spark 读取 Oracle 以及 kafka 数据 ( GeoPoint 坐标数据类型 ) 做Join 并插入ES 【原创】
一、kafka 模拟数据:
【1】模拟数据实体类:
public class CarDataTest {
private String lat;
private String lon;
private String location;
private String status;
private String terminaltype;
-------有很多字段 此处省略不写了 下面 get set 也省略不写了------
public String getRecordvelocity() {
return recordvelocity;
}
public void setRecordvelocity(String recordvelocity) {
this.recordvelocity = recordvelocity;
}
public String getDepid() {
return depid;
}
public void setDepid(String depid) {
this.depid = depid;
}
}【2】kafka 生成模拟数据
public class kafkaTest {
private static String carrDatas(){
CarDataTest carDataTest = new CarDataTest();
String randomNum_10 = String.valueOf(new Random().nextInt(9));
String randomNum_100 = String.valueOf(new Random().nextInt(100));
String randomNum_1 = String.valueOf(new Random().nextInt(2));
long end = System.currentTimeMillis();
Date date = new Date(end);
SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String dateStr = df.format(date);
carDataTest.setLat("23.111111");
carDataTest.setLon("113.112233");
carDataTest.setLocation("23.111111,113.22222");
--------------省略部分-----------
carDataTest.setSvrtime(dateStr);
carDataTest.setTerminaltype(randomNum_1);
JSONObject object = JSONObject.fromObject(carDataTest);
String json = object.toString();
System.out.println(json);
return json;
}
public static void main (String args[]) throws Exception{
/**
kafka 序列化 相关类指定
*/
String serializerClassName = "org.apache.kafka.common.serialization.StringSerializer";
/**
kafka 的 bootsServers 没啥好说的
*/
String kafkaBootsrapServers ="machen1:9092,machen2:9092,machen3:9092";
/**
构建 kafka 相关参数
*/
Properties properties = new Properties();
properties.put("bootstrap.servers",kafkaBootsrapServers);
properties.put("acks","all");
properties.put("retries",0);
properties.put("batch.size",16384);
properties.put("linger.ms",1);
properties.put("buffer.memory",33554432);
properties.put("key.serializer" ,serializerClassName);
properties.put("value.serializer",serializerClassName);
KafkaProducer kafkaProducer = new KafkaProducer(properties);
/**
指定topic
*/
String topic = "police_data_test";
boolean flag = true;
while( flag){
for(int i=0;i<5;i++){
kafkaProducer.send(
new ProducerRecord(
topic,
carrDatas()
));
}
kafkaProducer.flush();
System.out.println(" machen kafka 生成数据完毕");
Thread.sleep(10000);
}
kafkaProducer.close();
}
} 二、spark 读取【oracle 和 kafka】数据 并插入 ES
【1】ES 索引创建
首先解释一下 type 的类型,date ,keyword,folat 没什么好说的
geo_point 是 Geopoint 的类型 是ES 用于空间查询的一种类型
一定要注意、一定要注意、一定要注意、
geopoint 的 格式 为 “lat,lon” 分别代表 维度和经度 比如说 “23.33445,113.223214” 第一个数字的小数点前面是 两位数,第二个数字的小数点前面是3位数 ,否则是插不进去ES的 ,而且会一直报 非常诡异的错误 :
(我之前一直插不进去就是不小心 写成 “113.22222,23.22222” 这种错误形式了)
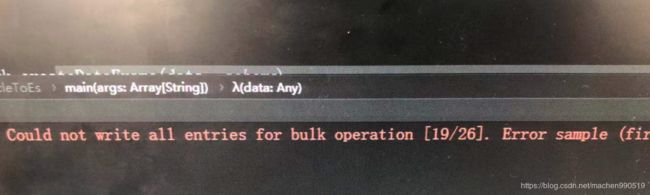
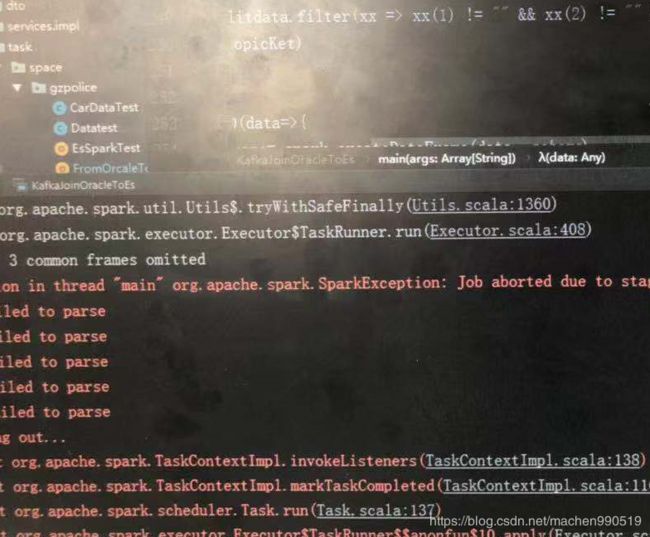
反正日志中你看不到任何关于 geopoint 的格式错误的提示
他的值是 有 "lat" 和 "lon" 组合而成,也就是经纬度的表达
PUT test_police_car
{
"mapping":{
"doc":{
"properties":{
"lat":{
"type":"float"
},
"lon":{
"type":"float"
},
"location":{
"type":"geo_point"
},
"rectime":{
"type":"date"
},
"address":{
"type":"keyword"
},
"name":{
"type":"machen"
}
}
}
}
}【2】索引表结构展示:
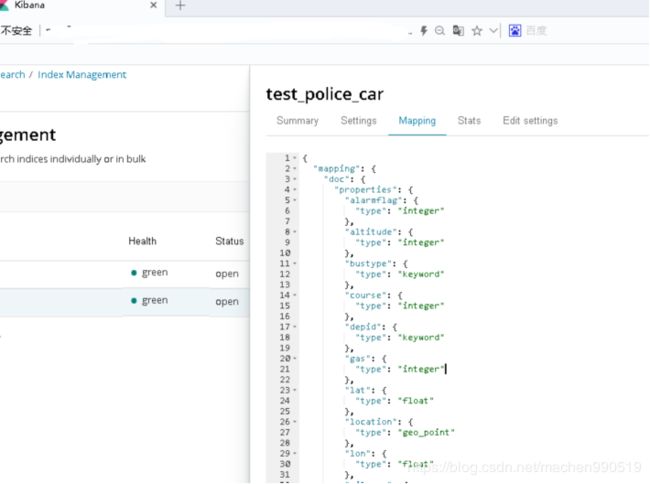
关闭 表限制:
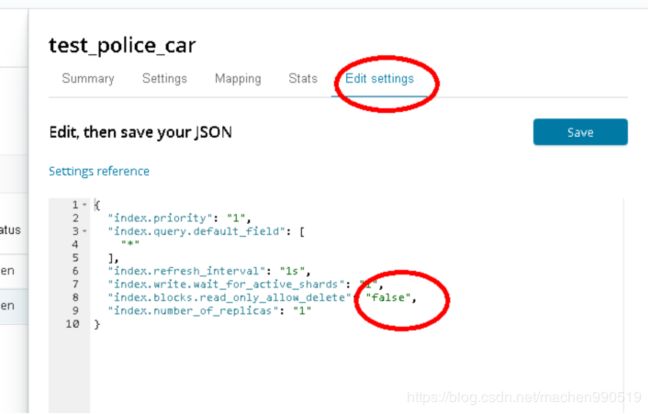
【3】插入数据
object FromOrcaleToEs {
/**
* spark 的配置 包括链接ES 的一些参数设定
* 主要注意点: 设置序列化的类 spark.serializer
*/
val sparkConf = new SparkConf().setAppName("machen_work_test").setMaster("local[2]")
sparkConf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
sparkConf.set("cluster.name","es")
// 原创链接---
sparkConf.set("es.index.auto.create","true")
sparkConf.set("es.nodes","machen1,machen2,machen3")
sparkConf.set("es.port","9200")
sparkConf.set("es.index.read.missing.as.empty","true")
sparkConf.set("es.nodes.wan.only","true")
/**
* Oracle 参数设定
*/
val property = new Properties()
property.put("user","XXXX")
property.put("password", "yyyy")
property.put("driver", "oracle.jdbc.OracleDriver")
val oracle_url = "jdbc:oracle:thin:@172.0.0.0:1521/datat_machen"
val schema = StructType(Seq(
StructField("lat",StringType,true),
StructField("lon",StringType,true),
StructField("location",StringType,true),
-------- 省略部分 ---------
StructField("recordvelocity",StringType,true),
StructField("depid",StringType,true)
))
//kafka
def getKafkaData(topic: String, broker: String, scc: StreamingContext) = {
val topicMap: Set[String] = List(topic).toSet
val kafkaParam: Map[String, Object] = getKafkaParam(broker)
val data = KafkaUtils.createDirectStream[String, String](scc,
PreferConsistent,
Subscribe[String, String](topicMap, kafkaParam)
)
data
}
def getKafkaParam(broker: String) = {
val kafkaParam = Map[String, Object](
"bootstrap.servers" -> broker,
"group.id" -> "console-consumer-oracl-001",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"enable.auto.commit" -> (false: java.lang.Boolean),
"auto.offset.reset" -> "latest",// latest , earliest
// "security.protocol" -> "SASL_PLAINTEXT",
// "sasl.mechanism" -> "PLAIN",
"max.poll.records"->"5"
)
kafkaParam
}
/**
* ES 中的时间格式 都知道 是时区时间 也就是说表面上要比真实时间少 8个小时
* 因此要把 准备插入的时间数据(String 类型)(比如说 2019-10-11 18:09:09)先变成ES 时间再插入
* 即 减去8小时 ,再转换成时区格式 (2019-10-11T10:09:09.000Z)。
* 注意点:这是对于数据是 String 类型的,如果时间是Date 类型 直接插入(比如果用ES 自己的API
* 或是kibana 方式的话 是没有必要转化的 直接插入就行)
*/
def dateForES (initdate:String) ={
val initdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
val time = initdf.parse(initdate).getTime-8*60*60*1000
val estimedf = new SimpleDateFormat("yyyy-MM-dd'T'HH:mm:ss.SSS'Z'")
val newtime = estimedf.format(new Date(time))
newtime
}
def main(args: Array[String]): Unit = {
val conf = sparkConf
val sc = new SparkContext(conf)
val spark = SparkSession
.builder
.master("local[2]")
.appName("From_oracle")
.config(sparkConf)
.getOrCreate()
val ssc = new StreamingContext(sc,Seconds(10))
//oracle 数据 转成 DF
val jdbcdata = spark.read.jdbc(oracle_url,"my_oracle.test_data",property)
jdbcdata.registerTempTable("orc_data")
val oracle_data:DataFrame = spark.sql("select simno,plateno from orc_data limit 2")
println("测试 oracle 数据:"+oracle_data.show())
//kafka 数据 转成 DF
val topic = "police_data_test"
val broker = "machen1:9092,machen2:9092,machen3:9092"
val lines = getKafkaData(topic,broker,ssc)
lines.foreachRDD(rdd => {
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
lines.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)
})
lines.foreachRDD{ rdd =>
val data:RDD[Row] = rdd.map { x =>
val buffer = ArrayBuffer.empty[Any]
val jsons = JSONObject.fromObject(x.value())
println(jsons)
buffer.append(jsons.getString("lat"))
buffer.append(jsons.getString("lon"))
buffer.append(jsons.getString("location"))
--------省略部分---------------
buffer.append(dateForES(jsons.getString("rectime")))
buffer.append(jsons.getString("depid"))
println("转换完毕---------")
Row.fromSeq(buffer)
}
val df :DataFrame = spark.createDataFrame(data,schema)
df.registerTempTable("kafka_data")
val joindata = spark.sql("select k.*,o.plateno from kafka_data as k join orc_data as o on k.simid=o.simid ")
val jsonArray = new JSONArray()
val rddData = joindata.toJSON.rdd
println("准备插入--------------------------------------------------")
EsSpark.saveJsonToEs(rddData,"test_police_car/doc")
println("插入成功--------------------------------------------------")
joindata.show()
}
/** 第二种方式:
* 上面是先行 forechRDD 然后再map 操作 ,在map操作时候,已经是rdd 的类型了
* 所以只能用 EsSpark.saveJsonToEs
* 如果 先用 map 那么返回的还是 Dstream[] 再用下面即可 x.value() 是json 格式
* val json = lines.map(x=>{
* val jsons = JSONObject.fromObject(x.value())
* jsons
* })
* EsSparkStreaming.saveJsonToEs(json,"index")
*/
ssc.start()
ssc.awaitTermination()
ssc.stop()
}
}【4】运行 相关的日志输出:
kafka 数据
测试类日志:【相关真实数据不方便暴漏,请理解】
join 之后的 df 【太长了,只展示后面字段】
ES 数据再次查询:
能看到join 之后,并且插入的数据 (数据不方便暴漏 请理解)