kafka connect简介以及部署
1、什么是kafka connect?
根据官方介绍,Kafka Connect是一种用于在Kafka和其他系统之间可扩展的、可靠的流式传输数据的工具。它使得能够快速定义将大量数据集合移入和移出Kafka的连接器变得简单。 Kafka Connect可以获取整个数据库或从所有应用程序服务器收集指标到Kafka主题,使数据可用于低延迟的流处理。导出作业可以将数据从Kafka topic传输到二次存储和查询系统,或者传递到批处理系统以进行离线分析。 Kafka Connect功能包括:
- Kafka connector通用框架,提供统一的集成API
- 同时支持分布式模式和单机模式
- REST 接口,用来查看和管理Kafka connectors
- 自动化的offset管理,开发人员不必担心错误处理的影响
- 分布式、可扩展
- 流/批处理集成
KafkaCnnect有两个核心概念:Source和Sink。 Source负责导入数据到Kafka,Sink负责从Kafka导出数据,它们都被称为Connector。
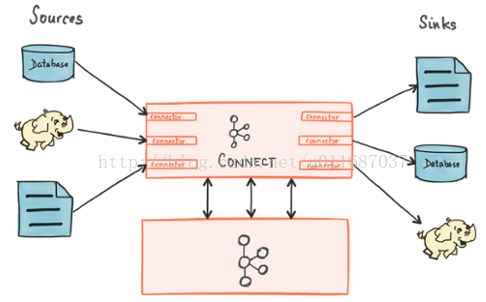
2、kafka connect概念。
Kafka connect的几个重要的概念包括:connectors、tasks、workers和converters。
- Connectors-通过管理任务来细条数据流的高级抽象
- Tasks- 数据写入kafka和数据从kafka读出的实现
- Workers-运行connectors和tasks的进程
- Converters- kafka connect和其他存储系统直接发送或者接受数据之间转换数据
1) Connectors:在kafka connect中,connector决定了数据应该从哪里复制过来以及数据应该写入到哪里去,一个connector实例是一个需要负责在kafka和其他系统之间复制数据的逻辑作业,connector plugin是jar文件,实现了kafka定义的一些接口来完成特定的任务。
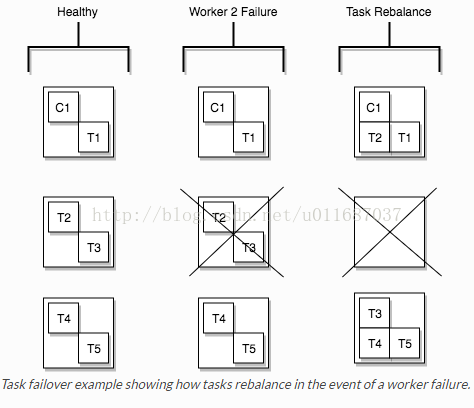
2) Tasks:task是kafka connect数据模型的主角,每一个connector都会协调一系列的task去执行任务,connector可以把一项工作分割成许多的task,然后再把task分发到各个worker中去执行(分布式模式下),task不自己保存自己的状态信息,而是交给特定的kafka 主题去保存(config.storage.topic 和status.storage.topic)。在分布式模式下有一个概念叫做任务再平衡(Task Rebalancing),当一个connector第一次提交到集群时,所有的worker都会做一个task rebalancing从而保证每一个worker都运行了差不多数量的工作,而不是所有的工作压力都集中在某个worker进程中,而当某个进程挂了之后也会执行task rebalance。
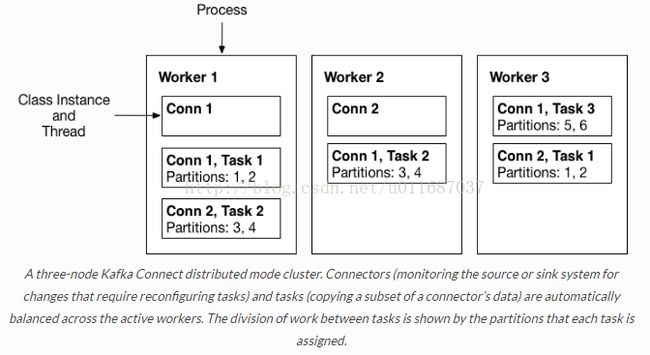
3) Workers:connectors和tasks都是逻辑工作单位,必须安排在进程中执行,而在kafka connect中,这些进程就是workers,分别有两种worker:standalone和distributed。这里不对standalone进行介绍,具体的可以查看官方文档。我个人觉得distributed worker很棒,因为它提供了可扩展性以及自动容错的功能,你可以使用一个group.ip来启动很多worker进程,在有效的worker进程中它们会自动的去协调执行connector和task,如果你新加了一个worker或者挂了一个worker,其他的worker会检测到然后在重新分配connector和task。
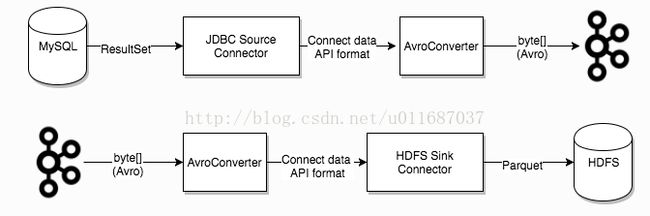
4) Converters: converter会把bytes数据转换成kafka connect内部的格式,也可以把kafka connect内部存储格式的数据转变成bytes,converter对connector来说是解耦的,所以其他的connector都可以重用,例如,使用了avro converter,那么jdbc connector可以写avro格式的数据到kafka,当然,hdfs connector也可以从kafka中读出avro格式的数据。
3、kafka connect的启动。
Kafka connect的工作模式分为两种,分别是standalone模式和distributed模式。
在独立模式种,所有的work都在一个独立的进程种完成,如果用于生产环境,建议使用分布式模式,都在真的就有点浪费kafka connect提供的容错功能了。
standalone启动的命令很简单,如下:
bin/connect-standalone.shconfig/connect-standalone.properties connector1.properties[connector2.properties ...]一次可以启动多个connector,只需要在参数中加上connector的配置文件路径即可。
启动distributed模式命令如下:
bin/connect-distributed.shconfig/connect-distributed.properties在connect-distributed.properties的配置文件中,其实并没有配置了你的connector的信息,因为在distributed模式下,启动不需要传递connector的参数,而是通过REST API来对kafka connect进行管理,包括启动、暂停、重启、恢复和查看状态的操作,具体介绍详见下文。
在启动kafkaconnect的distributed模式之前,首先需要创建三个主题,这三个主题的配置分别对应connect-distributed.properties文件中config.storage.topic(default connect-configs)、offset.storage.topic (default connect-offsets) 、status.storage.topic (default connect-status)的配置,那么它们分别有啥用处呢?
- config.storage.topic:用以保存connector和task的配置信息,需要注意的是这个主题的分区数只能是1,而且是有多副本的。(推荐partition 1,replica 3)
- offset.storage.topic:用以保存offset信息。(推荐partition50,replica 3)
- status.storage.topic:用以保存connetor的状态信息。(推荐partition10,replica 3)
以下是创建主题命令:
# config.storage.topic=connect-configs
$ bin/kafka-topics --create --zookeeper localhost:2181 --topicconnect-configs --replication-factor 3 --partitions 1
# offset.storage.topic=connect-offsets
$ bin/kafka-topics --create --zookeeper localhost:2181 --topicconnect-offsets --replication-factor 3 --partitions 50
# status.storage.topic=connect-status
$ bin/kafka-topics --create --zookeeper localhost:2181 --topicconnect-status --replication-factor 3 --partitions 10具体配置信息再次不在赘述,详见kafka官方文档:http://kafka.apache.org/documentation/#connect
4、通过rest api管理connector
因为kafka connect的意图是以服务的方式去运行,所以它提供了REST API去管理connectors,默认的端口是8083,你也可以在启动kafka connect之前在配置文件中添加rest.port配置。
- GET /connectors – 返回所有正在运行的connector名
- POST /connectors – 新建一个connector; 请求体必须是json格式并且需要包含name字段和config字段,name是connector的名字,config是json格式,必须包含你的connector的配置信息。
- GET /connectors/{name} – 获取指定connetor的信息
- GET /connectors/{name}/config – 获取指定connector的配置信息
- PUT /connectors/{name}/config – 更新指定connector的配置信息
- GET /connectors/{name}/status – 获取指定connector的状态,包括它是否在运行、停止、或者失败,如果发生错误,还会列出错误的具体信息。
- GET /connectors/{name}/tasks – 获取指定connector正在运行的task。
- GET /connectors/{name}/tasks/{taskid}/status – 获取指定connector的task的状态信息
- PUT /connectors/{name}/pause – 暂停connector和它的task,停止数据处理知道它被恢复。
- PUT /connectors/{name}/resume – 恢复一个被暂停的connector
- POST /connectors/{name}/restart – 重启一个connector,尤其是在一个connector运行失败的情况下比较常用
- POST /connectors/{name}/tasks/{taskId}/restart – 重启一个task,一般是因为它运行失败才这样做。
- DELETE /connectors/{name} – 删除一个connector,停止它的所有task并删除配置。