论文翻译-RetinaFace
这篇论文是今年5月4号发表的一篇关于人脸检测的研究,他在WIDER FACE上的可以识别出像素级别的人脸,可以说已经很厉害了!WIDER FACE 几乎是目前评估人脸检测算法最权威的数据集,WIDER FACE数据集是由香港中文大学发布的大型人脸数据集,含32,203幅图像和393,703个高精度人脸包围框,该库中人脸包含尺度、姿态、表情、遮挡和光照等变化。
paper链接:https://arxiv.org/pdf/1905.00641.pdf
github地址:https://github.com/deepinsight/insightface/tree/master/RetinaFace
RetinaFace: Single-stage Dense Face Localisation in the Wild
译:RetinaFace:户外稠密图像的单体人脸检测
摘要:
Though tremendous strides have been made in uncontrolled face detection, accurate and efficient face localisation in the wild remains an open challenge. This paper presents a robust single-stage face detector, named RetinaFace, which performs pixel-wise face localisation on various scales of faces by taking advantages of joint extra-supervised and self-supervised multi-task learning.Specifically, We make contributions in the following five aspects: (1) We manually annotate five facial landmarks on the WIDER FACE dataset and observe significant improvement in hard face detection with the assistance of this extra supervision signal. (2) We further add a selfsupervised mesh decoder branch for predicting a pixel-wise 3D shape face information in parallel with the existing supervised branches. (3) On the WIDER FACE hard test set,RetinaFace outperforms the state of the art average precision (AP) by 1.1% (achieving AP equal to 91.4%). (4) On the IJB-C test set, RetinaFace enables state of the art methods (ArcFace) to improve their results in face verification (TAR=89.59% for FAR=1e-6). (5) By employing light weight backbone networks, RetinaFace can run real-time on a single CPU core for a VGA-resolution image. Extra annotations and code have been made available at: https://github.com/deepinsight/insightface/tree/master/RetinaFace.
译:
尽管现在在不受控人脸检测方向已经取得了重大的进步,但在户外准确有效的面部定位仍然是一个开放性问题。这篇论文提出了一个强大的单级人脸检测器,叫作RetinaFace,它利用结合了超级监督和自我监督的多任务学习,在各种不同的人脸上执行像素级别的人脸定位。具体来说,我们在以下5个方面做出了贡献:
(1)我们在WIDER FACE数据集上手动注释五个面部标志,并在这个额外的监督信号的帮助下观察困难级人脸检测的重要改进。
(2)我们进一步增加了一个自监督网格解码器分支,用于与现有的监督分支并行地预测一个像素级三维的面部信息。
(3)在WIDER FACE困难测试集上,RetinaFace的性能优于现有技术平均预测(AP)1.1%(达到AP等于91.4%)。
(4)在IJB-C测试集上,RetinaFace使最先进的技术(ArcFace)提升了它们在脸部验证的结果(FAR=1e-6的情况下TAR=89.59%)。
(5)通过使用轻量级骨干网络,RetinaFace可以在单个CPU内核上实时运行,以实现VGA(视频图形阵列)分辨率的图像显示。
获取额外的图像注释和代码请上:
https://github.com/deepinsight/insightface/tree/master/RetinaFace
1.介绍
Automatic face localisation is the prerequisite step of facial image analysis for many applications such as facial attribute (e.g. expression [64] and age [38]) and facial identity recognition [45, 31, 55, 11]. A narrow definition of face localisation may refer to traditional face detection [53, 62],which aims at estimating the face bounding boxes without any scale and position prior. Nevertheless, in this paper we refer to a broader definition of face localisation which includes face detection [39], face alignment [13], pixelwise face parsing [48] and 3D dense correspondence regression [2, 12]. That kind of dense face localisation provides accurate facial position information for all different scales.
译:
自动面部定位是许多应用程序(例如面部特征(例如表情和年龄)和面部识别)的面部图像分析的前提步骤。人脸识别的狭义定义可能是指传统的人脸检测,其目的是估测一个事先不知道大小和位置的脸的脸部边界框。然而,在这篇论文,我们指的是人脸识别更广泛的定义,其中包括人脸检测、人脸对齐、像素级人脸分析和密集型图片对应3D场景的复原。这种密集的脸部定位可以为所有不同规格的场景图片提供准确的脸部位置信息。
Inspired by generic object detection methods [16, 43, 30,41, 42, 28, 29], which embraced all the recent advances in deep learning, face detection has recently achieved remarkable progress [23, 36, 68, 8, 49]. Different from generic object detection, face detection features smaller ratio variations (from 1:1 to 1:1.5) but much larger scale variations (from several pixels to thousand pixels). The most recent state-of-the-art methods [36, 68, 49] focus on singlestage [30, 29] design which densely samples face locations and scales on feature pyramids [28], demonstrating promising performance and yielding faster speed compared to twostage methods [43, 63, 8]. Following this route, we improve the single-stage face detection framework and propose a state-of-the-art dense face localisation method by exploiting multi-task losses coming from strongly supervised and self-supervised signals. Our idea is examplified in Fig. 1.
译:
受到常规目标检测方法的启发(包括深度学习的最新进展),人脸识别最近已经取得了非常显著的进步。与常规目标检测不同,人脸识别中人脸特征的比率变化较小(从1:1到1:1.5),但是人脸大小变化却很大(从几像素到几千像素)。最新的技术方法集中在单阶段设计上,该阶段在特征金字塔上密集地采样脸部位置和大小,与两阶段方法相比,展现出良好的性能并产生更快的速度。根据这个路线,我们改进了单阶段人脸检测框架并且通过利用来自强监督和自监督信号的多任务损失,提出了一种最新的密集人脸定位方法。我们的想法在图1中得到体现。
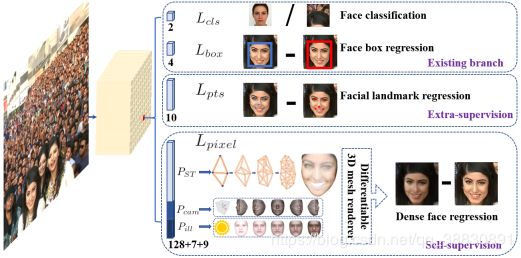
图1:提出的单级逐像素人脸定位方法与现有盒子分类与回归分支并行地采用额外监督和自监督的多任务学习。每个正锚定输出:1)人脸分数(2)人脸框(3)五个人脸定位标记点(4)投影在影像平面上的密集3D人脸顶点
Typically, face detection training process contains both classification and box regression losses [16]. Chen et al. [6] proposed to combine face detection and alignment in a joint cascade framework based on the observation that aligned face shapes provide better features for face classification.Inspired by [6], MTCNN [66] and STN [5] simultaneously detected faces and five facial landmarks. Due to training data limitation, JDA [6], MTCNN [66] and STN [5] have not verified whether tiny face detection can benefit from the extra supervision of five facial landmarks. One of the questions we aim at answering in this paper is whether we can push forward the current best performance (90.3% [67]) on the WIDER FACE hard test set [60] by using extra supervision signal built of five facial landmarks.
译:
通常,人脸检测训练过程包括分类损失和框回归损失。基于观察到对齐的面部形状为面部分类可以提供更好的特征,chen等人提议在联合级联框架中结合人脸检测和对齐。受到这一启发,MTCNN和STN同时检测脸部和脸部上的五个特征点。由于训练数据的限制,JDA、MTCNN、STN并没有验证出微小脸部的检测是否可以从五个面部特征点的额外监督中受益。我们在本文想要回答的一个问题是我们是否可以通过由五个面部标志构成的额外监督标记提升在WIDER FACE困难数据集上目前最优的性能(90.3%)。
In Mask R-CNN [20], the detection performance is significantly improved by adding a branch for predicting an object mask in parallel with the existing branch for bounding box recognition and regression. That confirms that dense pixel-wise annotations are also beneficial to improve detection. Unfortunately, for the challenging faces of WIDER FACE it is not possible to conduct dense face annotation (either in the form of more landmarks or semantic segments). Since supervised signals cannot be easily obtained,the question is whether we can apply unsupervised methods to further improve face detection
译:
在Mask R-CNN中,通过在现有的边界框识别和回归分支上添加一条用于预测遮掩物体的分支,从而显着提高了检测性能。这证实了密集像素级的标注也是有利于检测性能的提升。遗憾的是,对于WIDER FACE中具有挑战性的脸部图片,可能无法进行密集的人脸注释(在更多标记的形式或语义段上)。由于无法轻易的获取监督标记,所以现在的问题是是否可以使用非监督的方法去进一步改善检测性能。
In FAN [56], an anchor-level attention map is proposed to improve the occluded face detection. Nevertheless, the proposed attention map is quite coarse and does not contain semantic information. Recently, self-supervised 3D morphable models [14, 51, 52, 70] have achieved promising 3D face modelling in-the-wild. Especially, Mesh Decoder [70] achieves over real-time speed by exploiting graph convolutions [10, 40] on joint shape and texture. However, the main challenges of applying mesh decoder [70] into the single-stage detector are: (1) camera parameters are hard to estimate accurately, and (2) the joint latent shape and texture representation is predicted from a single feature vector (1 × 1 Conv on feature pyramid) instead of the RoI pooled feature, which indicates the risk of feature shift. In this paper, we employ a mesh decoder [70] branch through self-supervision learning for predicting a pixel-wise 3D face shape in parallel with the existing supervised branches.
译: