线上故障分析: Memory cgroup out of memory: Kill process ...(结合dmesg 、jstack命令和jvisualvm工具综合分析)
1、在某一天时段,我生产上的程序突然宕机了,部署在linux 程序被Killed掉;
使用 dmesg -T >my.log 命令输出到my.log日志,查看系统日志,至于dmesg有什么用,参考这篇博客:
https://blog.csdn.net/shuihupo/article/details/80905641?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.nonecase&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.nonecase
2、根据dmesg -T的结果观察日志,发现如下:
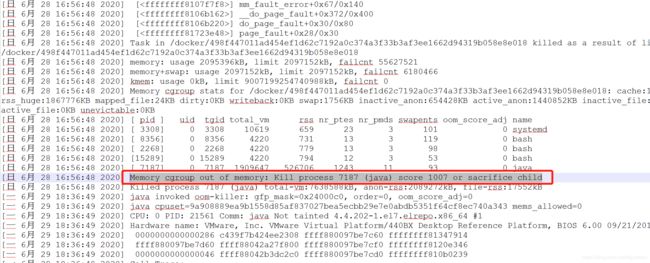
查找到这条信息:Memory cgroup out of memory: Kill process 7187 (java) score 1007 or sacrifice child
为什么程序会被kill掉了?原来在Linux下, 允许应用可以预申请内存,预申请的内存如果超过了Linux最大剩余内存,由于系统的保护机制,就会停掉默认内存占用最大的应用进程;
参考这篇博客:https://blog.csdn.net/renfufei/article/details/78178757?utm_source=blogxgwz5
3、查看GC日志,发现一分钟内进行了3次Full GC
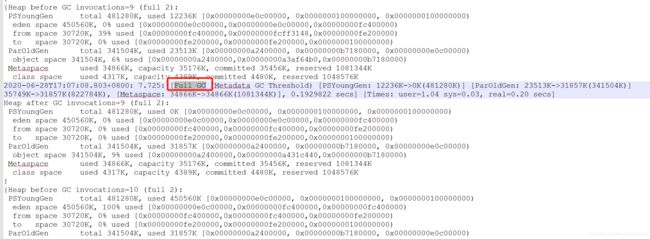
在哪些情况下,程序会进行Full GC呢,继续参考博客:
https://blog.csdn.net/YHYR_YCY/article/details/52566105?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase
4、登录了生产的应用,发现除了宕机的其它机器上,其它机器都没有业务请求的日志,只有宕机的这一台有程序运行业务日志,是因为运维的nigix配置问题,把所有的请求都分到了宕机的这台机器上,另外的应用机器,虽然服务正常启动,但是没有接收到分发过来的用户请求;
所以我暂时把此问题理解成了运维的锅;
解决方案:给机器加内存,并且修改nigix配置,使用户请求均衡分发到每一台应用上;
5、以为问题就这样解决了,但是没有过多久,半个月以后,又发生了程序内存占用高,频繁报错的情况,虽然没有由于内存过高导致系统被Linux停掉,但很多用户的请求接口超时,无法正常使用;
先从logback中找到了这样的异常日志:Could not get a resource from the pool#012#011at redis.clients.util.Pool.getResource

查看代码,之前redisPool没有设置大小,默认为8,尝试修改一下,修改为配置文件中设置的100
spring.redis.pool.max-active=100

6、然后使用jstack -l pid,查看线程stack有什么异常:
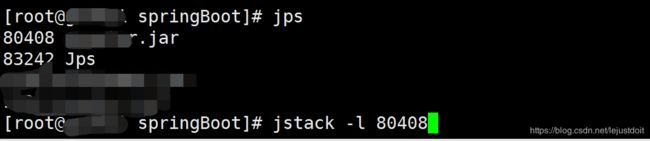
发现里面有大量的redisson waiting(程序里面使用到的redis客户端)状态:

其实在上面,我们看到已经使用了JedisPool来作为redis客户端连接,这里又引入了RedissonClient,显得有些重复多余了
(Redisson 不仅封装了 redis ,还封装了对更多数据结构的支持,以及锁等功能,相比于Jedis 的话功能更加强大)

7、继续分析jstack输出的线程stack日志,有很多 Mysql TIMED_WAITING(先关注,这个问题在下面继续分析)

8、这里logback还改了一下输出日志级别,之前只打印了info日志,现在BusinessException异常的改成error级别日志,看看还有哪些程序错误没有通过error日志抛出来:

9、然后程序上线了一版,继续监控可能会出现的问题:
发现了mysql锁等待超时异常(也印证了上面第7步 jstack日志中,很多 Mysql TIMED_WAITING 状态的问题):
Error updating database. Cause: com.mysql.jdbc.exceptions.jdbc4.MySQLTransactionRollbackException: Lock wait timeout exceeded; try restarting transaction#012### The error may involve com********.dao.iface.SessionRecordMapper.updateByPrimaryKey
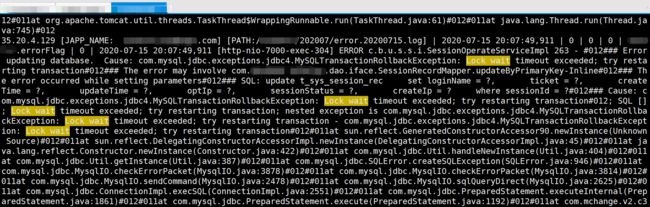
这里的异常可能之前日期就有发生过,由于上面第8步,之前的info日志输出,可能导致了忽略关注,现在才看到;
10、分析Mysql Lock wait timeout exceeded异常:
com.mysql.jdbc.exceptions.jdbc4.MySQLTransactionRollbackException: Lock wait timeout exceeded:
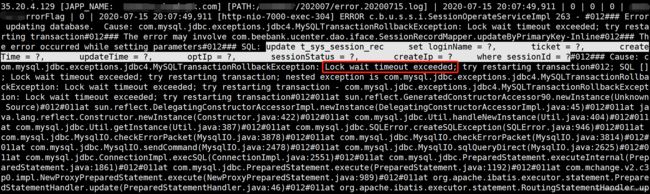
这里的一行sql语句,执行update *** where 的时候,报错;先看一下这个表结构:
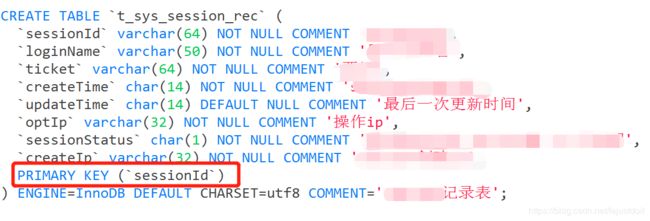
在表t_sys_session_rec中,sessionId是作为主键,主键是默认走索引的,并且在innodb引擎下,是支持行锁的;这一行数据,相同sessionId的情况,sql执行的并发量也不是很大,为什么会频繁出现等待锁超时呢?
找到执行sql的代码,updateByPrimaryKey方法:

找 updateSession调用的方法,在/ticket校验方法里面,用户每次过来校验ticket的时候,都会调用这个方法,更新updateSession:

就是这里,发生mysql锁频繁超时的地方,是否还有其它地方去竞争这行数据,t_sys_session_rec 这张表的资源呢?
11、发现定时任务在竞争表资源:
这个定时的大概思路是:每60秒执行一次,写一个线程监听,while(true),然后一直轮询,查询数据库后台表t_sys_session_rec,当前时间now(),比update字段时间值,计算出来大于 overTime 6个小时的session记录,逐条置为无效
(这种定时任务执行方式不推荐):

12,找到mapper.xml中的 sessionRecordMapper.selectAllWillExpireSession 方法:

上面where条件里面的createIp字段和updateTime字段并没有加索引,导致全表扫描,并且随着表中数据越来越多的情况下,导致了锁表情况发生,所以上面的 sessionRecordMapper.updateByPrimaryKey()方法才会发生锁等待超时;
(其实根源问题在于这里,由于这个锁表操作,/ticket接口的其它请求线程,是先获取redis连接,并且获取以后没有释放redis连接,然后再去获取mysql锁,由于拿不到mysql锁,并且redis连接池默认连接数8,并且mysql连接池设置的是100,所以先是redis连接不够用,在上面第5、第6步抛出了异常Could not get a resource from the pool at redis.clients.util.Pool.getResource)

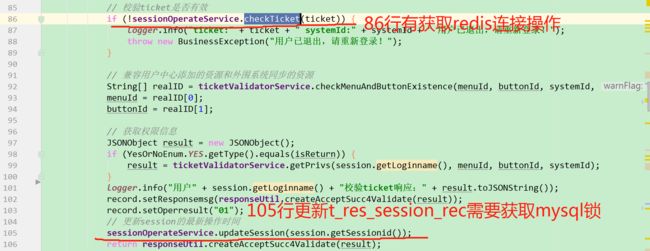
13、解决方案:
开始想了一种简单解决方案,清除表中记录,createIp字段和updateTime字段增加索引,那么就不需要重启应用程序,让用户正常继续使用程序,但是能解决问题吗?
updateTime经常被更新,如果字段值经常被修改,那么每次数据库重建索引的开销也很大,短期来看,可以临时解决现在的问题,就算加了索引以后,这里的where条件查询对updateTime使用了函数计算,表达式,也会导致查询索引失效;
为了验证这一点,在测试环境,先给updateTime字段加上索引,去掉其它几个字段的where条件检索,然后explain执行一下sql语句,发现扫描的type 是 all:
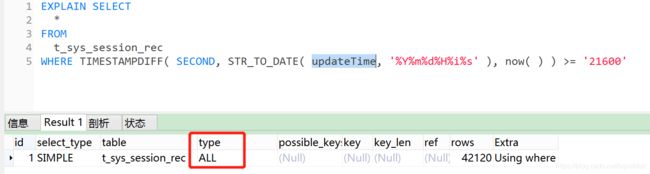
(还有哪些情况会导致索引失效,可以参考这里:
https://blog.csdn.net/bless2015/article/details/84134361?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-5.nonecase&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-5.nonecase)
所以最后的解决方案:是删除t_sys_session_rec记录表,把用户校验的ticket存取都用redis(这里涉及修改的代码就比较多了,不全贴出来);
![]()
14、到这里还没有结束,由于还有内存占用过高的问题,继续从线上服务器导出堆dump文件分析:
jmap -dump:live,format=b,file=/data1/springBoot/heap.hprof pid

(上面的命令,是实时导出dump文件,会影响系统运行性能;还有另外一种导出dump文件方式,在java进程启动参数配置:
加上 例如 -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/usr/local/heap.hprof,
完整启动参数:
JAVA_OPTS="$JAVA_OPTS -server -Xms3G -Xmx3G -Xss256k -XX:PermSize=128m -XX:MaxPermSize=128m -XX:+UseParallelOldGC -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/usr/local/heap.hprof -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:/usr/local/gc.log -XX:NewSize=1G -XX:MaxNewSize=1G"
这样在程序宕机之前,会给你生成一份dump文件,参考这篇博客:https://www.cnblogs.com/m2492565210/p/7498438.html)
15、使用jdk本地自带的jvisualvm工具,打开D:\Program Files\Java\jdk1.8.0_201\bin\jvisualvm.exe,分析dump出来的文件:点击文件,装入:
选择刚才dump出来的文件heap.hprof:
16、发现如下些对象,占用比例是最多的:
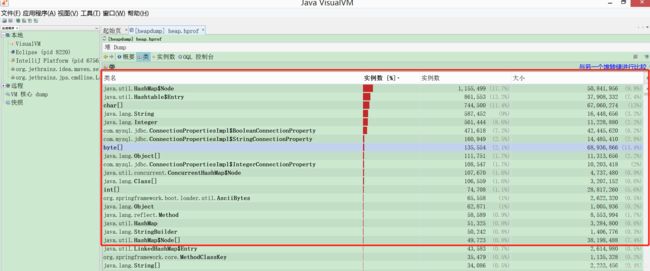
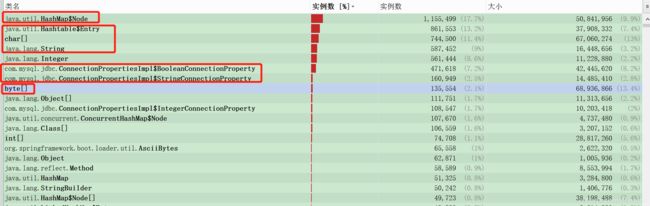
HashMap里面的Node对象内部类(HashMap$Node,HashMap底层其实就是Node对象组成的数组,Node是内部类),Hashtable对象里面的Entry内部类(Hashtable$Entry),还有char[],byte[],jdbc连接(Mysql Lock wait timeout exceeded 产生的过多对象侧面在这里印证了)等等,这些是占用内存最高,或者实例创建最多的对象:
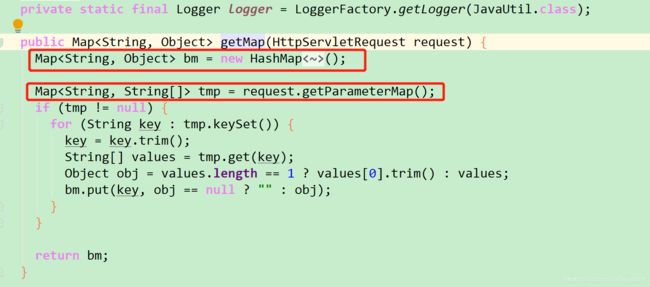
17、结合代码再来看上面的堆内存分析问题:
这个系统,是一个单点集成登录功能,程序调用最多的就是 */ticket 票据校验接口,看接口入口的第50行代码,

仅仅是取参数,里面就创建了两个HashMap对象 ,为了就是把Map对象中的key和value全部遍历一遍然后去空格?这样的开销很大,本来HashMap对象就是用哈希算法存取对象的一种方式,以存储空间换时间的理念集合对象,HashMap会比其它集合更占用内存空间
退出这个方法,再回到刚才/ticket校验接口那里,52行代码处,paramMap = javaUtil.getMapForSync(request); 进方法:
里面又创建了HashMap:

这样一来,每天/ticket 校验接口访问量在40~50w左右,那么光HashMap参数对象就会创建150w个左右。
还有程序其它有使用com.alibaba.fastjson.JSONObject地方:

进入 com.alibaba.fastjson.JSONObject 对象中:在JSONObject对象的底层,也是基于Map实现的

所以也就解释了jvisualvm分析出来那么多Map对象的原因了;
所以除了上面mysql的 Lock wait timeout exceeded异常,这里的代码也是需要优化的地方;
18、继续看jvisualvm中String对象占用的问题:
代码这里,创建了好几个字符串对象,只是用来校验一下是否必填?(类似这样的写法,在其他地方也发现了)

String类的底层实现,其实是char[]数据,我们可以在源码中看到,常用构造方法:这里的this.value就是一个char[]数组:
this.value = original.value;


所以也就解释了,上图中用jvisualvm分享出来,那么多String和char[]对象了:
19、关于Hasstable$Entry 那么多对象,搜了一下,代码中并没有使用过Hashtable,
但是使用了Properties,Properties的底层就是一个Hashtable,但是程序中也没有使用太多Properties对象,所以为什么那么多Hashtable$Entry对象,也暂时不知道了

总结问题:主要还是之前系统设计不合理导致锁表,代码编写不规范,导致程序内存过高的问题;
在这里总结分析一下,如果有不对的地方,欢迎指出;