带你捋一捋anchor-free的检测模型:FCOS
AI编辑:我是小将
相比two-stage方法,one-stage的目标检测算法更受追捧。one-stage的模型目前可以分为两大类:anchor-based和anchor-free方法。基于anchor-based的检测模型包括SSD,YOLOv3,RetinaNet等,这些模型需要在每个位置预先定义一系列anchor来预测边界框,整个训练和测试阶段都依赖anchor。基于anchor-free的模型不需要anchor,主要是通过检测关键点来直接预测边界框,如CornerNet是检测物体的左上角和右下角顶点,但是却需要耗时的分组策略来得到最终的边界框,还有一类是检测物体中心点的方法,如CenterNet通过预测物体的中心点和大小来检测物体,架构上更简单,速度也更快。这里要介绍的FCOS属于anchor-free,但是却不是基于关键点检测的方法,严格来看其更接近基于anchor-based的方法,但是不需要anchor并加上特殊的设计却能够实现更好的效果。
从anchor说起
对于anchor-based的方法,其在输出特征图每个位置放置一系列固定的anchor,这样做的好处是将目标框和anchor绑定在一起,在训练过程中只需要计算GT和anchor的IoU并设定阈值条件来定义正负样本,另外一方面可以通过设定不同大小和宽高比的anchor来适应检测目标的尺度变化性,以保证召回。虽然基于anchor的检测算法取得了很好的效果,但是anchor总显得有点多余。其实YOLOv1并没有使用anchor,没有anchor的YOLOv1是直接将目标框和特征图上的cell绑定在一起,目标框的中心点落在这个cell内,但YOLOv1的recall较低,后面版本都用了anchor。但我们是可以将特征图上cell和目标框直接关联在一起,而不用anchor,这样目标检测就和语义分割一样变成了直接的pixel预测(pixel和cell是等同的)。FCOS就是这样做的,具体来说就是直接用包含目标的cell来回归目标,如图1所示,左图中橙色框中某个cell直接预测与目标框的4个偏移量,但是如果一个cell包含在多个目标之中,这就出现了冲突:这个cell到底该回归哪个目标?如右图所示。FCOS通过一系列设计来解决这个问题,这也是FCOS的核心。

图1 FCOS整体设计理念
FCOS采用的网络架构和RetinaNet一样,都是采用FPN架构,如图2所示,每个特征图后是检测器,检测器包含3个分支:classification,regression和center-ness。

图2 FCOS整体架构
检测器
对于特征图 ,其相对于输入图片的stride定义为 ,另外记GT为 ,这里,其中 和 分别是GT的左上角和右下角顶点坐标,而 是GT的类别。对于特征图上的每个位置 ,如果其落在任何GT的中心区域,就认为这个位置为正样本,并负责预测这个GT。在最早的版本是落在GT之内就算正样本,不过采用中心区域策略效果更好(????yqyao/FCOS_PLUS),两者的区别如图3所示。一个中心为 的GT,其中心区域定义为GT框的一个子框,这里 是特征图的stride,而 是一个超参数,论文中选用的是1.5,一个要注意的点是在实现中要保证中心区域不超过GT。尽管采用中心区域抽样方法,可以减少前面说的冲突问题,但是无法保证,如果一个位置落在了多个GT的中心区域,此时就是模糊样本。FCOS采用的一个策略是选择面积最小的GT作为target,后面会谈到结合FPN,FCOS可以大大减少模糊样本的出现。
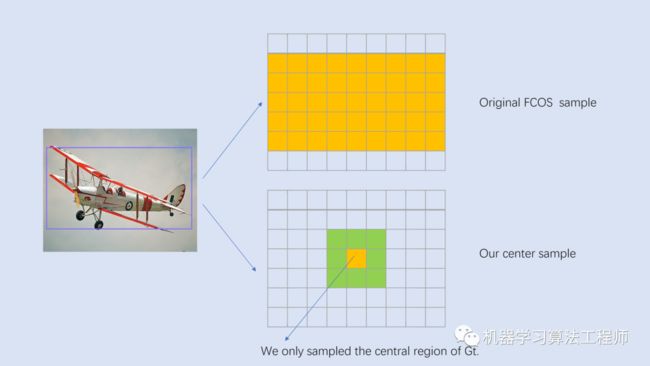
图3 正负样本的判定策略
对于classification分支,和RetinaNet一样采用 个二分类,共输出 个预测值,loss采用focal loss。对于regression分支,每个位置预测一个实数向量 ,其对应的target为当前位置与GT框4个顶点间的距离:
这里用特征图的stride来对回归的target进行缩放,以避免训练过程中的可能出现的梯度爆炸。由于4个回归值要大于0,最后的输出采用ReLU来保证回归值的范围为 。
FCOS在regression分支的末尾添加了一个额外的center-ness分支(最早的版本是放在classification分支,但是放在regression分支效果更好)来抑制那些由那些偏离目标中心的位置所预测的低质量检测框。center-ness分支只预测一个值:当前位置与要预测的物体中心点之间的归一化距离,值在[0, 1]之间,图4给出了可视化效果,其中红色和蓝色值分别1和0,其它颜色介于两者之间,从物体中心向外,center-ness从1递减为0。
 图4 center-ness可视化
图4 center-ness可视化
给定回归的 ,center-ness的target定义为:
由于center-ness值在0~1之间,训练过程中可以采用BCE损失。在测试阶段,最终的置信度为center-ness和分类概率的乘积:
这里的sqrt可以改变置信度的数量级(FCOS的预测框置信度偏低),但是不会影响评测的AP值。实验证明center-ness的使用可以使FCOS在COCO数据集上的AP值提升1个点左右,另外论文也定量分析了center-ness分支在压制低质量检测框的作用,如图5所示,可以看到未使用center-ness,FCOS会检出一定量的高置信度但低IoU的边界框(在IoU阈值下就是FP),而使用center-ness后这部分数量大大减少。
 图5 使用center-ness分支前后的定量分析
图5 使用center-ness分支前后的定量分析
长久以来,检测模型的分类和回归分支是孤立的,这可能导致模型对物体的分类和定位不一致,就像前面所说的分类概率高但定位不准确,如图6所示,这对于AP值是不利的。类似的工作还有????IoU-aware RetinaNet,在RetinaNet模型的回归分支增加一个预测IoU的分支,AP值可以提升1~2%。
图6 检测模型的分类和定位不一致
另外,最新的论文????Generalized Focal Loss更进一步地将对预测框的定位质量评估和分类分支联合在一起训练,因为FCOS的center-ness分支在训练时其实是和分类是分开的,只是在测试时结合在一起,这存在一个训练和测试的不一致。另外论文也指出用IoU比用center-ness评估预测框更好,主要原因在于center-ness的label往往要比IoU要小一些,如下图所示,这导致有可能一部分样本比较难召回。
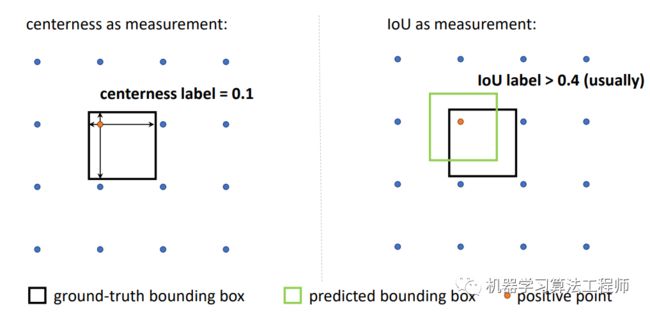 图7 IoU和center-ness的label对比
图7 IoU和center-ness的label对比
综上,FCOS的训练loss包含三个部分:
这里的 当为正样本时取1,为负样本时取0,所以 和 只有正样本才计算。而 为权重系数,在论文中均取1。前面已经说过分类loss采用focal loss,而center-ness采用BCE损失,这里的回归loss采用GIoU,其效果优于IoU。
FPN
对于anchor-based方法,采用FPN时会将不同大小的anchor放置在不同大小的特征图上,特征图越小,感受野相应更大,用来检测更大的物体。同样地,这种设计理念可以用在FCOS模型上,以解决前面所说的模糊样本问题。
与RetinaNet一样,FCOS也采用5个大小不同的特征图 ,其对应的stride分别是 。与RetinaNet不同的一点是, 和 在 之后加stride为2的3x3卷积得到,而不是来自于 ,这样好处是一方面可以减少参数量,另外由于产生的特征图语义更强而效果更好。
对于anchor-based方法,由于是根据anchor和GT的IoU来进行匹配,所以很自然地将大小不同的GT分配到不同的特征图。而FCOS直接通过限制不同特征图上目标回归值来达到这一目的。具体来说,每个特征图 会设定一个回归值的下限值 和上限值 ,某个GT在该特征图上正样本位置(满足前面所述的中心区域内条件)还要满足目标回归值大小限制:
这样就限制了不同特征图上的回归距离,从而将不同大小的目标分配到不同特征图上,因为不同特征图的感受野不同,通过这种方式可以确保要回归的物体整个包含在特征图的感受野内。论文中, 分别设定为 ,那么特征图 覆盖的是[0,64]之间的目标回归值,而 则是负责512以上的目标回归值。与RetinaNet一样,所有的检测器head在各个特征图上是共享的,但是由于不同特征图对应的回归值范围差异较大,可能学习成本大,所以最早版本FCOS在regression分支最后输出是乘以一个可学习的scale值以解决这个问题:
class Scale(nn.Module):
def __init__(self, init_value=1.0):
super(Scale, self).__init__()
self.scale = nn.Parameter(torch.FloatTensor([init_value]))
def forward(self, input):
return input * self.scale
但是现在的版本中,前面已经提到每个特征图上的回归值其实是已经除以特征图的 进行缩放,这样就和学习一个scale值基本等同,所以加不加这个策略都可以。
模糊样本的出现大部分是由于物体重叠造成的,但是重叠的物体大部分其大小是不同的,所以FPN的使用可以更一步解决模糊样本问题。
BPR
FCOS没有使用anchor,那么一个风险点就是和YOLOv1一样recall较低,论文中通过计算训练过程中BPR指标( Best Possible Recall)证明了FCOS的recall上限与RetinaNet基本相差不大。这里的BPR定义为训练过程中所有GT的最大召回率,如果训练过程中一个GT被某个anchor或者location匹配上那么就认为被召回了。基于COCO val2017数据集,RetinaNet和FCOS的BPR指标如表1所示,可以看到FCOS使用FPN后BPR可以达到98.95%,仅仅稍低于采用low-quality-matches(指的是允许某个GT匹配给IoU最大的anchor,尽管最大IoU值可能低于阈值)的RetinaNet。从BPR指标来看,FCOS和RetinaNet基本相差无几。不过BPR还是都没有达到100%,这主要是因为前面所说的模糊样本问题,或者说是冲突。
 表1 RetinaNet和FCOS的BPR指标对比
表1 RetinaNet和FCOS的BPR指标对比
论文中也统计了模糊样本占比,如表2所示,这里的1, 2 ≥ 3表示一个位置被分配给GT的数量,当大于1时这个位置就是模糊样本。可以看到采用中心抽样策略和FPN后,FCOS模糊样本占比只有2.66%。
 表2 FCOS模糊样本分布统计
表2 FCOS模糊样本分布统计
模型效果
这里主要关注FCOS和RetinaNet模型在COCO数据集上的效果对比,如表3所示,可以看到FCOS的AP明显高于原生RetinaNet(38.9 VS 35.9)。但是当RetinaNet也采用FCOS的某些策略(GN,GIoU loss和FPN用P5替代C5来得到P6,P7),RetinaNet模型效果也提升较大,仅和FCOS相差一个点左右。更进一步,如果FCOS去掉center-ness分支,FCOS和RetinaNet效果基本接近了。另外????ATSS也证明了如果RetinaNet如果仅每个位置放置一个anchor,但采用FCOS的所有策略,两种效果差别也不大。这就说明其实anchor-free和anchor-based的方法实际效果相差并不大,FCOS和RetinaNet的差异仅在于两者对正负样本定义策略差异,据此ATSS也提出了效果更好的策略。不过依然致敬FCOS,毕竟也是一个非常扎实的work。

表3 FCOS和RetinaNet对比
FCOS核心实现
目前FCOS官方代码已经开源在????AdelaiDet,代码基于detectron2框架。这里主要关注FCOS最核心的部分,就是正负样本的定义策略,代码如下:
def compute_targets_for_locations(self, locations, targets, size_ranges, num_loc_list):
"""
Args:
locations: [N, 2], 所有FPN层cat后的位置
targets: GT,detectron2格式
size_ranges: [N, 2], 各个位置所在FPN层的回归size限制(min,max)
num_loc_list: list,各个FPN层的位置数
"""
labels = [] # 各个位置的类别target
reg_targets = [] # 各个位置的回归target
xs, ys = locations[:, 0], locations[:, 1] # 位置x,y坐标
num_targets = 0 # 用于索引
# for循环处理各个image
for im_i in range(len(targets)):
targets_per_im = targets[im_i]
bboxes = targets_per_im.gt_boxes.tensor # [M, 4]
labels_per_im = targets_per_im.gt_classes # [M]
# 无GT,默认target全为负样本
if bboxes.numel() == 0:
labels.append(labels_per_im.new_zeros(locations.size(0)) + self.num_classes)
reg_targets.append(locations.new_zeros((locations.size(0), 4)))
continue
area = targets_per_im.gt_boxes.area() # [M]
# 计算每个位置与各个GT的l,t,r,b
l = xs[:, None] - bboxes[:, 0][None] # [N, M]
t = ys[:, None] - bboxes[:, 1][None] # [N, M]
r = bboxes[:, 2][None] - xs[:, None] # [N, M]
b = bboxes[:, 3][None] - ys[:, None] # [N, M]
reg_targets_per_im = torch.stack([l, t, r, b], dim=2) # [N, M, 4]
if self.center_sample: # 中心采样
is_in_boxes = self.get_sample_region(
bboxes, self.strides, num_loc_list, xs, ys,
bitmasks=None, radius=self.radius
) # [N, M]
else: # 全部采样
is_in_boxes = reg_targets_per_im.min(dim=2)[0] > 0 # [N, M]
max_reg_targets_per_im = reg_targets_per_im.max(dim=2)[0] # [N, M]
# 限制每个位置所属FPN的size限制
is_cared_in_the_level = \
(max_reg_targets_per_im >= size_ranges[:, [0]]) & \
(max_reg_targets_per_im <= size_ranges[:, [1]]) # [N, M]
# GT的面积
locations_to_gt_area = area[None].repeat(len(locations), 1) # [N, M]
locations_to_gt_area[is_in_boxes == 0] = INF # 排除条件1:GT内或者GT中心区域
locations_to_gt_area[is_cared_in_the_level == 0] = INF # 排除条件2:FPN size限制
# 每个位置可能匹配多个GT,所以要选取最小面积的GT
# locations_to_gt_inds: [N], 每个位置要回归的GT index
locations_to_min_area, locations_to_gt_inds = locations_to_gt_area.min(dim=1)
# 回归target
reg_targets_per_im = reg_targets_per_im[range(len(locations)), locations_to_gt_inds]
# 分类target
labels_per_im = labels_per_im[locations_to_gt_inds]
# 负样本处理,这里用self.num_classes为负样本
labels_per_im[locations_to_min_area == INF] = self.num_classes
labels.append(labels_per_im)
reg_targets.append(reg_targets_per_im)
总体上看,代码逻辑比RetinaNet的IoU策略更复杂一些,这里只需要计算分类和回归的target即可,因为center-ness分支的target可以用回归target计算得到:
def compute_ctrness_targets(reg_targets):
if len(reg_targets) == 0:
return reg_targets.new_zeros(len(reg_targets))
left_right = reg_targets[:, [0, 2]]
top_bottom = reg_targets[:, [1, 3]]
ctrness = (left_right.min(dim=-1)[0] / left_right.max(dim=-1)[0]) * \
(top_bottom.min(dim=-1)[0] / top_bottom.max(dim=-1)[0])
return torch.sqrt(ctrness)
至于上面的中心采样策略,其实现代码如下,注意中心区域要限制在GT内:
def get_sample_region(self, boxes, strides, num_loc_list, loc_xs, loc_ys, bitmasks=None, radius=1):
center_x = boxes[..., [0, 2]].sum(dim=-1) * 0.5 # [M,]
center_y = boxes[..., [1, 3]].sum(dim=-1) * 0.5 # [M,]
num_gts = boxes.shape[0]
K = len(loc_xs)
boxes = boxes[None].expand(K, num_gts, 4) # [N, M, 4]
center_x = center_x[None].expand(K, num_gts) # [N, M]
center_y = center_y[None].expand(K, num_gts) # [N, M]
center_gt = boxes.new_zeros(boxes.shape) # [N, M, 4]
# 无GT
if center_x.numel() == 0 or center_x[..., 0].sum() == 0:
return loc_xs.new_zeros(loc_xs.shape, dtype=torch.uint8)
beg = 0
# for循环处理各个FPN层
for level, num_loc in enumerate(num_loc_list):
end = beg + num_loc
# 计算中心区域范围
stride = strides[level] * radius
xmin = center_x[beg:end] - stride
ymin = center_y[beg:end] - stride
xmax = center_x[beg:end] + stride
ymax = center_y[beg:end] + stride
# 限制中心区域不超过GT
center_gt[beg:end, :, 0] = torch.where(xmin > boxes[beg:end, :, 0], xmin, boxes[beg:end, :, 0])
center_gt[beg:end, :, 1] = torch.where(ymin > boxes[beg:end, :, 1], ymin, boxes[beg:end, :, 1])
center_gt[beg:end, :, 2] = torch.where(xmax > boxes[beg:end, :, 2], boxes[beg:end, :, 2], xmax)
center_gt[beg:end, :, 3] = torch.where(ymax > boxes[beg:end, :, 3], boxes[beg:end, :, 3], ymax)
beg = end
left = loc_xs[:, None] - center_gt[..., 0]
right = center_gt[..., 2] - loc_xs[:, None]
top = loc_ys[:, None] - center_gt[..., 1]
bottom = center_gt[..., 3] - loc_ys[:, None]
center_bbox = torch.stack((left, top, right, bottom), -1)
inside_gt_bbox_mask = center_bbox.min(-1)[0] > 0 # 位置在GT的中心区域
return inside_gt_bbox_mask
总结
FCOS是一个很特别的基于anchor-free的检测模型,因为它不是基于关键点进行检测,而是每个位置直接回归目标,从另外一方面讲,FCOS虽没有anchor,但实际上和RetinaNet非常相似。但是FCOS依然是一个不错的工作,它让我们重新思考这种密集anchor的方式其实非常不必要,只要采用更好的正负样本定义策略,ATSS更进一步强化了这个问题的重要性。
参考
????FCOS: A Simple and Strong Anchor-free Object Detector
????IoU-aware Single-stage Object Detector for Accurate Localization
????Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection
????Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection
????AdelaiDet
如果觉得不错,请关注一下公众号,也请为小编点个在看,关注公众号,回复加群,进群学习交流
推荐阅读
VoVNet:实时目标检测的新backbone网络
算法工程师面试必选项:动态规划
算法工程师面试必考项:排序算法
物体检测和分割轻松上手:从detectron2开始(上篇)
物体检测和分割轻松上手:从detectron2开始(下篇)
想读懂YOLOV4,你需要先了解下列技术(一)
想读懂YOLOV4,你需要先了解下列技术(二)
PyTorch分布式训练简明教程
机器学习算法工程师
一个用心的公众号