学习Hadoop第十二课(Hadoop序列化机制、Linux安装Eclipse及创建快捷图标、使用Maven开发)
首先我们来学习一下,什么叫做序列化,序列化是指把结构化对象转换成字节流,这样做的目的当然是便于在网络中传输。那么什么叫做反序列化?相信大家也知道了,反序列化,顾名思义,就是序列化的逆过程,也就是将字节流转回结构化对象的过程。
我们非常熟悉的序列化莫过于java的java.io.Serializable了,在java程序中我们要序列化某个类,就给该类打个序列化的标记,我们不用自己去序列化,Java虚拟机会帮我们做好序列化的工作。那么既然java的jdk已经有这么一套成熟的序列化机制了,为什么Hadoop没有使用?这里我们举个例子,假如我们定义了一个叫Animal的基类,该类有动物的一些公共属性及方法,比如动物会叫、会跑等,我们再定义一个Monkey类,该类继承了Animal类,很明显,猴子也是动物,只不过猴子除了动物的一些公共特性外,它还有自己特殊的特性,比如猴子会爬树、会吃香蕉等。用我们的java序列化机制序列化Monkey这个类时,还要保存它与父类Animal的继承结构。反序列化时当然这些也是需要保留的。我们Hadoop要序列化某个类是根本不需要保留它们的继承结构的,只需要能够实现持久化,能够实现快速传递就可以了。这样的话,Java的序列化就会非常冗余,因此Hadoop没有采用Java的序列化机制,而是自己实现了一套序列化机制。
Hadoop序列化的特点如下:
1. 紧凑,高效使用存储空间
2. 快速,读写数据的额外开销小
3. 可扩展性,可透明地读取老格式的数据
4. 互操作,支持多语言的交互
Hadoop的序列化格式是:Writable
接下来我们通过查看Hadoop的一个类LongWritable的源码来看一下Hadoop的序列化。我们发现LongWritable实现了WritableCompareable接口,如下图所示。

接下来我们来看一下WritableComparable这个接口,我们发现这个接口继承了Writable、Comparable两个接口,其中Writable就是我们所说的Hadoop的序列化所要实现的接口,如下图所示。
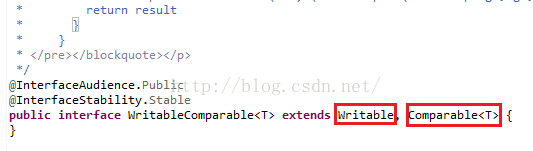
我们点进去Writable,我们发现该接口下定义了两个接口方法,分别是write和readFields,其中write方法是把一个对象转换为字节流,readFields是把字节流转换成对象。
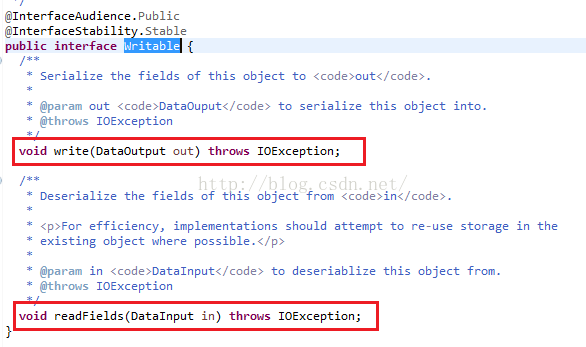
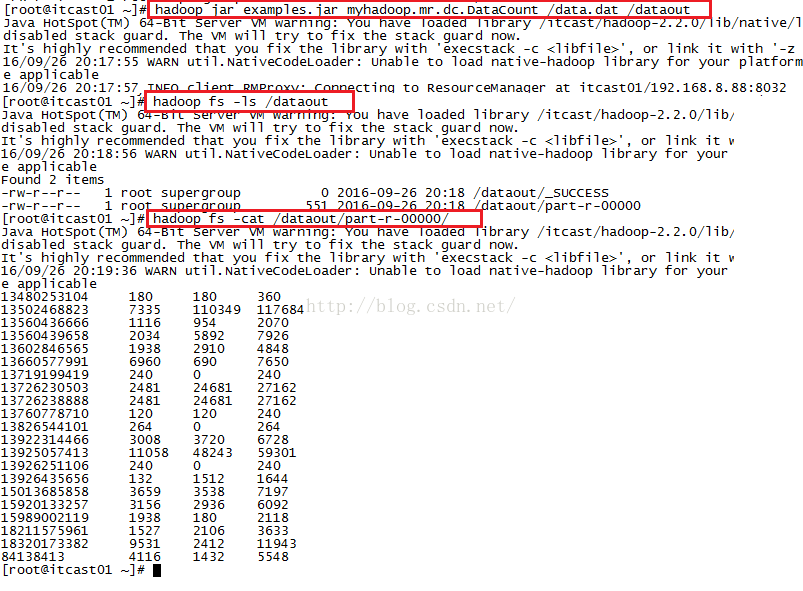
接下来我们来做一个实际的例子,该例子既用到了序列化的知识,又用到了大数据的知识。下面是某网吧提供的上网数据,为了能让大家更明白的看懂每列数据的意思,我为每列进行了说明,大家使用数据的时候不用粘贴表头,只粘贴内容就行了。我们现在的需求是,想要得到一天内所有用户上网总流量从高到低的一张列表。针对该需求,我们只需用到下面三列数据,分别是手机号、上行流量、下行流量。
访问时间 手机号或上网卡 网络运营商的MAC地址 上网机器的IP 访问网站 网址类型 上行包 下行包 上行流量 下行流量 状态
1363157985066 13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 www.taobao.com 购物网站 24 27 2481 24681 200
1363157995052 13826544101 5C-0E-8B-C7-F1-E0:CMCC 120.197.40.4 4 0 264 0 200
1363157991076 13926435656 20-10-7A-28-CC-0A:CMCC 120.196.100.99 2 4 132 1512 200
1363154400022 13926251106 5C-0E-8B-8B-B1-50:CMCC 120.197.40.4 4 0 240 0 200
1363157993044 18211575961 94-71-AC-CD-E6-18:CMCC-EASY 120.196.100.99 iface.qiyi.com 视频网站 15 12 1527 2106 200
1363157995074 84138413 5C-0E-8B-8C-E8-20:7DaysInn 120.197.40.4 122.72.52.12 20 16 4116 1432 200
1363157993055 13560439658 C4-17-FE-BA-DE-D9:CMCC 120.196.100.99 18 15 1116 954 200
1363157995033 15920133257 5C-0E-8B-C7-BA-20:CMCC 120.197.40.4 sug.so.360.cn 信息安全 20 20 3156 2936 200
1363157983019 13719199419 68-A1-B7-03-07-B1:CMCC-EASY 120.196.100.82 4 0 240 0 200
1363157984041 13660577991 5C-0E-8B-92-5C-20:CMCC-EASY 120.197.40.4 s19.cnzz.com 站点统计 24 9 6960 690 200
1363157973098 15013685858 5C-0E-8B-C7-F7-90:CMCC 120.197.40.4 sogou.com 搜索引擎 28 27 3659 3538 200
1363157986029 15989002119 E8-99-C4-4E-93-E0:CMCC-EASY 120.196.100.99 www.umeng.com 站点统计 3 3 1938 180 200
1363157992093 13560439658 C4-17-FE-BA-DE-D9:CMCC 120.196.100.99 15 9 918 4938 200
1363157986041 13480253104 5C-0E-8B-C7-FC-80:CMCC-EASY 120.197.40.4 3 3 180 180 200
1363157984040 13602846565 5C-0E-8B-8B-B6-00:CMCC 120.197.40.4 2052. flash2qq.com 综合门户 15 12 1938 2910 200
1363157995093 13922314466 00-FD-07-A2-EC-BA:CMCC 120.196.100.82 img.qfc.cn 12 12 3008 3720 200
1363157982040 13502468823 5C-0A-5B-6A-0B-D4:CMCC-EASY 120.196.100.99 y0.ifengimg.com 综合门户 57 102 7335 110349 200
1363157986072 18320173382 84-25-DB-4F-10-1A:CMCC-EASY 120.196.100.99 sogou.com 搜索引擎 21 18 9531 2412 200
1363157990043 13925057413 00-1F-64-E1-E6-9A:CMCC 120.196.100.55 t3. baidu.com 搜索引擎 69 63 11058 48243 200
1363157988072 13760778710 00-FD-07-A4-7B-08:CMCC 120.196.100.82 2 2 120 120 200
1363157985066 13726238888 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 24 27 2481 24681 200
1363157993055 13560436666 C4-17-FE-BA-DE-D9:CMCC 120.196.100.99 18 15 1116 954 200
上面的数据对应的字段名称、意义及列索引号如下图所示。

我们要在Linux上使用Eclipse来进行开发,所以我们要先从Eclipse官网下载Linux版本的Eclipse,具体请参考:http://blog.csdn.net/u012453843/article/details/52582846这篇文章来下载,只是选择的版本是Linux而已。下载完之后我们通过FileZilla工具把包上传到Linux系统的root根目录下(如果不知道怎么上传,请参考:http://blog.csdn.net/u012453843/article/details/52422736这篇文章进行操作),由于后面用到的Maven仓库是m2.tar.gz,因此eclipse的版本不能太高,我原来用的是JEE Mars(4.5)版本,新建Maven工程时老是pom.xml报错,说是找不到2.6版本的maven-resources-plugin.jar包。我们看看m2文件夹下是否有2.6版本,如下图所示,发现确实没有。

因此为了避免这种情况的发生,我们需要使用合适的JEE版本进行开发,这里我们使用JEE Kepler(4.3)版本(这个版本的Eclipse大家也可以直接到:http://pan.baidu.com/s/1pLD5VLp这个地址进行下载)。如下图所示。
我们在Linux系统的root根目录下看看我们刚才上传上来的文件是否存在,如下图所示,发现确实已经上传上来了。

接下来我们便要解压该压缩包了,解压我们使用命令:tar -zxvf eclipse-jee-kepler-SR2-linux-gtk-x86_64.tar.gz -C /usr/local/然后按回车,便开始解压了,解压成功之后,我们想要在Linux系统上创建Eclipse的快捷方式(这样的话我们操作非常方便),创建快捷方式的步骤如下:
1.在桌面右键,在右键菜单中点击“Create Launcher”,如下图所示。
2.点击上图的"Create Launcher..."之后,会进入如下图所示界面,Name我们填上eclipse,Command我们点击它后面的"Browse..."按钮。

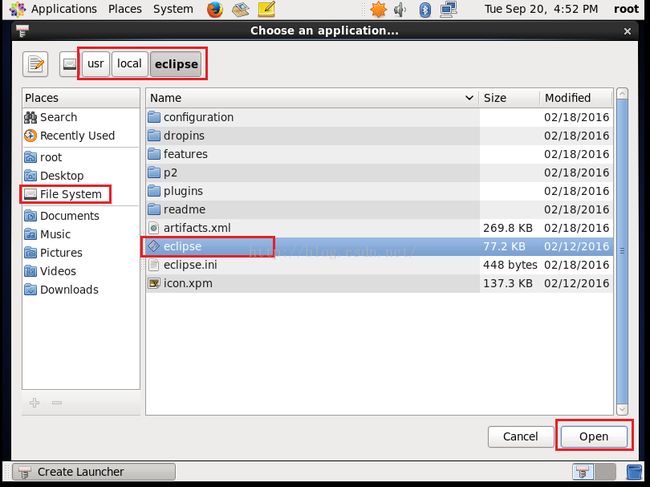
3.点击上图的"Browse..."按钮之后我们会看到如下图所示的界面,我们先点击左侧的"File System"---->然后在右侧的文件列表中点击"usr"---->然后在"usr"的子目录下点击"local"------>然后在"local"的子目录下点击"eclipse"------->在"eclipse"文件夹下我们发现有一个eclipse文件,我们选中它,然后点击图片下端的"open"按钮。
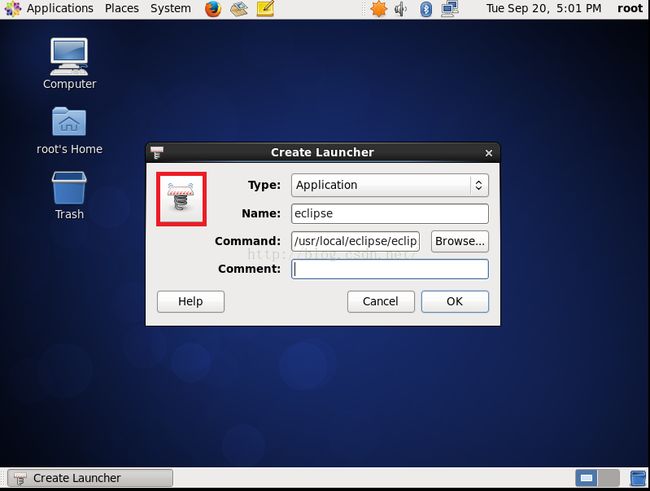
4.接下来我们来更改一下Launcher默认给我提供的快捷键图标,因为默认提供的是一个弹簧,如下图所示,我们点击那个图标。
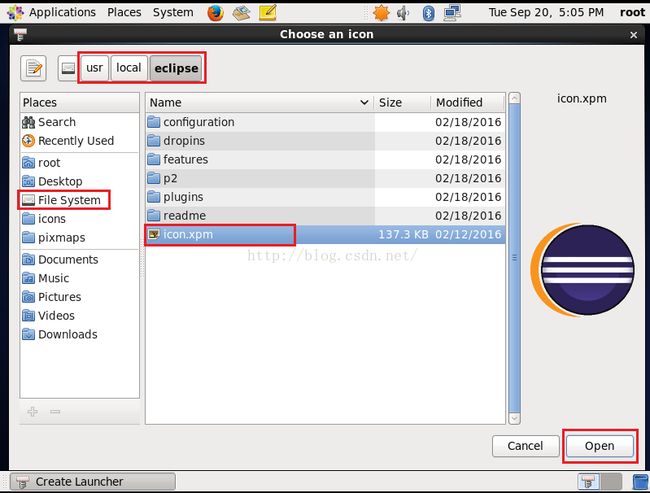
5.点击那个弹簧图标之后,会弹出一个窗口,我们依然选择跟第3步一样的目录,在该目录下有一个eclipse自带的logo,如下图所示,我们点击图中的icon.xpm,然后点击"open"按钮。
6.我们选择eclipse的默认logo之后如下图所示,发现原来的弹簧图标被取代了,我们点击"OK"按钮。

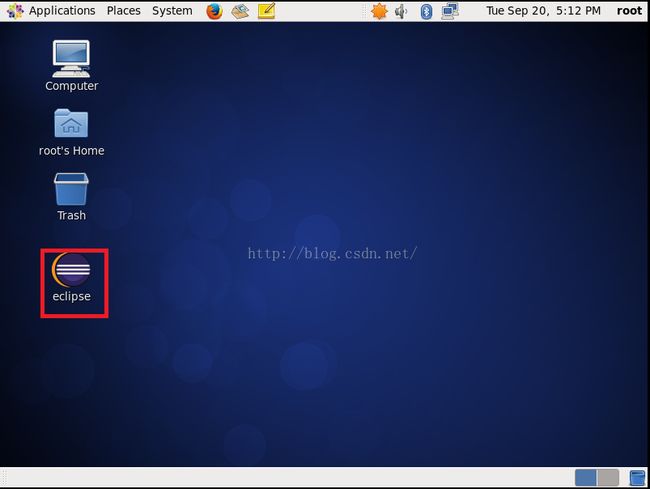
7.最后我们再来看看桌面,发现我们已经成功创建了Eclipse的快捷图标。
创建好了Eclipse,就跟我们在Windows下开发一样了,由于现在Maven比较火,所以我们来学习一下如何创建一个Maven工程并且用Maven来管理我们的jar包。
既然Maven可以帮我们自动关联相关的jar包,那我们就得有jar包让它管理啊,Maven所要管理的jar包都在一个压缩包m2.tar.gz当中,大家如果没有这个压缩包的话可以去这个地址:http://pan.baidu.com/s/1c1IvLg0进行下载。
下载完之后我们通过FileZilla工具把这个压缩包上传到我们的Linux系统的root根目录下,不懂上传的,可以参考:http://blog.csdn.net/u012453843/article/details/52422736这篇文章进行上传。
上传到root根目录下之后,我们查看一下文件列表,发现确实已经上传上来了,如下图所示。

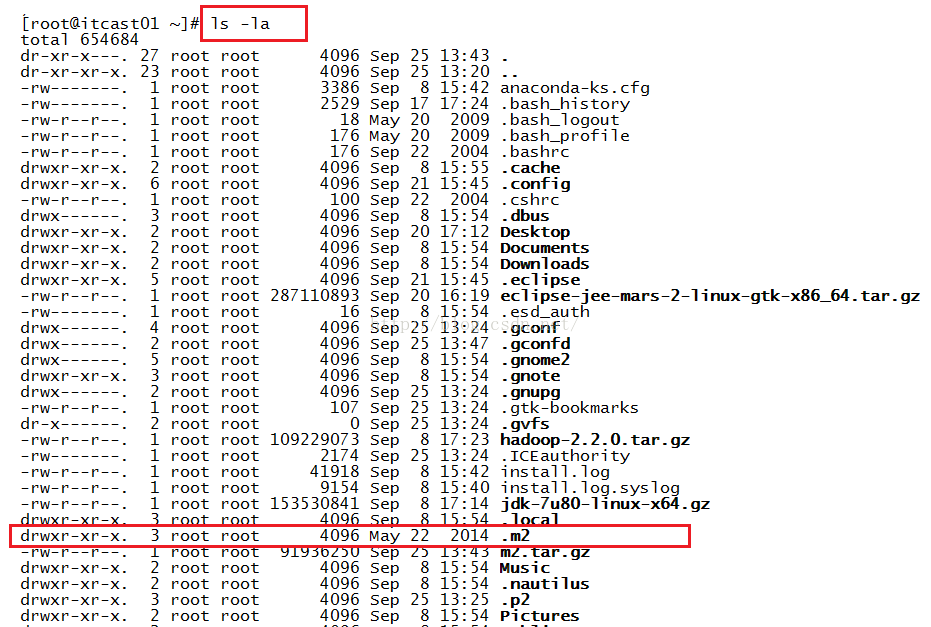
解下来我们使用tar -zxvf m2.tar.gz命令来解压该文件,解压完之后,我们查看解压完后的文件.m2,这个文件是个隐藏文件,因此我们得通过命令:ls -la来查看,如下图所示。
我们接下来看一下某一个文件夹的jar包。当然这只是看了一个文件夹下的jar包。大家可以看一下其他文件夹下的jar包。

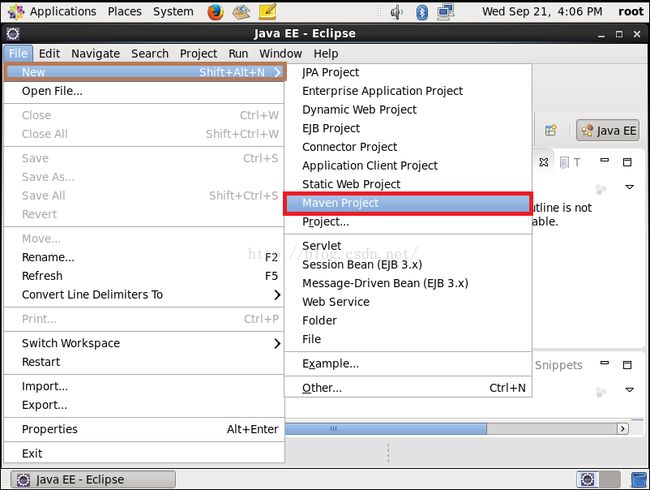
我们双击打开Eclipse,然后点击"File"--->"New"----->"Maven Project",如下图所示
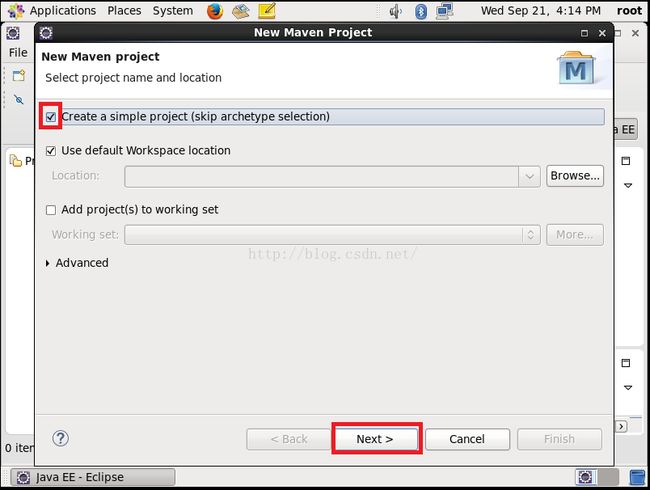
点击上图的"Maven Project"之后,我们会进入到如下图所示界面
点击上图"Next"之后,我们进入到如下图所示界面,Artifact Id是我们的工程名,我们分别起个名字,然后点击"Finish"

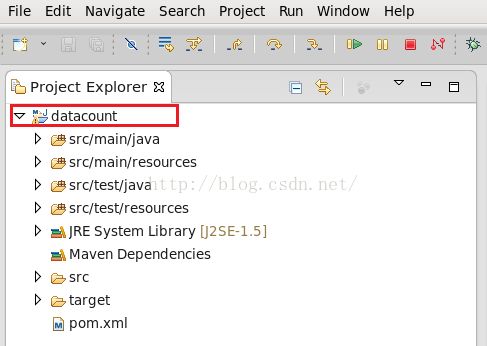
点击上图的"Finish"之后我们便创建好了一个Maven工程,如下图所示
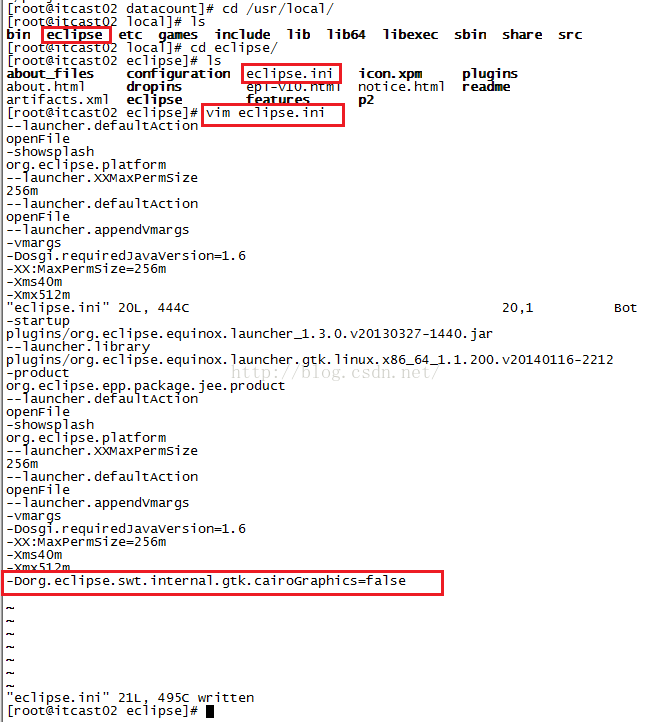
接下来我们修改pom.xml文件,在打开这个文件的时候,遇到了一个问题就是Eclipse会莫名其妙的关闭,不知道是什么原因,从网上找了一通,有篇文章给出的解决办法是到eclipse的安装目录下修改eclipse.ini文件,在这个文件的末尾加上:-Dorg.eclipse.swt.internal.gtk.cairoGraphics=false这么一句话,操作步骤如下图所示。
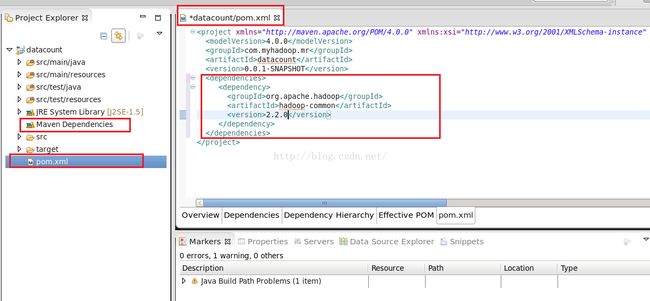
我们再次打开Eclipse,修改pom.xml文件,加入hadoop的配置,如下图所示,我们注意一下,在我点保存pom.xml文件之前,我们发现左侧文件列表中Maven Dependencies下什么文件也没有,看下图。
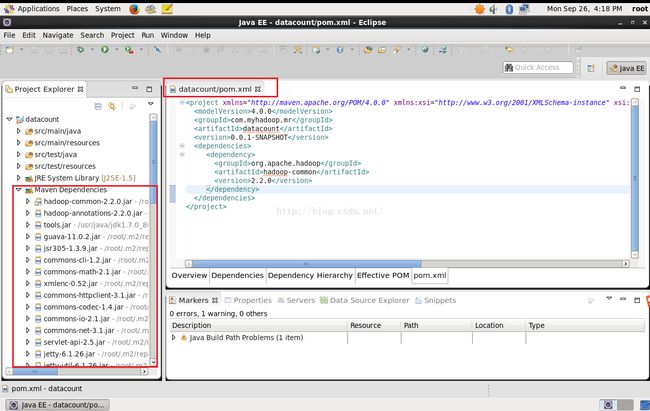
点击保存pom.xml文件之后,Maven会自动帮我们引进来我们所需要的jar包,如下图所示
接下来我们再来配置另外一个依赖,两个配置如下。
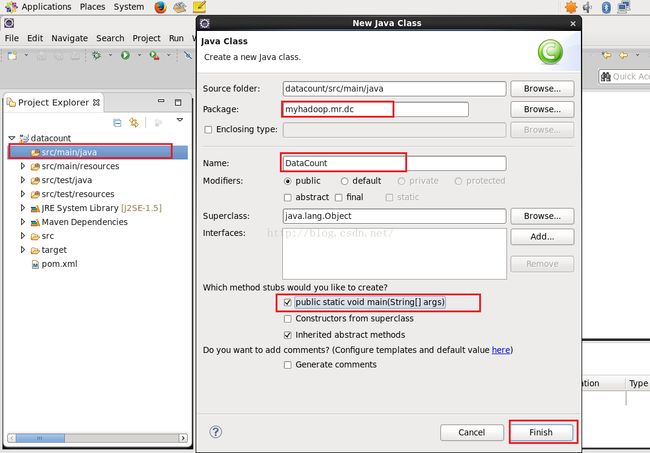
配置完之后我们便开始写程序了,首先我们在src/main/java目录下新建一个类DataCount,如下图所示
接下来我们便在DataCount类里面写内容了,有个问题需要先解决的是代码自动提示功能,由于Linux系统与Windows系统有差异,我们在输入syso之后按“Alt”+“/”并没有像在Windows系统上那样自动给我们补全,如下图所示。

接下来我们来解决这个不会自动补全的问题,我们点击“Windows”--------->然后点击"Refrences"--------->在弹出的对话框中输入keys------->点击搜索出来的Keys--------->在右侧搜索框输入"content"---------->下面搜索的结果第一行是"Content Assist",下面Binding的内容默认是Ctrl+Space,这不是我们所熟悉的快捷方式。
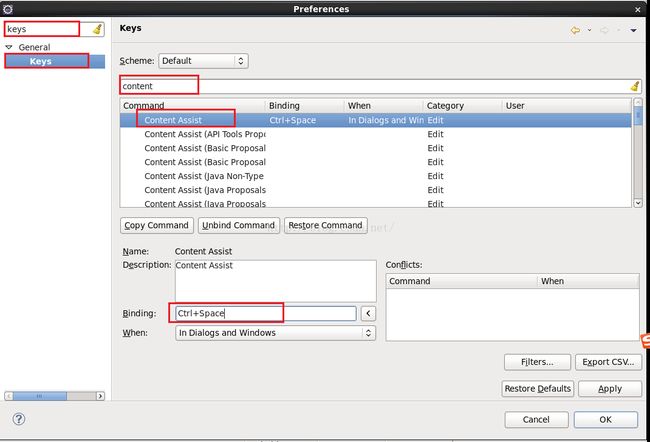
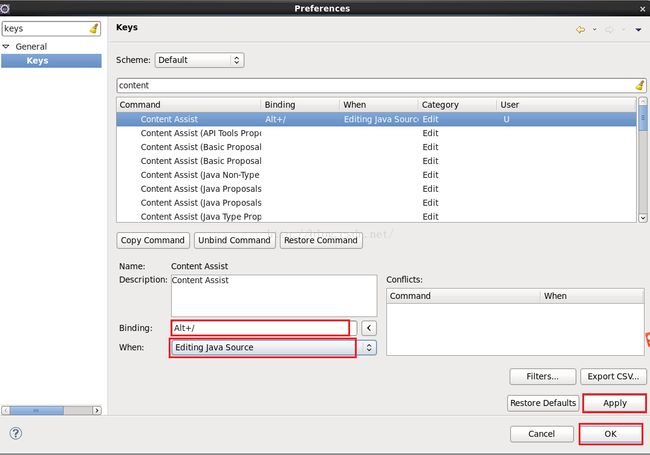
我们把上图的Binding的内容改成"Alt"+"/",When我们选择"Edting Java Source"。其中Binding这一栏的内容"Alt"+"/"不是手写进去的,因为无法手写,而是先按"Alt"键,按住不放,接着按"/"键,就会出现"Alt"+"/"了。配完之后我们先点击"Apply"然后点击"OK",这时我们再输入syso之后按"Alt"+"/"快捷键会发现已经可以自动补全了!
接着我们来写程序,由于我们要输出的结果是上行流量、下行流量、总流量,一个变量无法处理,因此我们需要定义一个Bean类来存储我们的结果,Bean代码如下。
import java.io.DataOutput;
import java.io.IOException;
//手机号
private String telNo;
//上行流量
private long upPayLoad;
//下行流量
private long downPayLoad;
//总流量
private long totalPayLoad;
//注意:序列化和反序列化一定要注意类型和顺序,比如我们序列化的时候先序列化字符串telNo,反序列化的时候就应该先反序列化telNo
public void write(DataOutput out) throws IOException {
out.writeUTF(telNo);
out.writeLong(upPayLoad);
out.writeLong(downPayLoad);
out.writeLong(totalPayLoad);
}
//反序列化
public void readFields(DataInput in) throws IOException {
this.telNo=in.readUTF();
this.upPayLoad=in.readLong();
this.downPayLoad=in.readLong();
this.totalPayLoad=in.readLong();
}
public DataBean(){}
long totalPayLoad) {
super();
this.telNo = telNo;
this.upPayLoad = upPayLoad;
this.downPayLoad = downPayLoad;
this.totalPayLoad = upPayLoad+downPayLoad;
}
public String toString() {
return this.upPayLoad+"\t"+this.downPayLoad+"\t"+this.totalPayLoad;
}
return telNo;
}
this.telNo = telNo;
}
return upPayLoad;
}
this.upPayLoad = upPayLoad;
}
return downPayLoad;
}
this.downPayLoad = downPayLoad;
}
return totalPayLoad;
}
this.totalPayLoad = totalPayLoad;
}
}
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
Job job=Job.getInstance(conf);
job.setJarByClass(DataCount.class);
job.setMapperClass(DCMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(DataBean.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
job.setReducerClass(DCReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(DataBean.class);
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
public static class DCMapper extends Mapper
Text text=null;
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line=value.toString();
String[] fields=line.split("\t");
String telNo=fields[1];
long up=Long.parseLong(fields[8]);
long down=Long.parseLong(fields[9]);
DataBean bean=new DataBean(telNo, up, down);
text=new Text(telNo);
context.write(text,bean);
}
}
public static class DCReducer extends Reducer
protected void reduce(Text key, Iterable
throws IOException, InterruptedException {
long up_sum=0;
long down_sum=0;
for(DataBean bean:v2s){
up_sum+=bean.getUpPayLoad();
down_sum+=bean.getDownPayLoad();
}
DataBean bean=new DataBean(key.toString(), up_sum, down_sum);
context.write(key, bean);
}
}
}
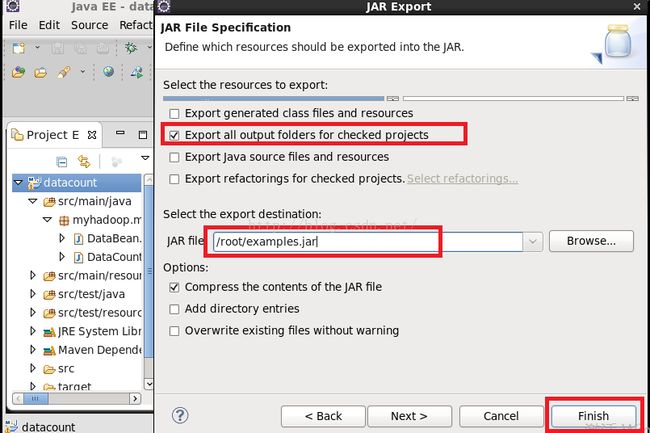



至此,本小节课终于学完了。