自然语言处理(NLP):23 Word2Vec词向量研究以及实践
本文主要同大家分享word2vec原理以及应用,通过文本相似度和新闻文本分类为案例进行展开,最后对词向量技术发展进行简述。
作者:走在前方
博客:https://wenjie.blog.csdn.net/
学习交流群:更多精彩内容加入“NLP技术交流群” 学习(网站访问博客网页)
专注于文本分类、关键词抽取、文本摘要、FAQ 问答系统、对话系统语义理解 NLU、知识图谱等研究和实践。结合工业界具体案例和学术界最新研究成果实现 NLP 技术场景落地。
本次分享主要内容
- 词向量以及相关应用介绍
- NLP常见的任务
- 词离散化表示和分布式表示
- 词相似性分析以及词嵌入可视化
- 词向量知识理论介绍
- NNLM模型和word2vec 模型
- fastText 词向量以及文本分类原理
- pytorch 工具构建word2vec 模型
- 词向量的概念
- 用 skip-gram 模型训练词向量
- PyTorch dataset 和 dataloader
- 定义 PyTorch 模型
- 学习 torch.nn 中常见的 Module
- Embedding
- 学习常见的 PyTorch operations
- bmm
- logsigmoid
- 保存和读取 PyTorch 模型
- gensim 工具构建word2vec 模型
- 数据分词处理
- 词向量模型训练以及性能功能验证
- 相似性服务演示以及数据可视化
- word2vec 词向量可视化
- 案例分享
- 新闻相似推荐
- 新闻文本分类
- 展望未来:词向量技术拓展
- 词向量历史发展(word2vec-> ElMo->GPT-> BERT…)
- 不同词向量对比分析
词向量及相关应用
NLP 常见任务
- 自动摘要
- 指代消解
- 机器翻译
- 词性标注
- 分词
- 主题识别
- 文本分类
- 。。。。
词离散表示
- One-hot 表示
- Bag of Words
- Bi-gram 和 N-gram
- 离散表示面临的问题
One-hot 表示
- 语料库
John likes to watch movies. Mary likes too.
John also likes to watch football games.
- 词典
{“John”: 1, “likes”: 2, “to”: 3, “watch”: 4, “movies”: 5, “also”: 6, “football”: 7, “games”: 8, “Mary”: 9, “too”: 10}
- One-hot 表示
john: [1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
likes: [0, 1, 0, 0, 0, 0, 0, 0, 0, 0]
。。。。
too : [0, 0, 0, 0, 0, 0, 0, 0, 0, 1]
表示方法: 词典包含 10 个单词,每个单词有唯一索引
面临的问题:词典中的顺序和在句子中的顺序没有关联
Bag of Words
- 文档的向量表示可以直接将各词的词向量表示加和
John likes to watch movies. Mary likes too.
John also likes to watch football games.
分别表示成下面的格式,体现每个单词出现的次数
[1, 2, 1, 1, 1, 0, 0, 0, 1, 1]
[1, 1, 1, 1, 0, 1, 1, 1, 0, 0]
- 词权重
- TF-IDF (Term Frequency - Inverse Document Frequency)
词 t 的 IDF weight,N: 文档总数,nt: 含有词 t 的文档数

[0.693, 1.386, 0.693, 0.693, 1.099, 0, 0, 0, 0.693, 0.693]
- Binary weighting
短文本相似性,Bernoulli Naive Bayes
[1, 1, 1, 1, 1, 0, 0, 0, 1, 1]
Bi-gram 和 N-gram
bi-gram 建索引(2-gram):
"John likes”: 1,
"likes to”: 2,
"to watch”: 3,
"watch movies”: 4,
"Mary likes”: 5,
"likes too”: 6,
"John also”: 7,
"also likes”: 8,
“watch football”: 9,
“football games”: 10,
该方法的优缺点如下
优点:考虑了词的顺序
缺点:词表的膨胀
离散表示面临的问题
- 无法衡量词向量之间的关系(太稀疏,很难捕捉文本的含义)
酒店 [0, 1, 0, 0, 0, 0, 0, 0, 0, 0]
宾馆 [0, 0, 0, 0, 1, 0, 0, 0, 0, 0]
旅舍 [0, 0, 0, 0, 0, 0, 0, 0, 1, 0]
- 词表维度随着语料库增长膨胀
- n-gram 词序列随语料库膨胀更快
- 数据稀疏问题
那么有没有一种方法解决上述主要问题呢?
答案: 分布式词嵌入 distribution word embedding
分布式词表示
用一个词附近的其他词来表示该词
“You shall know a word by the company it keeps” (J. R. Firth 1957: 11)
现代统计自然语言处理中最有创见的想法之一。

banking 附近的词将会代表 banking 的含义
词的相似性
- 单词最近相似词列表
the closest words to the target word frog:
- frog
- frogs
- toad
- litoria
- leptodactylidae
- rana
- lizard
- eleutherodactylus

上述资料:
GloVe: Global Vectors for Word Representation
https://nlp.stanford.edu/projects/glove/
https://nlp.stanford.edu/pubs/glove.pdf
- 词之间相似度比较分析
P(solid | ice) 相对较高
P(solid | steam) 相对较低
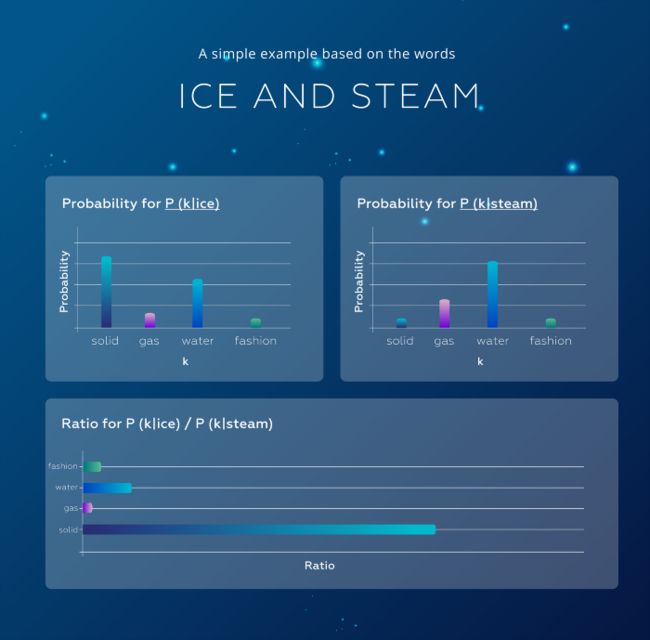
词嵌入可视化
男-女

公司-CEO
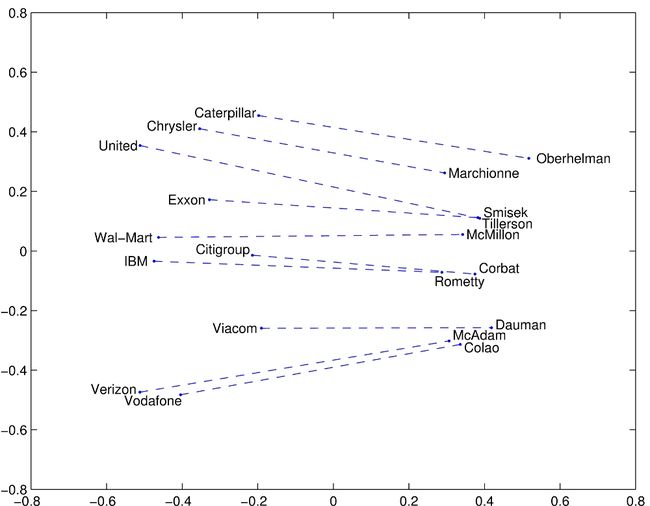
城市-邮政编码
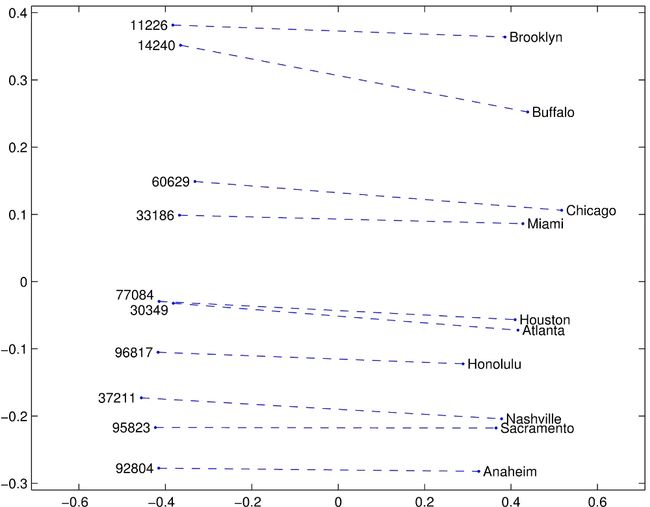
比较级-最高级

英语-西班牙语

词向量知识理论介绍
NNLM (Neural Network Language model)
网络语言模型是词向量是嵌入技术的一种,将非数值的单词嵌入到向量空间中去. 该模型属于预测语言模型, 即通过完成一个预测任务,如根据一部分文本或单词预测与其相关联的单词,训练的过程中得到单词的向量表达形式.
NNLM 结构
http://www.jmlr.org/papers/volume3/bengio03a/bengio03a.pdf
https://mycourses.aalto.fi/pluginfile.php/634164/mod_resource/content/4/nnlm%2Bend2018.pdf


- (N-1)个前向词:one-hot 表示
- 采用线性映射将 one-hot 表 示投影到稠密 D 维表示(词典维数 V,稠密词向量表示维数 D)
- 输出层:Softmax
- 各层权重最优化:BP+SGD
NNLM 计算复杂度
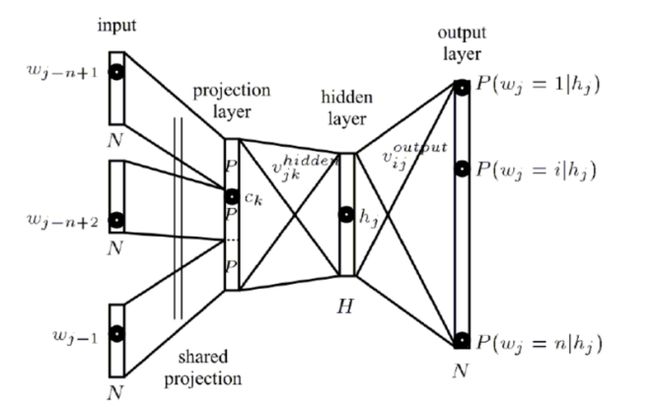
每个训练样本的计算复杂度:N * D + N * D * H + H * V
一个简单模型在大数据量上的表现比复杂模型在少数据量上的表现会好
Word2Vec 模型
https://arxiv.org/pdf/1309.4168v1.pdf

Word2Vec Skip-Gram 模型
https://papers.nips.cc/paper/5021-distributed-representations-of-words-and-phrases-and-their-compositionality.pdf
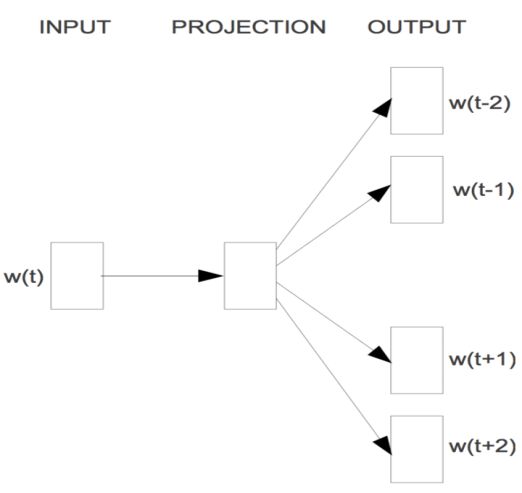
Skip-gram 模型架构,训练的目标学习一个词向量表示,根据当前词获取周围的相关词。
- 无隐层
- 投影层也可省略
- 每个词向量作为 log-linear 模型的输入
目标函数:

W(t) : 中心词
C: 上下文词
- 概率密度由 Softmax 给出

Skip-Gram 负例采样:Negative sampling 训练的目标
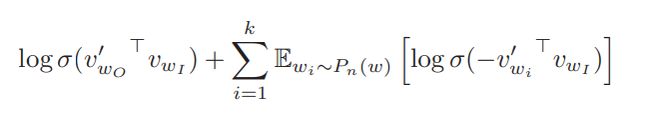
logsimoid(中心词,周围词)
logsimoid(中心词,负采样的词),针对每个周围词采用采样 k 个词
Word2Vec 存在的问题
- 每个 local context window 单独训练,没有利用包含在 global co-currence 矩阵中的统计信息
- 对多义词无法很好的表示和处理,因为使用了唯一 的词向量
word2vec 之 PyTorch 实现
研究主要内容
- 词向量的概念
- 用 skip-gram 模型训练词向量
- PyTorch dataset 和 dataloader
- 定义 PyTorch 模型
- 学习 torch.nn 中常见的 Module
- Embedding
- 学习常见的 PyTorch operations
- bmm
- logsigmoid
- 保存和读取 PyTorch 模型
我们采用 wiki 一小部分数据,来演示 pytorch 如何训练 word-embedding.
《word-embedding.ipynb》通过本部分,我们重点了解如何通过 pytorch 来实现一个 word2vec,不对实际的效果进行进行详细的调整。

gensim 工具实现词向量模型
- 原始语料数据: 中文维基 wiki.zh.simp.txt 大概 1.2G 的数据. 40 万+篇文章
- 原始数据分词:wiki.zh.simp.txt -> wiki.zh.simp.seg.txt 我们构建了 1.5G 的数据。40 万篇文章
- 模型效果评估
- 词性服务在线部署
语料分词处理
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# 逐行读取文件数据进行 jieba 分词
import jieba
import codecs
if __name__ == '__main__':
input_data = 'data/wiki.zh.simp.txt'
output_data = 'data/wiki.zh.simp.seg.txt'
f = codecs.open(input_data, 'r', encoding='utf8')
target = codecs.open(output_data, 'w', encoding='utf8')
print('open files.')
lineNum = 1
line = f.readline()
while line:
line = line.strip()
print('---processing ', lineNum, ' article---')
seg_list = jieba.cut(line, cut_all=False)
line_seg = ' '.join(seg_list)
target.write(line_seg + "\n")
lineNum = lineNum + 1
line = f.readline()
print('well done.')
f.close()
target.close()
词向量模型训练
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# 使用 gensim word2vec 训练脚本获取词向量
import logging
import os.path
import sys
import multiprocessing
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence
if __name__ == '__main__':
program = os.path.basename(sys.argv[0])
logger = logging.getLogger(program)
logging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s', level=logging.INFO)
logger.info("running %s" % ' '.join(sys.argv))
# inp 为输入语料, outp1 为输出模型, outp2 word2vec 的 vector 格式的模型
fdir = 'wiki_zh_vec/'
inp = '../data/wiki.zh.simp.seg.txt'
outp1 = fdir + 'wiki.zh.text.model'
outp2 = fdir + 'wiki.zh.text.vector'
# 训练 skip-gram 模型
model = Word2Vec(LineSentence(inp),
size=100,
window=5,
min_count=5,
workers=multiprocessing.cpu_count())
# 保存模型
model.save(outp1)
model.wv.save_word2vec_format(outp2, binary=False)
最终生成两个重要的文件
- 向量模型 wiki_zh_vec/wiki.zh.text.model
- 模型对应的词向量 wiki_zh_vec/wiki.zh.text.vector
执行训练代码:python train_word_vector.py
注意: 考虑数据量比较大,如果大家电脑资源有限,可以考虑数据变小一些,然后尝试进行训练,我的电脑内存 8G 的。每个一次迭代将近 10 分钟,故:也可以减少迭代次数来尝试训练。

…

词相似性功能效果测试
# 测试训练好的模型
import gensim
if __name__ == '__main__':
fdir = 'wiki_zh_vec/'
model = gensim.models.Word2Vec.load(fdir + 'wiki.zh.text.model')
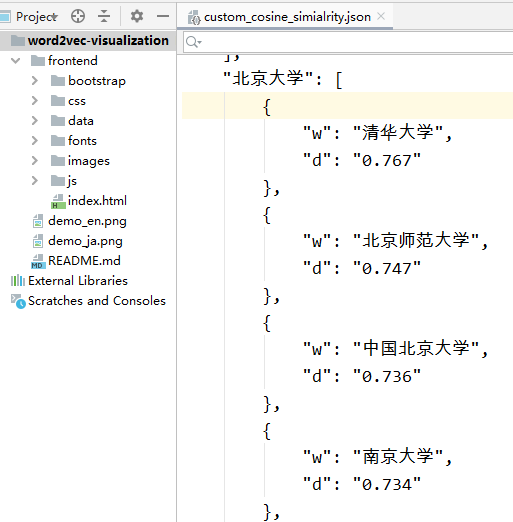
word = model.wv.most_similar(u"北京大学")
result = []
for t in word:
print(t[0], t[1])
result.append("{}|{}".format(t[0], t[1]))
print("\n".join(result))
最终的结果: 输入每个单词和相似度得分,感觉很不错哦
清华大学 0.9125707745552063
武汉大学 0.8931570053100586
燕京大学 0.8854908347129822
上海大学 0.8746916651725769
复旦大学 0.8719724416732788
中国人民大学 0.8659096956253052
浙江大学 0.8627960085868835
南开大学 0.8615208268165588
北洋大学 0.8545465469360352
词相似性在线服务
为方便访问,我们提供一个专门的服务,这样可以实时获取某个单词的相似词列表
import gensim
from flask import Flask, request
app = Flask(__name__)
fdir = 'wiki_zh_vec/'
model = gensim.models.Word2Vec.load(fdir + 'wiki.zh.text.model')
@app.route('/api/v1.0/sim', methods=['get'])
def predict():
result = []
query = request.args.get('query')
word = model.wv.most_similar(u"{}".format(query), topn=20)
for t in word:
result.append("{}|{}
".format(t[0], t[1]))
data = "\n".join(result)
print(data)
return data
if __name__ == '__main__':
app.run(host='0.0.0.0')
第一步: 启动在线服务
python api.py
第二步:在线服务预测

fastText,最终我们生成需要标准化的文件。
例如:custom_cosine_simialrity.json,我们的数据格式
标准数据生成
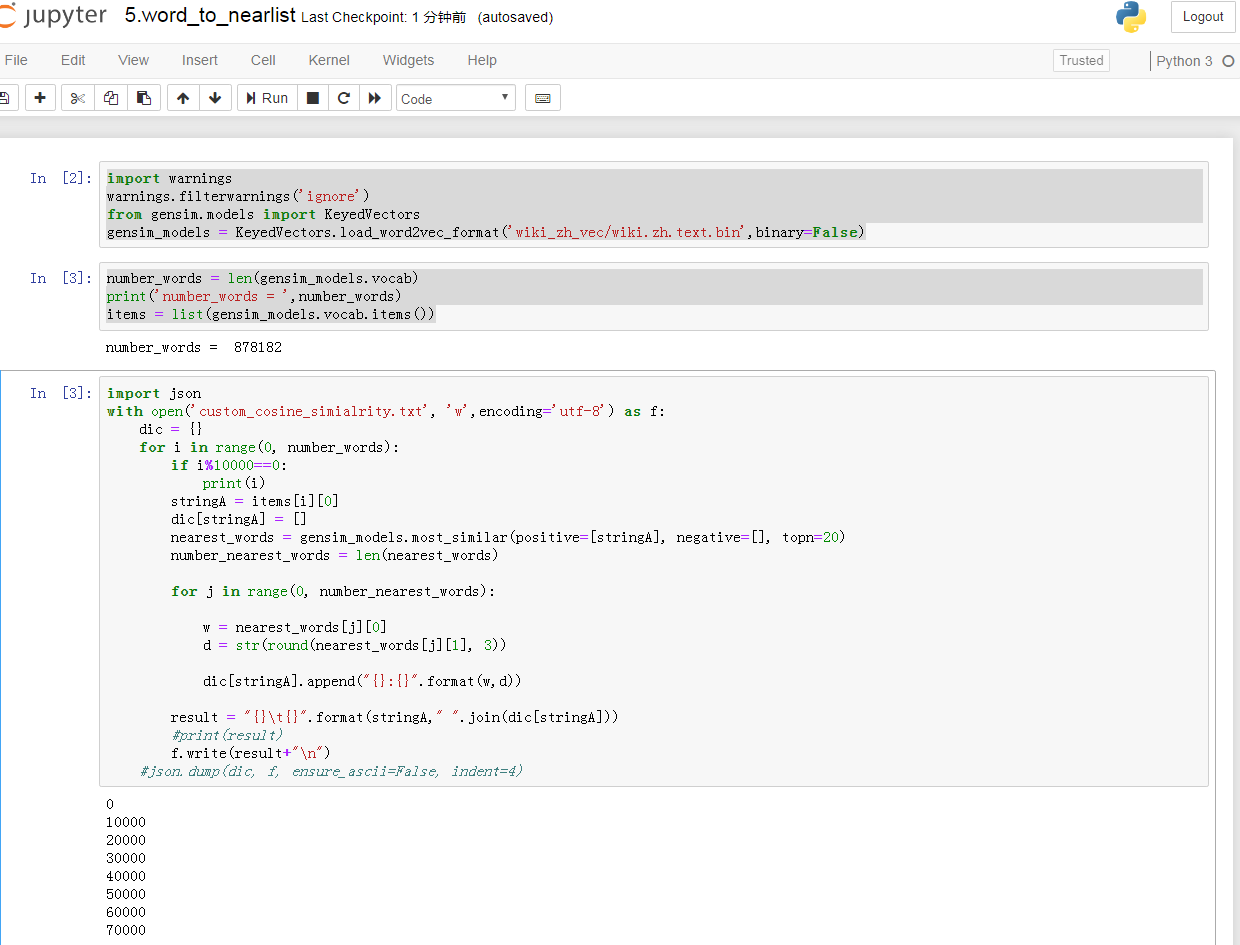

数据标准格式举例

词向量可视化
custom_cosine_simialrity.json 拷贝到项目工作下即可
服务启动:python -m http.server 8081,启动成功后可以通过浏览器访问了 http://127.0.0.1:8081/
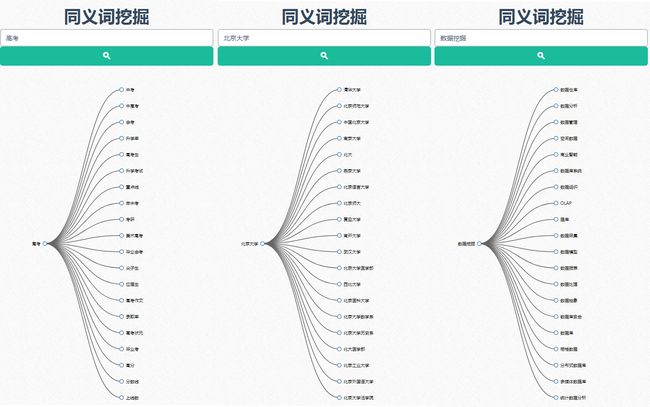
应用案例分析
新闻相似推荐
目标: 获取文本相似的文本列表
query document socre
query doc1
query doc2
query doc3
query doc4
实现方案步骤:
- 新闻库数据: 来自爬虫 ,这里我们获取 20000 篇 新闻 标题 作为新闻基础库( 小预料数据)
- 基于基础数据训练 word2vec 模型
- 新闻基础库 向量化处理
- 根据用户访问的单个新闻标题 从基础库获取相似新闻 topN
新闻基础库
为方便理解,我们模拟一批新闻 news_data.txt: 新闻 ID 制表符 新闻标题
举例说明:
0 龙山华府将推出 86-140 平米灵动空间
1 朱骏给毛剑卿洗脑一小时 小毛:看守所里有我球迷
2 广东商品房销售均价达到 6392 元平方米
新闻基础库向量化
新闻-> 爬虫-> 调用词向量模型-> 每篇新闻向量化结果-> 数据库存储(mongodb,hdfs)
这里假设数据存储一个文本中。
news_data.txt-> news_data_vector.bin
文本相似性计算
对于新闻来说,对时效性要求非常高。一般用户点击标题后对比的基础库有限的。我们这里每次从提供的 所有新闻列表进行检索,计算相似度得分。

文本相似度扩展方案,更多数据大家也可以去爬取,可以尝试使用 1G 左右数据,效果基本上可以使用了。
如果准备运用到线上系统,这里提供大家一些优化方案
- 训练的数据增加是必须的,重点 数据
- word2vec 模型定期基于当前的数据进行增量训练
- 分词部分大家可以考虑使用 jieba 这种进行分词
- 可以使用一些预训练好的开源模型,在此基础上进行增量训练
- 关于词向量大家也可以使用(Elmo,BERT 等,效果很好)
- 目前我们仅使用标题,实际工作我们需要结合标题和内容同时进行训练和预测
新闻文本分类
学习目标
- fastText 简介
- fastText 结构
- fastText 文本分类实战
- 数据分析和可视化
- 文本分类模型训练以及参数调优
- 文本分类模型压缩
- 分类模型效果评估
- 模型预测
fastText 介绍
fasttext 是 facebook 开源的一个词向量与文本分类工具,在学术上没有太多创新点,好处是模型简单,训练速度非常快。简单尝试可以发现,用起来还是非常顺手的,做出来的结果也不错,可以达到上线使用的标准。
简单说来,fastText 做的事情,就是把文档中所有词通过 lookup table 变成向量,取平均之后直接用线性分类器得到分类结果。论文指出了对一些简单的分类任务,没有必要使用太复杂的网络结构就可以取得差不多的结果。
fastText 是一个快速文本分类算法,与基于神经网络的分类算法相比有两大优点:
- fastText 在保持高精度的情况下加快了训练速度和测试速度
- fastText 不需要预训练好的词向量,fastText 会自己训练词向量
- fastText 两个重要的优化:Hierarchical Softmax、N-gram
fastText 结构
fastText 模型架构和 word2vec 中的 CBOW 很相似, 不同之处是 fastText 预测标签而 CBOW 预测的是中间词,即模型架构类似但是模型的任务不同。
- 回顾 word2vec
word2vec 将上下文关系转化为多分类任务,进而训练逻辑回归模型,这里的类别数量|V|词库大小。通常的文本数据中,词库少则数万,多则百万,在训练中直接训练多分类逻辑回归并不现实。word2vec 中提供了两种针对大规模多分类问题的优化手段,negative sampling 和 hierarchical softmax。在优化中,negative sampling 只更新少量负面类,从而减轻了计算量。hierarchical softmax 将词库表示成前缀树,从树根到叶子的路径可以表示为一系列二分类器,一次多分类计算的复杂度从|V|降低到了树的高度
- fastText 结构
x1,x2,…,xN−1,xN表示一个文本中的n-gram向量,每个特征是词向量的平均值。这和前文中提到的cbow相似,cbow用上下文去预测中心词,而此处用全部的n-gram去预测指定类别。

fastText 论文中提到了两个 tricks
- hierarchical softmax
- 类别数较多时,通过构建一个霍夫曼编码树来加速 softmax layer 的计算,和之前 word2vec 中的 trick 相同
- N-gram features
- 只用 unigram 的话会丢掉 word order 信息,所以通过加入 N-gram features 进行补充用 hashing 来减少 N-gram 的存储
fastText 文本分类

数据处理
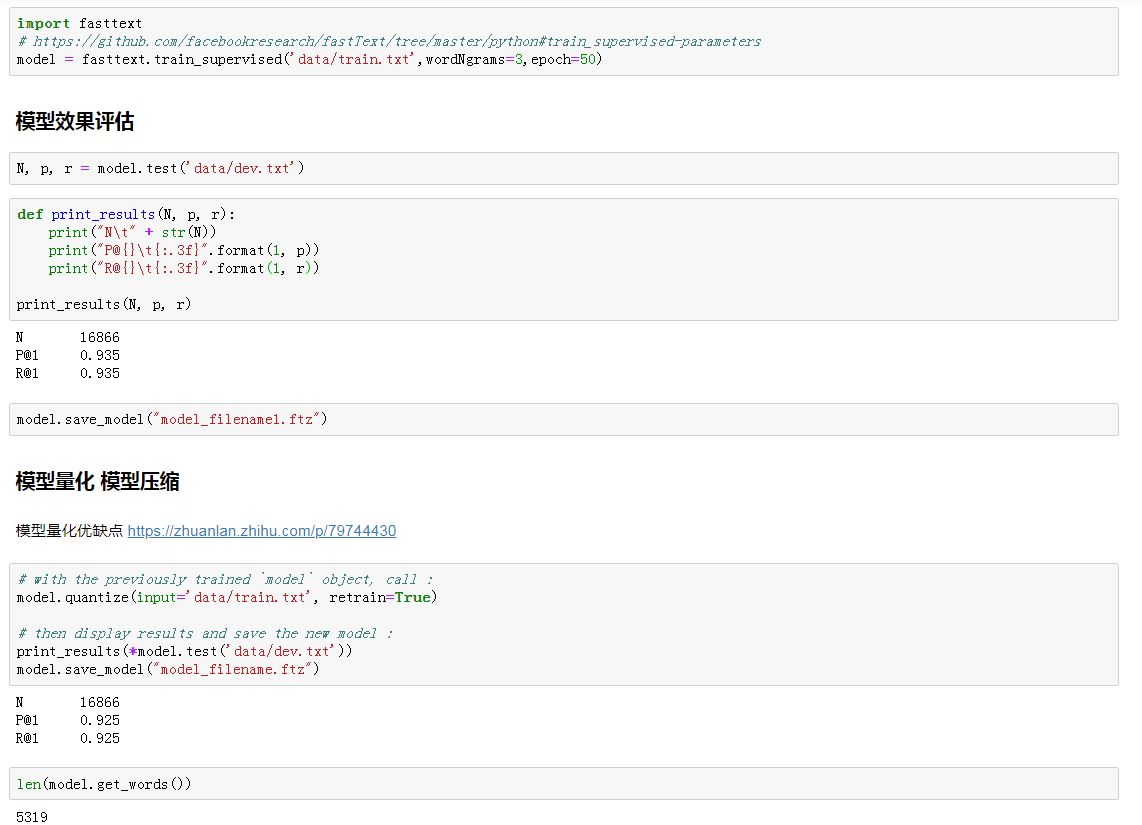
训练效果评估和模型压缩
文本分类效果评估

文本分类在线预测

具体内容可以参考《fasttext 文本分类》
拓展:NLP 领域词向量发展
更多资料参考博客: https://blog.csdn.net/shenfuli/article/details/106337940

文本表示和词向量对比
下面对文本表示进行一个归纳,对于一篇文本可以如何用数学语言表示呢?
- 基于 one-hot、tf-idf、textrank 等的 bag-of-words;
- 主题模型:LSA(SVD)、pLSA、LDA;
- 基于词向量的固定表征:Word2vec、FastText、GloVe
- 基于词向量的动态表征:ELMo、GPT、BERT
各种词向量的特点
- One-hot 表示 :维度灾难、语义鸿沟;
- 分布式表示 (distributed representation) :
- 矩阵分解(LSA):利用全局语料特征,但 SVD 求解计算复杂度大;
- 基于 NNLM/RNNLM 的词向量:词向量为副产物,存在效率不高等问题;
- Word2vec、FastText:优化效率高,但是基于局部语料;
- GloVe:基于全局预料,结合了 LSA 和 Word2vec 的优点;
- ELMo、GPT、BERT:动态特征
Word2vec 和 NNLM 对比
- 本质都可以看作是语言模型;
- 词向量只不过 NNLM 一个产物,Word2vec 虽然其本质也是语言模型,但是其专注于词向量本身,因此做了许多优化来提高计算效率:
- 与 NNLM 相比,词向量直接 sum,不再拼接,并舍弃隐层;
- 考虑到 sofmax 归一化需要遍历整个词汇表,采用 hierarchical softmax 和 negative sampling 进行优化,hierarchical softmax 实质上生成一颗带权路径最小的哈夫曼树,让高频词搜索路劲变小;negative sampling 更为直接,实质上对每一个样本中每一个词都进行负例采样;
Word2vec 和 FastText 对比
- 都是无监督学习词向量,FastText 训练词向量时会考虑 subword;
- FastText 还可以进行有监督学习进行文本分类,其主要特点:
- 结构与 CBOW 类似,但学习目标是人工标注的分类结果;
- 采用 hierarchical softmax 对输出的分类标签建立哈夫曼树,样本中标签多的类别被分配短的搜寻路径;
- 引入 N-gram,考虑词序特征;
- 引入 subword 来处理长词,处理未登陆词问题;
Word2vec** 和 GloVe 对比**
- Word2vec 是局部语料库训练的,其特征提取是基于滑窗的;而 GloVe 的滑窗是为了构建 co-occurance matrix,是基于全局语料的,可见 GloVe 需要事先统计共现概率;因此,Word2vec 可以进行在线学习,GloVe 则需要统计固定语料信息。
- Word2vec 是无监督学习,同样由于不需要人工标注;GloVe 通常被认为是无监督学习,但实际上 GloVe 还是有 label 的,即共现次数 。
- Word2vec 损失函数实质上是带权重的交叉熵,权重固定;GloVe 的损失函数是最小平方损失函数,权重可以做映射变换。
总体来看,GloVe 可以被看作是更换了目标函数和权重函数的全局 Word2vec
ELMo、GPT、BERT 对比
它们都是基于语言模型的动态词向量。下面从几个方面对这三者进行对比:
- 特征提取器
- ELMo 采用 LSTM 进行提取,GPT 和 BERT 则采用 Transformer 进行提取。
- Transformer 特征提取能力强于 LSTM,ELMo 采用 1 层静态向量 +2 层 LSTM,多层提取能力有限,而 GPT 和 BERT 中的 Transformer 可采用多层,并行计算能力强。
- 单 / 双向语言模型
- GPT 采用单向语言模型,ELMo 和 BERT 采用双向语言模型。但是 ELMo 实际上是两个单向语言模型(方向相反)的拼接,这种融合特征的能力比 BERT 一体化融合特征方式弱。
- GPT 和 BERT 都采用 Transformer,Transformer 是 encoder-decoder 结构,GPT 的单向语言模型采用 decoder 部分,decoder 的部分见到的都是不完整的句子;BERT 的双向语言模型则采用 encoder 部分,采用了完整句子。