SparkStreaming与Kafka集成
官方文档参考:http://spark.apache.org/docs/2.2.2/
1、概述
Spark Streaming是核心Spark API的扩展,可实现实时数据流的可扩展,高吞吐量,容错流处理。数据可以从许多来源(如Kafka,Flume,Kinesis或TCP套接字)中获取,并且可以使用以高级函数表示的复杂算法进行处理map,例如reduce,join和window。最后,处理后的数据可以推送到文件系统,数据库和实时仪表板。

2、案例分析
演示SparkStreaming如何从Kafka读取消息,如果通过连接池方法把消息处理完成后再写回给Kafka 。
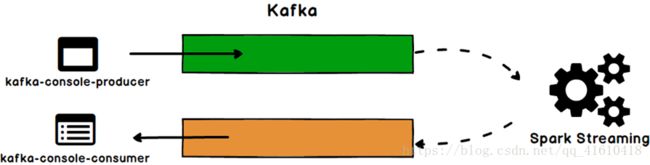
①pom.xml引入整合包依赖
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming-kafka-0-10_2.11artifactId>
<version>${spark.version}version>
dependency>②代码解析
import org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.kafka.clients.producer.{Producer, ProducerRecord}
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object DataKafka2SparkStreaming extends App {
//创建配置对象
val conf = new SparkConf().setAppName("kafka_spark").setMaster("local[2]")
//创建StreamingContext操作对象
val ssc = new StreamingContext(conf,Seconds(5))
//获取Kafka生产数据的主题
val fromTopic = "source"
//获取Kafka消费数据的主题
val toTopic = "target"
//创建brokers的地址
val brokers = "master:9092,slave1:9092,slave2:9092"
//创建kafka连接需要的参数配置
val kafkaParams = Map[String,Object](
//用于初始化链接到集群的地址
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> brokers,
//key与value的反序列化类型
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer],
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> classOf[StringDeserializer],
//用于标识这个消费者属于哪个消费团体
ConsumerConfig.GROUP_ID_CONFIG -> "StreamingKafka",
//自动重置到最新的偏移量
ConsumerConfig.AUTO_OFFSET_RESET_CONFIG -> "latest"
)
//获取DStream
val dStream = KafkaUtils.createDirectStream(
ssc,//SparkStreaming操作对象
LocationStrategies.PreferConsistent,//位置策略:数据读取之后如何分布在各个分区上
ConsumerStrategies.Subscribe[String,String](Array(fromTopic),kafkaParams) //消费策略(订阅固定的主题集合)
)
//处理DStream的数据
val result = dStream.map(x => x.value()+"@@@")
//结果输出
result.print
//将结果输出到Kafka的另一个主题中
result.foreachRDD(rdd => {
//在这里将RDD写回Kafka,需要使用Kafka连接池
rdd.foreachPartition(items => {
val kafkaProxyPool = KafkaPool(brokers)
//生产者对象
val kafkaProxy = kafkaProxyPool.borrowObject()
for (item <- items){
//使用这个连接池
kafkaProxy.kafkaClient.send(new ProducerRecord[String,String](toTopic,item))
}
kafkaProxyPool.returnObject(kafkaProxy)
})
})
//启动
ssc.start()
ssc.awaitTermination()
}//Kafka连接池
import org.apache.commons.pool2.impl.{DefaultPooledObject, GenericObjectPool}
import org.apache.commons.pool2.{BasePooledObjectFactory, PooledObject}
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig}
import org.apache.kafka.common.serialization.StringSerializer
//将Scala的集合类型转换成Java的,需要导入此包
import scala.collection.JavaConversions._
object KafkaPool{
private var kafkaPool:GenericObjectPool[KafkaProxy] = null
def apply(brokers:String): GenericObjectPool[KafkaProxy] = {
if (kafkaPool == null){
this.kafkaPool = new GenericObjectPool[KafkaProxy](new KafkaProxyFactory(brokers))
}
kafkaPool
}
}
class KafkaProxy(brokers:String){
val conf = Map[String,Object](
//用于初始化链接到集群的地址
ProducerConfig.BOOTSTRAP_SERVERS_CONFIG -> brokers,
//key与value的序列化类型
ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG -> classOf[StringSerializer],
ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG -> classOf[StringSerializer]
)
val kafkaClient = new KafkaProducer[String,String](conf)
}
//创建一个创建KafkaProxy的工厂
class KafkaProxyFactory(brokers:String) extends BasePooledObjectFactory[KafkaProxy]{
//创建实例
override def create(): KafkaProxy = new KafkaProxy(brokers)
//包装实例
override def wrap(t: KafkaProxy): PooledObject[KafkaProxy] = new DefaultPooledObject[KafkaProxy](t)
}③启动Zookeeper
[root@master ~]# zkServer.sh start
[root@slave1 ~]# zkServer.sh start
[root@slave2 ~]# zkServer.sh start④启动Kafka
#后台启动 &
[root@master ~]# kafka-server-start.sh /opt/app/Kafka/kafka_2.11-2.0.0/config/server.properties &
[root@slave1 ~]# kafka-server-start.sh /opt/app/Kafka/kafka_2.11-2.0.0/config/server.properties &
[root@slave2 ~]# kafka-server-start.sh /opt/app/Kafka/kafka_2.11-2.0.0/config/server.properties &#创建生产数据的主题
[root@master ~]# kafka-topics.sh \
> --create \
> --zookeeper master:2181,slave1:2181,slave2:2181 \
> --replication-factor 2 \
> --partitions 2 \
> --topic source
#启动producer 写入数据到source
[root@master ~]# kafka-console-producer.sh \
> --broker-list master:9092,slave1:9092,slave2:9092 \
> --topic source#创建消费数据的主题
[root@slave1 ~]# kafka-topics.sh \
> --create \
> --zookeeper master:2181,slave1:2181,slave2:2181 \
> --replication-factor 2 \
> --partitions 2 \
> --topic target
#启动consumer 监听target的数据
[root@slave1 ~]# kafka-console-consumer.sh \
> --bootstrap-server master:9092,slave1:9092,slave2:9092 \
> --topic target