hadoop_mapreduce_wordcount例子
1. Wordcount例子
1) 数据流:

2) Map
Map需要派生自map,四个参数为k1,v1,k2,v2的数据类型
package com.harvetech.service;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
// k1 v1 k2 v2
public class WordCountMapper extends Mapper
@Override
protected void map(LongWritable k1, Text v1, Context context)
throws IOException, InterruptedException {
/*
* context代表Map的上下文
* 上文:HDFS
* 下文是:Reducer
*/
//数据: I love Beijing
String data = v1.toString();
//分词
String[] words = data.split(" ");
//输出: k2 v2
for(String w:words){
context.write(new Text(w), new LongWritable(1));
}
}
}
3) Reduce
Reduce类需要派生自reducer类,四个参数分别为k3,v3,k4,v4的类型
package com.harvetech.service;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
// k3 v3 k4 v4
public class WordCountReducer extends Reducer
@Override
protected void reduce(Text k3, Iterable
/*
* context 代表Reducer上下文
* 上文:mapper
* 下文:HDFS
*/
long total = 0;
for(LongWritable l:v3){
total = total + l.get();
}
//输出 k4 v4
context.write(k3, new LongWritable(total));
}
}
4) Main
在main方法中关联map和reduce创建job,
package com.harvetech.service;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountMain {
public static void main(String[] args) throws Exception {
//创建一个job = mapper + reducer
Job job = Job.getInstance(new Configuration());
//指定job的入口
job.setJarByClass(WordCountMain.class);
//指定任务的mapper和输出数据类型
job.setMapperClass(WordCountMapper.class);
job.setMapOutputKeyClass(Text.class); //指定k2的类型
job.setMapOutputValueClass(LongWritable.class);//指定v2的数据类型
//指定任务的reducer和输出数据类型
job.setReducerClass(WordCountReducer.class);
job.setOutputKeyClass(Text.class);//指定k4的类型
job.setOutputValueClass(LongWritable.class);//指定v4的类型
//指定输入的路径和输出的路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//执行任务
job.waitForCompletion(true);
}
}
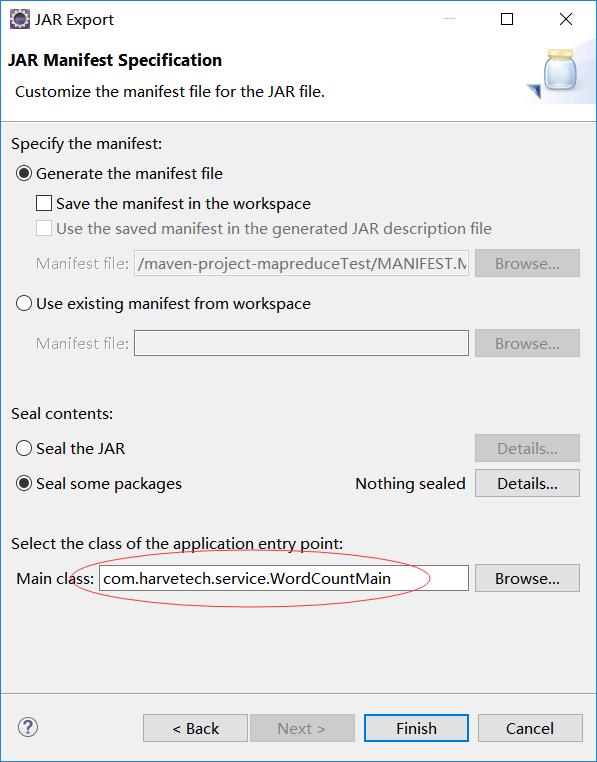
5) 打jar包
右键项目打jar包,第一二步默认,第三步选择执行的main方法类:
6) 执行
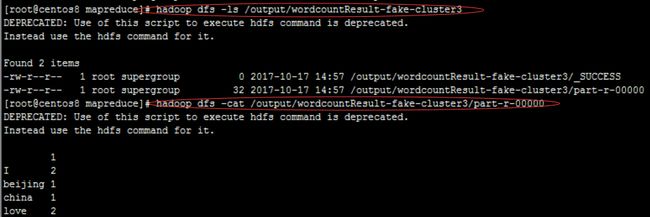
和之前的demo一样,在hdfs中准备数据文件,将jar包从本机导入到hadoop集群主节点机器。
hadoop jar mapreduceTest.jar /input/wordcountTestData.txt /output/wordcountResult-fake-cluster3

![]()