奇异值分解SVD与PCA
首先:奇异值分解是一个有着很明显的物理意义的一种方法,它可以将一个比较复杂的矩阵用更小更简单的几个子矩阵的相乘来表示,这些小矩阵描述的是矩阵的重要的特性。
1. 奇异值与特征值基础知识
特征值分解和奇异值分解的目的都是一样,就是提取出一个矩阵最重要的特征。
1.1 特征值
如果说一个向量v是方阵A的特征向量,将一定可以表示成下面的形式:
这时候λ就被称为特征向量v对应的特征值,一个矩阵的一组特征向量是一组正交向量。特征值分解是将一个矩阵分解成下面的形式:
其中Q是这个矩阵A的特征向量组成的矩阵,Σ是一个对角阵,每一个对角线上的元素就是一个特征值。其实一个矩阵其实就是一个线性变换,因为一个矩阵乘以一个向量后得到的向量,其实就相当于将这个向量进行了线性变换。
- 比如说下面的一个对称矩阵:
M=[3001]
矩阵M乘以一个向量(x,y)的结果是:
[3001][xy]=[3xy]
上面的矩阵是对称的,所以这个变换是一个对x,y轴的方向一个拉伸变换(每一个对角线上的元素将会对一个维度进行拉伸变换,当值>1时,是拉长,当值<1时时缩短)。 - 当矩阵不是对称的时候,假如说矩阵是下面的样子:
M=[1011]
这其实是在平面上的一个主要方向进行的拉伸变换(变化方向可能有不止一个),想要描述好一个变换,那就描述好这个变换主要的变化方向。反过头来看看之前特征值分解的式子,分解得到的 Σ 矩阵是一个对角阵,里面的特征值是由大到小排列的,这些特征值所对应的特征向量就是描述这个矩阵变化方向(从主要的变化到次要的变化排列),但此处要注意的是特征值分解时变换的矩阵必须是方阵。
1.2 奇异值
特征值分解是一个提取矩阵特征很不错的方法,但是它只是对方阵而言的,在现实的世界中,我们看到的大部分矩阵都不是方阵,奇异值分解可以用来干这个事情,奇异值分解是一个能适用于任意的矩阵的一种分解的方法:
- 假设A是一个 N∗M 的矩阵,那么得到的U是一个 N∗N 的方阵(里面的向量是正交的, U 里面的向量称为左奇异向量), Σ 是一个 N∗M 的矩阵(除了对角线的元素都是0,对角线上的元素称为奇异值), VT (V的转置)是一个 N∗N 的矩阵,里面的向量也是正交的, V 里面的向量称为右奇异向量)。
- 矩阵 Σ 中也是从大到小排列,而且奇异值的减少特别的快,在很多情况下,前10%甚至1%的奇异值的和就占了全部的奇异值之和的99%以上了。也就是说,我们也可以用前r大的奇异值来近似描述矩阵。
从下图可以反映几个相乘的矩阵:
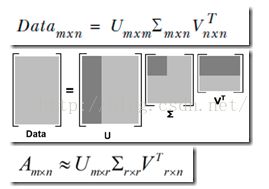
最下面右边的三个矩阵相乘的结果将会是一个接近于A的矩阵,在这儿,r越接近于n,则相乘的结果越接近于A。而这三个矩阵的占用存储远小于原始的矩阵A,比如:原始矩阵 10∗8=80 ,而奇异值分解后: 10∗2+2∗2+2∗8=40 ,可以看出压缩了一半。
2. PCA的数学原理
这里我想把PCA 的理论精要的做个笔记:
PCA(Principal Component Analysis)是一种常用的数据分析方法。PCA通过线性变换将原始数据变换为一组各维度线性无关的表示,可用于提取数据的主要特征分量,常用于高维数据的降维。
2.1 数据的向量表示及降维问题
一般情况下,在数据挖掘和机器学习中,数据被表示为向量。注意这里用的是转置,因为习惯上使用列向量表示一条记录。
降维的朴素思想很容易理解,但并不具有操作指导意义。例如,我们到底删除哪一列损失的信息才最小?亦或根本不是单纯删除几列,而是通过某些变换将原始数据变为更少的列但又使得丢失的信息最小?到底如何度量丢失信息的多少?如何根据原始数据决定具体的降维操作步骤?
要回答上面的问题,就要对降维问题进行数学化和形式化的讨论。而PCA是一种具有严格数学基础并且已被广泛采用的降维方法。下面我不会直接描述PCA,而是通过逐步分析问题。
2.2 向量的表示及基变换
既然我们面对的数据被抽象为一组向量,那么下面有必要研究一些向量的数学性质。
- 内积
两个维数相同的向量的内积被定义为:
(a1,a2,⋯,an)T⋅(b1,b2,⋯,bn)T=a1b1+a2b2+⋯+anbn
内积运算将两个向量映射为一个实数。其计算方式非常容易理解,下面我们分析内积的几何意义。假设A和B是两个n维向量,我们知道n维向量可以等价表示为n维空间中的一条从原点发射的有向线段,为了简单起见我们假设A和B均为二维向量,则 A=(x1,y1),B=(x2,y2) 。
现在我们从A点向B所在直线引一条垂线。我们知道垂线与B的交点叫做A在B上的投影,再设A与B的夹角是a,如果我们将内积表示为另一种我们熟悉的形式:
A⋅B=|A||B|cos(α)
A与B的内积等于A到B的投影长度乘以B的模。再进一步,如果我们假设B的模为1,即让 |B|=1 ,那么就变成了:
A⋅B=|A|cos(a)
也就是说,设向量B的模为1,则A与B的内积值等于A向B所在直线投影的矢量长度!这就是内积的一种几何解释。
2.3 基
在代数表示方面,我们经常用线段终点的点坐标表示向量,例如上面的向量可以表示为(3,2),这是我们再熟悉不过的向量表示。
不过我们常常忽略,只有一个 (3,2) 本身是不能够精确表示一个向量的。我们仔细看一下,这里的3实际表示的是向量在x轴上的投影值是3,在y轴上的投影值是2。也就是说我们其实隐式引入了一个定义:以x轴和y轴上正方向长度为1的向量为标准。那么一个向量 (3,2) 实际是说在x轴投影为3而y轴的投影为2。注意投影是一个矢量,所以可以为负。
更正式的说,向量(x,y)实际上表示线性组合:
不难证明所有二维向量都可以表示为这样的线性组合。此处(1,0)和(0,1)叫做二维空间中的一组基。
所以,要准确描述向量,首先要确定一组基,然后给出在基所在的各个直线上的投影值,就可以了。只不过我们经常省略第一步,而默认以 (1,0) 和 (0,1) 为基。
这里之所以默认选择 (1,0) 和 (0,1) 为基,当然是比较方便,因为它们分别是x和y轴正方向上的单位向量,因此就使得二维平面上点坐标和向量一一对应,非常方便。但实际上任何两个线性无关的二维向量都可以成为一组基,所谓线性无关在二维平面内可以直观认为是两个不在一条直线上的向量。
(1,1) 和 (−1,1) 也可以成为一组基。一般来说,我们希望基的模是1,因为从内积的意义可以看到,如果基的模是1,那么就可以方便的用向量点乘基而直接获得其在新基上的坐标了!实际上,对应任何一个向量我们总可以找到其同方向上模为1的向量,只要让两个分量分别除以模就好了。例如,上面的基可以变为 (12√,12√) 和
(−12√,12√)
现在,我们想获得 (3,2) 在新基上的坐标,即在两个方向上的投影矢量值,那么根据内积的几何意义,我们只要分别计算(3,2)和两个基的内积,不难得到新的坐标为 (52√,−12√) 。
另外这里要注意的是,我们列举的例子中基是正交的(即内积为0,或直观说相互垂直),但可以成为一组基的唯一要求就是线性无关,非正交的基也是可以的。不过因为正交基有较好的性质,所以一般使用的基都是正交的。
2.4 基变换的矩阵表示
下面我们找一种简便的方式来表示基变换。还是拿上面的例子,想一下,将 (3,2) 变换为新基上的坐标,就是用 (3,2) 与第一个基做内积运算,作为第一个新的坐标分量,然后用 (3,2) 与第二个基做内积运算,作为第二个新坐标的分量。实际上,我们可以用矩阵相乘的形式简洁的表示这个变换:
其中矩阵的两行分别为两个基,乘以原向量,其结果刚好为新基的坐标,可以以此推广下去。
一般的,如果我们有M个N维向量,想将其变换为由R个N维向量表示的新空间中,那么首先将R个基按行组成矩阵A,然后将向量按列组成矩阵B,那么两矩阵的乘积AB就是变换结果,其中AB的第m列为A中第m列变换后的结果。
数学表示为:
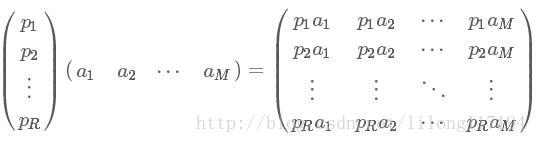
其中 pi 是一个行向量,表示第i个基, aj 是一个列向量,表示第j个原始数据记录。
特别要注意的是,这里R可以小于N,而R决定了变换后数据的维数。也就是说,我们可以将一N维数据变换到更低维度的空间中去,变换后的维度取决于基的数量。因此这种矩阵相乘的表示也可以表示降维变换。
最后,上述分析同时给矩阵相乘找到了一种物理解释:两个矩阵相乘的意义是将右边矩阵中的每一列列向量变换到左边矩阵中每一行行向量为基所表示的空间中去。更抽象的说,一个矩阵可以表示一种线性变换。在学线性代数时对矩阵相乘的方法感到奇怪,但是如果明白了矩阵相乘的物理意义,其合理性就一目了然了。
2.5 协方差矩阵及优化目标
上面我们讨论了选择不同的基可以对同样一组数据给出不同的表示,而且如果基的数量少于向量本身的维数,则可以达到降维的效果。但是我们还没有回答一个最最关键的问题:如何选择基才是最优的。或者说,如果我们有一组N维向量,现在要将其降到K维(K小于N),那么我们应该如何选择K个基才能最大程度保留原有的信息?
这里我们用一种非形式化的直观方法来看这个问题:
为了避免过于抽象的讨论,我们仍以一个具体的例子展开。假设我们的数据由五条记录组成,将它们表示成矩阵形式:
其中每一列为一条数据记录,而一行为一个字段。为了后续处理方便,我们首先将每个字段内所有值都减去字段均值,其结果是将每个字段都变为均值为0。
得到:
如果我们必须使用一维来表示这些数据,又希望尽量保留原始的信息,你要如何选择?
通过上一节对基变换的讨论我们知道,这个问题实际上是要在二维平面中选择一个方向,将所有数据都投影到这个方向所在直线上,用投影值表示原始记录。这是一个实际的二维降到一维的问题。
那么如何选择这个方向(或者说基)才能尽量保留最多的原始信息呢?一种直观的看法是:希望投影后的投影值尽可能分散。
2.6 方差
我们希望投影后投影值尽可能分散,而这种分散程度,可以用数学上的方差来表述。此处,一个字段的方差可以看做是每个元素与字段均值的差的平方和的均值,即:
由于上面我们已经将每个字段的均值都化为0了,因此方差可以直接用每个元素的平方和除以元素个数表示:
于是上面的问题被形式化表述为:寻找一个一维基,使得所有数据变换为这个基上的坐标表示后,方差值最大。
2.7 协方差
最终要达到的目的与字段内方差及字段间协方差有密切关系。因此我们希望能将两者统一表示,仔细观察发现,两者均可以表示为内积的形式,而内积又与矩阵相乘密切相关。于是假设我们只有a和b两个字段,那么我们将它们按行组成矩阵X:
然后我们用X乘以X的转置,并乘上系数 1m :
这个矩阵对角线上的两个元素分别是两个字段的方差,而其它元素是a和b的协方差。两者被统一到了一个矩阵的。
根据矩阵相乘的运算法则,这个结论很容易被推广到一般情况:
设我们有m个n维数据记录,将其按列排成n乘m的矩阵X,设 C=1mXXTC ,则C是一个对称矩阵,其对角线分别个各个字段的方差,而第i行j列和j行i列元素相同,表示i和j两个字段的协方差。
2.8 协方差矩阵对角化
根据上述推导,我们发现要达到优化目前,等价于将协方差矩阵对角化:即除对角线外的其它元素化为0,并且在对角线上将元素按大小从上到下排列,这样我们就达到了优化目的。进一步看下原矩阵与基变换后矩阵协方差矩阵的关系:
设原始数据矩阵X对应的协方差矩阵为C,而P是一组基按行组成的矩阵,设Y=PX,则Y为X对P做基变换后的数据。设Y的协方差矩阵为D,我们推导一下D与C的关系:
此时可以看出:
我们要找的P不是别的,而是能让原始协方差矩阵对角化的P。换句话说,优化目标变成了寻找一个矩阵P,满足 PCPT 是一个对角矩阵,并且对角元素按从大到小依次排列,那么P的前K行就是要寻找的基,用P的前K行组成的矩阵乘以X就使得X从N维降到了K维并满足上述优化条件。
现在所有焦点都聚焦在了协方差矩阵对角化问题上,这在数学上根本不是问题。由上文知道,协方差矩阵C是一个是对称矩阵,在线性代数上,实对称矩阵有一系列非常好的性质:
- 实对称矩阵不同特征值对应的特征向量必然正交。
- 设特征向量λ重数为r,则必然存在r个线性无关的特征向量对应于λλ,因此可以将这r个特征向量单位正交化。
由上面两条可知,一个n行n列的实对称矩阵一定可以找到n个单位正交特征向量,设这n个特征向量为 e1,e2,⋯,en ,我们将其按列组成矩阵:
则对协方差矩阵C有如下结论:
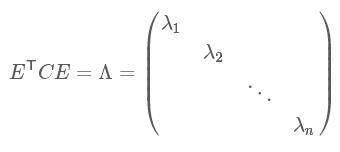
到这里,我们发现我们已经找到了需要的矩阵P:
P是协方差矩阵的特征向量单位化后按行排列出的矩阵,其中每一行都是C的一个特征向量。如果设P按照 Λ 中特征值的从大到小,将特征向量从上到下排列,则用P的前K行组成的矩阵乘以原始数据矩阵X,就得到了我们需要的降维后的数据矩阵Y。
3. 奇异值与主成分分析(PCA)
这里主要谈谈如何用SVD去解PCA的问题:
3.1 PCA
PCA的问题其实是一个基的变换,使得变换后的数据有着最大的方差。方差的大小描述的是一个变量的信息量,我们在讲一个东西的稳定性的时候,往往说要减小方差,如果一个模型的方差很大,那就说明模型不稳定了。但是对于用于机器学习的数据(主要是训练数据),方差大才有意义,不然输入的数据都是同一个点,那方差就为0了,这样输入的多个数据就等同于一个数据了。以下面这张图为例子:
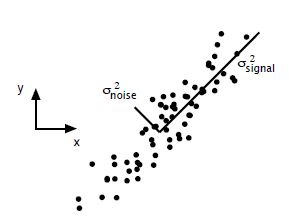
假如我们想要用一条直线去拟合这些点,那我们会选择什么方向的线呢?当然是图上标有signal的那条线。如果我们把这些点单纯的投影到x轴或者y轴上,最后在x轴与y轴上得到的方差是相似的(因为这些点的趋势是在45度左右的方向,所以投影到x轴或者y轴上都是类似的),如果我们使用原来的xy坐标系去看这些点,容易看不出来这些点真正的方向是什么。但是如果我们进行坐标系的变化,横轴变成了signal的方向,纵轴变成了noise的方向,则就很容易发现什么方向的方差大,什么方向的方差小了。
一般来说,方差大的方向是信号的方向,方差小的方向是噪声的方向,我们在数据挖掘中或者数字信号处理中,往往要提高信号与噪声的比例,也就是信噪比。对上图来说,如果我们只保留signal方向的数据,也可以对原数据进行不错的近似了。
PCA的全部工作简单点说,就是对原始的空间中顺序地找一组相互正交的坐标轴,第一个轴是使得方差最大的,第二个轴是在与第一个轴正交的平面中使得方差最大的,第三个轴是在与第1、2个轴正交的平面中方差最大的,这样假设在N维空间中,我们可以找到N个这样的坐标轴,我们取前r个去近似这个空间,这样就从一个N维的空间压缩到r维的空间了,但是我们选择的r个坐标轴能够使得空间的压缩使得数据的损失最小。
这就是机器学习实战中PCA的移动坐标轴的原理。
3.2 SVD
假设我们矩阵每一行表示一个样本,每一列表示一个feature,将一个m * n的矩阵A变换成一个m * r的矩阵,这样就会使得本来有n个feature的,变成了有r个feature了(r < n),这r个其实就是对n个feature的一种提炼,我们就把这个称为feature的压缩。用数学语言表示就是:
SVD得出的奇异向量也是从奇异值由大到小排列的,按PCA的观点来看,就是方差最大的坐标轴就是第一个奇异向量,方差次大的坐标轴就是第二个奇异向量…
和之前得到的SVD式子对比:
在矩阵的两边同时乘上一个矩阵 V ,由于 V 是一个正交的矩阵,所以 VTV=I ,所以可以化成后面的式子:
这里是将一个 m∗n 的矩阵压缩到一个 m∗r 的矩阵,也就是对列进行压缩,如果我们想对行进行压缩,类似于列压缩的形式,只需在 Am×n≈Um×rΣr×rVTr×n 两边左乘 UT , 这样就得到了对行进行压缩的式子。可以看出,其实PCA几乎可以说是对SVD的一个包装,如果我们实现了SVD,那也就实现了PCA了,而且更好的地方是,有了SVD,我们就可以得到两个方向的PCA,如果我们对 ATA 进行特征值的分解,只能得到一个方向的PCA。
参考:
https://www.cnblogs.com/LeftNotEasy/archive/2011/01/19/svd-and-applications.html
http://blog.codinglabs.org/articles/pca-tutorial.html