flume+hbase+kafka集成部署
目录
一、架构图
二、flume的安装和配置
1. 下载安装
2. 配置
2.1 日志收集节点配置
2.2 日志聚集节点配置
2.3 Flume的二次开发
三、模拟程序开发
四、服务启动测试
1. 服务启动
1.1 zookeeper
1.2 HDFS
1.3 Hbase
1.4 kafka
2. 测试
Flume是一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方。flume包含三个部分:source、channel和sink。
本实例将使用flume收集日志数据分别写入到kafka(topic:logs)和hbase(table:logs)中,日志来源于:搜狗实验室,我们将用程序模拟webserver来写日志(webserverlogs文件)。
安装配置kafka集群请参阅:kafka的配置和分布式部署,安装配置Hbase数据库请参阅:Hbase的配置和分布式部署
说明:三台机器的主机名分别为:bigdata.centos01、bigdata.centos02、bigdata.centos03
一、架构图
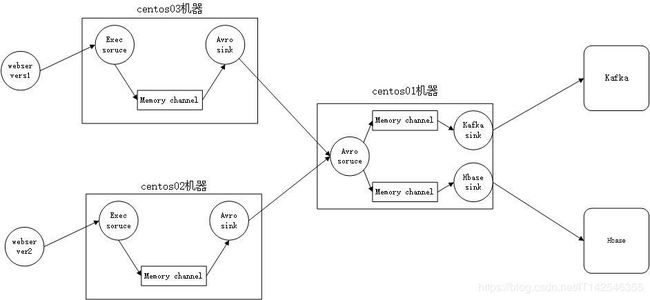
说明:centos02和centos03作为flume日志收集节点,centos01将两台机器收集到的日志进行聚合,然后再分别写入Kafka和Hbase数据库中。
二、flume的安装和配置
1. 下载安装
wget http://archive.apache.org/dist/flume/1.7.0/apache-flume-1.7.0-bin.tar.gz2. 配置
2.1 日志收集节点配置
如上图所示,修改centos02和centos03上flume节点配置
- conf/flume-env.sh修改
export JAVA_HOME=/opt/modules/jdk8- conf/flume-conf.properties修改
a1.sources = r1
a1.channels = c1
a1.sinks = k1
# source
# exec source:运行unix命令,实时读取webserverlogs日志文件,加入到flume
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /opt/datas/webserverlogs
a1.sources.r1.channels = c1
# channel
a1.channels.c1.type = memory
# sink
a1.sinks.k1.type = avro
a1.sinks.k1.channel = c1
a1.sinks.k1.hostname = bigdata.centos01
a1.sinks.k1.port = 55552.2 日志聚集节点配置
如上图所示,修改centos01上flume节点配置
- conf/flume-env.sh修改
export JAVA_HOME=/opt/modules/jdk8
export HADOOP_HOME=/opt/modules/hadoop-2.5.0
export HBASE_HOME=/opt/modules/hbase-0.98.6-cdh5.3.9
- conf/flume-conf.properties修改
agent.sources = avroSource
agent.channels = kafkaC hbaseC
agent.sinks = kafkaSink hbaseSink
#********************* flume + hbase 集成*********************
# source
agent.sources.avroSource.type = avro
agent.sources.avroSource.channels = hbaseC kafkaC
agent.sources.avroSource.bind = bigdata.centos01
agent.sources.avroSource.port = 5555
# channel
agent.channels.hbaseC.type = memory
agent.channels.hbaseC.capacity = 100000
agent.channels.hbaseC.transactionCapacity = 100000
agent.channels.hbaseC.keep-alive = 10
# sink
agent.sinks.hbaseSink.type = asynchbase
agent.sinks.hbaseSink.table = logs
agent.sinks.hbaseSink.columnFamily = info
agent.sinks.hbaseSink.serializer = org.apache.flume.sink.hbase.SimpleAsyncHbaseEventSerializer
agent.sinks.hbaseSink.channel = hbaseC
# 自定义列
agent.sinks.hbaseSink.serializer.payloadColumn=time,userid,searchname,retorder,cliorder,url
#********************* flume + kafka 集成*********************
# channel
agent.channels.kafkaC.type = memory
agent.channels.kafkaC.capacity = 100000
agent.channels.kafkaC.transactionCapacity = 100000
agent.channels.kafkaC.keep-alive = 10
# sink
agent.sinks.kafkaSink.channel = kafkaC
agent.sinks.kafkaSink.type = org.apache.flume.sink.kafka.KafkaSink
agent.sinks.kafkaSink.kafka.topic = logs
agent.sinks.kafkaSink.kafka.bootstrap.servers = bigdata.centos01:9092,bigdata.centos02:9092,bigdata.centos03:9092
agent.sinks.kafkaSink.kafka.producer.acks = 1
agent.sinks.kafkaSink.kafka.flumeBatchSize = 502.3 Flume的二次开发
- 下载源码
http://archive.apache.org/dist/flume/1.7.0/apache-flume-1.7.0-src.tar.gz- 代码修改
由于上面centos01 flume hbasesink配置的SimpleAsyncHbaseEventSerializer类不能满足我们的需求,它默认是往Hbase里面写一列,我们的需求是分隔日志数据分别存储到我们定义的不同列,故需要对其进行二次开发。主要修改了getActions函数。
package org.apache.flume.sink.hbase;
import com.google.common.base.Charsets;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.FlumeException;
import org.apache.flume.conf.ComponentConfiguration;
import org.apache.flume.sink.hbase.SimpleHbaseEventSerializer.KeyType;
import org.hbase.async.AtomicIncrementRequest;
import org.hbase.async.PutRequest;
import java.util.ArrayList;
import java.util.List;
public class SimpleAsyncHbaseEventSerializer implements AsyncHbaseEventSerializer {
private byte[] table;
private byte[] cf;
private byte[] payload;
private byte[] payloadColumn;
private byte[] incrementColumn;
private String rowPrefix;
private byte[] incrementRow;
private KeyType keyType;
@Override
public void initialize(byte[] table, byte[] cf) {
this.table = table;
this.cf = cf;
}
@Override
public List getActions() {
List actions = new ArrayList();
if (payloadColumn != null) {
try {
String[] columns = new String(payloadColumn).split(",");
String[] values = new String(payload).split(",");
if (columns.length != values.length) {
return actions;
}
String rawKey = values[0] + values[1] + System.currentTimeMillis();
for (int i = 0; i < columns.length; i++) {
String column = columns[i];
String value = values[i];
PutRequest putRequest = new PutRequest(table, rawKey.getBytes("utf-8"), cf,
column.getBytes(), value.getBytes("utf-8"));
actions.add(putRequest);
}
} catch (Exception e) {
throw new FlumeException("Could not get row key!", e);
}
}
return actions;
}
public List getIncrements() {
List actions = new ArrayList();
if (incrementColumn != null) {
AtomicIncrementRequest inc = new AtomicIncrementRequest(table,
incrementRow, cf, incrementColumn);
actions.add(inc);
}
return actions;
}
@Override
public void cleanUp() {
// TODO Auto-generated method stub
}
@Override
public void configure(Context context) {
String pCol = context.getString("payloadColumn", "pCol");
String iCol = context.getString("incrementColumn", "iCol");
rowPrefix = context.getString("rowPrefix", "default");
String suffix = context.getString("suffix", "uuid");
if (pCol != null && !pCol.isEmpty()) {
if (suffix.equals("timestamp")) {
keyType = KeyType.TS;
} else if (suffix.equals("random")) {
keyType = KeyType.RANDOM;
} else if (suffix.equals("nano")) {
keyType = KeyType.TSNANO;
} else {
keyType = KeyType.UUID;
}
payloadColumn = pCol.getBytes(Charsets.UTF_8);
}
if (iCol != null && !iCol.isEmpty()) {
incrementColumn = iCol.getBytes(Charsets.UTF_8);
}
incrementRow = context.getString("incrementRow", "incRow").getBytes(Charsets.UTF_8);
}
@Override
public void setEvent(Event event) {
this.payload = event.getBody();
}
@Override
public void configure(ComponentConfiguration conf) {
// TODO Auto-generated method stub
}
}
将lib目录的flume-ng-hbase-sink-1.7.0.jar删除,把flume-ng-hbase-sink重新打包重命名为flume-ng-hbase-sink-1.7.0.jar,上传至flume的lib目录。我打包的jar包:flume-ng-hbase-sink.jar
三、模拟程序开发
通过模拟程序将搜狗实验室的日志文件逐行的写入到webserverlogs文件,供日志收集的flume收集。
package com.wmh.writeread;
import java.io.*;
public class ReadWrite {
public static void main(String[] args) {
String readFileName = args[0];
String writeFileName = args[1];
try{
System.out.println("执行中...");
process(readFileName,writeFileName);
System.out.println("执行完成!");
}catch (Exception e){
System.out.println("执行失败!");
}
}
private static void process(String readFileName, String writeFileName) {
File readFile = new File(readFileName);
if (!readFile.exists()){
System.out.println(readFileName+"不存在,请检查路径!");
System.exit(1);
}
File writeFile = new File(writeFileName);
BufferedReader br = null;
FileInputStream fis = null;
FileOutputStream fos = null;
long count = 1l;
try{
fis = new FileInputStream(readFile);
fos = new FileOutputStream(writeFile);
br = new BufferedReader(new InputStreamReader(fis));
String line = "";
while ((line = br.readLine()) != null){
fos.write((line + "\n").getBytes("utf-8"));
fos.flush();
Thread.sleep(100);
System.out.println(String.format("row:[%d]>>>>>>>>>> %s",count++,line));
}
}catch (Exception e){
try {
fis.close();
fos.close();
br.close();
} catch (IOException ex) {
System.out.println("关闭资源异常!");
System.exit(1);
}
}
}
}
四、服务启动测试
1. 服务启动
1.1 zookeeper
启动centos01、centos02、centos03的zookeeper
bin/zkServer.sh start1.2 HDFS
启动centos01的namenode、datanode,centos02和centos03的datanode
sbin/start-dfs.sh1.3 Hbase
- 服务启动
启动centos01的master、regionserver,centos02和centos03的regionserver
bin/start-hbase.sh- 创建表
# 进入命令行操作
bin/hbase shell
# 创建表
> create "logs","info"1.4 kafka
- 服务启动
启动centos01、centos02、centos03的kafka
bin/kafka-server-start.sh config/server.properties- 创建topic
创建flume配置的名为logs的topic
# --replication-factor 副本数,为了每个kafka可以单独对外服务,该项配置值为集群机器数
bin/kafka-topics.sh --create --zookeeper bigdata.centos01:2181,bigdata.centos02:2181,bigdata.centos03:2181 --replication-factor 3 --partitions 1 --topic logs- 启动consumer
启动任意一台机器上面的kafka consumer,供测试使用。
bin/kafka-console-consumer.sh --zookeeper bigdata.centos01:2181,bigdata.centos02:2181,bigdata.centos03:2181 --topic logs --from-beginning1.5 flume
- 启动centos01日志聚集flume
bin/flume-ng agent --conf conf --conf-file conf/flume-conf.properties -n agent -Dflume.root.logger=INFO,console- 启动centos01日志收集flume
bin/flume-ng agent --conf conf --conf-file conf/flume-conf.properties -n a1 -Dflume.root.logger=INFO,console主要区别在于:agent命名不一样,centos01命名为agent,centos02和centos03的命名为a1
1.6 模拟程序启动
将上面的模拟程序类打包成jar
#formatedSougouLog是经格式化的数据,将\t和空格替换成逗号
java -jar ReadWrite.jar formatedSougouLog webserverlogs2. 测试
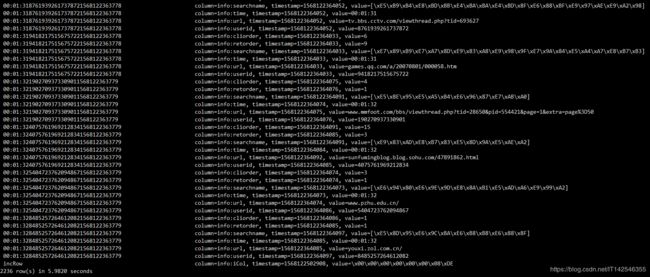
- hbase插入的数据
- kafka获取的数据