的个数,cpu和tps和刚刚差不多,但是select的等待线程少了,这里慢慢发现common线程个数对tps和cpu有一定的影响,而select线程个数影响不大。这时发现增大并发数并不会显著提高TPS,但是响应时间是会明显增加。
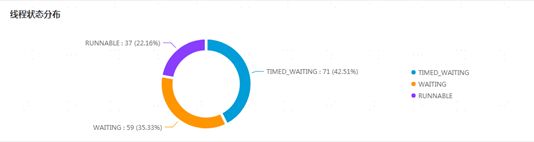
3、common和select线程数分别为10,10时,大部分common线程在latch上面等待,会不会是select线程不够用?随着并发数增多,响应时间在下降,但是tps并没有增加,具体可以看下图,common在latch上面(和代码对应),


4、common和select线程数分别为10,20时,通过观察线程状态,select线程出现等待getTask,cpu会到达94%,tps相应的也会增加,并发数的增加也只是提高了tps,但是会导致响应时间的下降;另外并发增大时,select线程都在执行任务,common线程出现在latch上面等待,但是响应时间慢了,cpu忙了,因为所有的select线程都在运行,线程上下文切换(CS)次数肯定会大量增加(可以vmstat查看),

初步总结
总结: 综合这4组压测数据,初步有个简单的结论,common线程池决定了整体的吞吐量(TPS),但是吞吐量提升的的同时,CPU和响应时间也会增大,而select线程需要依赖common线程的个数,比例在1.5-2之间,少了会导致TPS上不去响应时间也会增加,大了CPU上去了,最终也会导致响应时间的增加,所以common和select线程数的选择需要有据可询。那么针对当前的机器配置,兼顾TPS,响应时间和CPU使用率(低于90%),common线核心程池数设置8,select线程数设为12,此时100的并发数,CPU最高在90%,TPS在760,平均响应时间100ms。
优化方向:
通过线程状态和业务流程的分析,我们发现可以将并发部分的业务流程进行细分,主要划分为IO等待型任务和CPU计算型任务,然后使用不同的线程池,IO型的就多设置线程数,CPU型的就少一点。有个初始经验值
IO 型:2 * CPU个数
CPU型:CPU个数 + 1
另外,分析过程中为了方便线程池配置的变更和观察使用公共包ThreadPoolManager来管理系统所有的线程池。有需要的可以使用
附
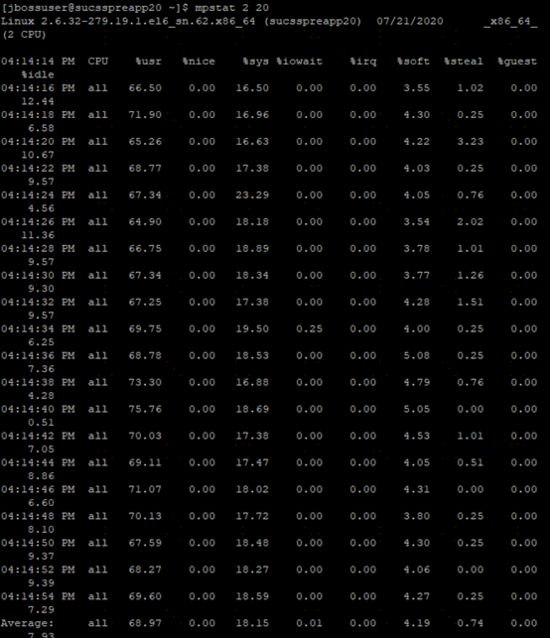
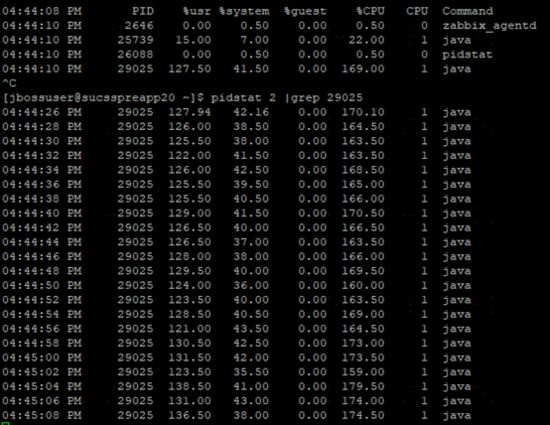
压测时机器的其他指标,供参考
Pidstat
Vmstat

Mpstat