SparkStreaming消费Kafka项目实战(JAVA版)
原文连接 http://notes.itennishy.com/article/43
一 项目需求
1、统计用户访问直播的uv数、pv数?
2、统计用户跳转直播间的统计排名,即我的粉丝从哪个直播间过来到哪个直播间去?
3、统计评论数和评论人数?
4、统计引导进店数和引导进店人数?
5、直播数据查询等。
二 整体方案设计图
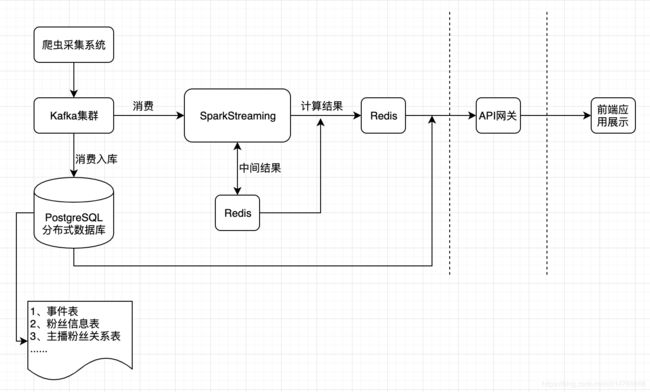
三 开发过程中关键点总结
3.1 过程优化
1、采用队列方式,通过队列进出的方式来监控主播和粉丝的流向,最后将结果存入PostgreSQL中,提供查询。
//监控的主播ID
private static HashSet<String> MonLiveId = new HashSet<>();
//正在直播的观看用户ID
private static HashSet<String> AccessingUser = new HashSet<>();
//已经访问过正在直播的观看用户ID,还未离开直播间
private static HashSet<String> AccessedUser = new HashSet<>();
//已经访问过正在直播的观看用户ID,已离开直播间
private static HashSet<String> DepartureUser = new HashSet<>();
//历史访问直播间ID
private static List<String> HistoryAccess = new ArrayList<>();
//粉丝离开去的直播间ID
private static List<String> DepartureAccess = new ArrayList<>();
结论:用户在第一次访问直播间的时候会出现查询库的问题,如果大量第一次监控到的用户涌现,发现查询库的效率很慢,导致数据大量积压,好处是系统会逐渐趋于稳定。
2、使用updateStateByKey处理历史数据
JavaPairDStream<String, String> user = userVisit.updateStateByKey(new Function2<List<String>, Optional<String>, Optional<String>>() {
private static final long serialVersionUID = 1L;
@Override
public Optional<String> call(List<String> v1, Optional<String> v2) throws Exception {
String updatedValue = "";
if (v2.isPresent()) {
updatedValue = v2.get();
}
for (String value : v1) {
if (updatedValue.equals(""))
updatedValue = value;
else
updatedValue += "#" + value;
}
return Optional.of(updatedValue);
}
});
结论:一旦存储的周期变长,算子执行的效率越来越慢,无论该批次中是否存在key都会更新所有的状态state信息。效率无法保证,无法满足要求。
3、使用mapWithState来处理历史数据
Function3<String, Optional<String>, State<String>, Tuple2<String, String>> mappingFunction =
new Function3<String, Optional<String>, State<String>, Tuple2<String, String>>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, String> call(String key, Optional<String> value, State<String> curState) throws Exception {
String curValue = "";
if (curState.isTimingOut()) {
LOG.info(key + " is time out");
} else {
if (value.isPresent()) {
curValue = value.get();
if (curState.exists()) {
String str = curState.get() + "#" + curValue;
HashSet<String> set = new HashSet<>();
for (String e : str.split("#")) {
set.add(e);
}
List<String> tempList = new ArrayList<>(set);
Collections.sort(tempList);
String tmp = org.apache.commons.lang.StringUtils.join(tempList.toArray(), "#");
if (!curState.get().equals(tmp)) {
curState.update(tmp);
int index = 0;
for (int i = 0; i < tempList.size(); i++) {
if (tempList.get(i).equals(curValue)) {
index = i;
} else {
continue;
}
}
if (tempList.size() == 1) {
return new Tuple2<>(key, tempList.get(index));
} else if (index == 0 && tempList.size() != 1) {
return new Tuple2<>(key, tempList.get(index) + "#" + tempList.get(index + 1));
} else if (tempList.size() - index == 1) {
return new Tuple2<>(key, tempList.get(index - 1) + "#" + tempList.get(index));
} else {
return new Tuple2<>(key, tempList.get(index - 1) + "#" + tempList.get(index) + "#" + tempList.get(index + 1));
}
} else {
LOG.info("数据有重复不需要更新,不需要更新");
}
} else {
curState.update(curValue);
}
}
}
return new Tuple2<>(key, curValue);
}
};
JavaMapWithStateDStream<String, String, String, Tuple2<String, String>> mapWithStateDStream =
userVisit.mapWithState(StateSpec.function(mappingFunction));
结论:只会更新本批次中存在的key的状态,不会更新所有的state信息。比updateStateByKey效率有明显提升,但是我们需要存取所有的批次信息,后期仍然无法提供可靠的效率保证。
4、使用redis作为中间缓存系统和结果缓存系统
过程一,使用foreach,redis写入连接过多;过程二,使用foreachPartition减少redis的连接;过程三,使用redis的Pipeline写入,一次请求多个命令,由于pipeline的原理是收集需执行的命令,到最后才一次性执行。所以无法在中途立即查得数据的结果(需待pipelining完毕后才能查得结果),这样会使得无法立即查得数据进行条件判断(比如判断是非继续插入记录)。
userCount.foreachRDD((VoidFunction2<JavaPairRDD<String, Integer>, Time>) (rdd, time) -> {
rdd.foreach((VoidFunction<Tuple2<String, Integer>>) tuple2 -> {
try(Jedis jedis = JedisPoolUtil.getResource()) {
jedis.set("EVENTS:"+ tuple2._1,tuple2._2.toString());
LOG.info("粉丝从" + tuple2._1.split("@")[0] + ",直播间到" + tuple2._1.split("@")[1] + ",共" + tuple2._2 + "人");
} catch (Exception e) {
e.printStackTrace();
}
});
});
wordsAndOne.foreachRDD((VoidFunction2<JavaPairRDD<String, Integer>, Time>) (rdd, time) -> {
rdd.foreachPartition((VoidFunction<Iterator<Tuple2<String, Integer>>>) arg0 -> {
try (Jedis jedis = JedisPoolUtil.getJedis()) {
while (arg0.hasNext()) {
Tuple2<String, Integer> tuple2 = arg0.next();
if(tuple2._2 == 1){
jedis.incr("RESULT:" + tuple2._1);
}else if(jedis.exists("RESULT:" + tuple2._1) && Integer.valueOf(jedis.get("RESULT:" + tuple2._1))>0){
jedis.decr("RESULT:" + tuple2._1);
}
LOG.info("写入redis成功:key= " + tuple2._1 + " value= " + tuple2._2);
}
} catch (Exception e) {
e.printStackTrace();
}
});
});
结论:SparkStreaming每5秒一个批次,每次大约处理15000左右的数据,满足要求,后期拓展性好。
5、使用Spark的背压机制和保证积压数据
SparkConf conf = new SparkConf().setAppName("YcKafka2SparkUserFlow").setMaster("local[3]");
conf.set("spark.streaming.stopGracefullyOnShutdown","true");
conf.set("spark.streaming.backpressure.enabled","true");
conf.set("spark.streaming.backpressure.initialRate","1000");
conf.set("spark.streaming.kafka.maxRatePerPartition","1000");
3.2 合理的Kafka拉取量(maxRatePerPartition重要)
对于Spark Streaming消费kafka中数据的应用场景,这个配置是非常关键的,配置参数为:spark.streaming.kafka.maxRatePerPartition。这个参数默认是没有上线的,即kafka当中有多少数据它就会直接全部拉出。而根据生产者写入Kafka的速率以及消费者本身处理数据的速度,同时这个参数需要结合上面的batchDuration,使得每个partition拉取在每个batchDuration期间拉取的数据能够顺利的处理完毕,做到尽可能高的吞吐量,而这个参数的调整可以参考可视化监控界面中的Input Rate和Processing Time
3.3 缓存反复使用的Dstream(RDD)
Spark中的RDD和SparkStreaming中的Dstream,如果被反复的使用,最好利用cache(),将该数据流缓存起来,防止过度的调度资源造成的网络开销。可以参考观察Scheduling Delay参数
3.4 设置合理的GC
长期使用Java的小伙伴都知道,JVM中的垃圾回收机制,可以让我们不过多的关注与内存的分配回收,更加专注于业务逻辑,JVM都会为我们搞定。对JVM有些了解的小伙伴应该知道,在Java虚拟机中,将内存分为了初生代(eden generation)、年轻代(young generation)、老年代(old generation)以及永久代(permanent generation),其中每次GC都是需要耗费一定时间的,尤其是老年代的GC回收,需要对内存碎片进行整理,通常采用标记-清楚的做法。同样的在Spark程序中,JVM GC的频率和时间也是影响整个Spark效率的关键因素。在通常的使用中建议:
--conf "spark.executor.extraJavaOptions=-XX:+UseConcMarkSweepGC"
3.5 设置合理的CPU资源数
CPU的core数量,每个executor可以占用一个或多个core,可以通过观察CPU的使用率变化来了解计算资源的使用情况,例如,很常见的一种浪费是一个executor占用了多个core,但是总的CPU使用率却不高(因为一个executor并不总能充分利用多核的能力),这个时候可以考虑让么个executor占用更少的core,同时worker下面增加更多的executor,或者一台host上面增加更多的worker来增加并行执行的executor的数量,从而增加CPU利用率。但是增加executor的时候需要考虑好内存消耗,因为一台机器的内存分配给越多的executor,每个executor的内存就越小,以致出现过多的数据spill over甚至out of memory的情况。
3.6 设置合理的parallelism
partition和parallelism,partition指的就是数据分片的数量,每一次task只能处理一个partition的数据,这个值太小了会导致每片数据量太大,导致内存压力,或者诸多executor的计算能力无法利用充分;但是如果太大了则会导致分片太多,执行效率降低。在执行action类型操作的时候(比如各种reduce操作),partition的数量会选择parent RDD中最大的那一个。而parallelism则指的是在RDD进行reduce类操作的时候,默认返回数据的paritition数量(而在进行map类操作的时候,partition数量通常取自parent RDD中较大的一个,而且也不会涉及shuffle,因此这个parallelism的参数没有影响)。所以说,这两个概念密切相关,都是涉及到数据分片的,作用方式其实是统一的。通过spark.default.parallelism可以设置默认的分片数量,而很多RDD的操作都可以指定一个partition参数来显式控制具体的分片数量。
在SparkStreaming+kafka的使用中,我们采用了Direct连接方式,前文阐述过Spark中的partition和Kafka中的Partition是一一对应的,我们一般默认设置为Kafka中Partition的数量。
3.7 使用Kryo优化序列化性能
这个优化原则我本身也没有经过测试,但是好多优化文档有提到,这里也记录下来。
在Spark中,主要有三个地方涉及到了序列化:
在算子函数中使用到外部变量时,该变量会被序列化后进行网络传输(见“原则七:广播大变量”中的讲解)。
将自定义的类型作为RDD的泛型类型时(比如JavaRDD,Student是自定义类型),所有自定义类型对象,都会进行序列化。因此这种情况下,也要求自定义的类必须实现Serializable接口。
使用可序列化的持久化策略时(比如MEMORY_ONLY_SER),Spark会将RDD中的每个partition都序列化成一个大的字节数组。
对于这三种出现序列化的地方,我们都可以通过使用Kryo序列化类库,来优化序列化和反序列化的性能。Spark默认使用的是Java的序列化机制,也就是ObjectOutputStream/ObjectInputStream API来进行序列化和反序列化。但是Spark同时支持使用Kryo序列化库,Kryo序列化类库的性能比Java序列化类库的性能要高很多。官方介绍,Kryo序列化机制比Java序列化机制,性能高10倍左右。Spark之所以默认没有使用Kryo作为序列化类库,是因为Kryo要求最好要注册所有需要进行序列化的自定义类型,因此对于开发者来说,这种方式比较麻烦。
以下是使用Kryo的代码示例,我们只要设置序列化类,再注册要序列化的自定义类型即可(比如算子函数中使用到的外部变量类型、作为RDD泛型类型的自定义类型等):
// 创建SparkConf对象。
val conf = new SparkConf().setMaster(...).setAppName(...)
// 设置序列化器为KryoSerializer。
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
// 注册要序列化的自定义类型。
conf.registerKryoClasses(Array(classOf[MyClass1], classOf[MyClass2]))
3.8 开启推测
//开启推测,避免单个task缓慢影响整体运行效率
conf = new SparkConf().setAppName("YcKafka2SparkUserFlow").setMaster("local[3]");
conf.set("spark.speculation","true");
conf.set("spark.speculation.interval","100");
conf.set("spark.speculation.quantile","0.9");
conf.set("spark.speculation.multiplier","1.5");
3.9 使用高性能的算子
这里是参考文章,其建议如下:
- 使用reduceByKey/aggregateByKey替代groupByKey
- 使用mapPartitions替代普通map
- 使用foreachPartitions替代foreach
- 使用filter之后进行coalesce操作
- 使用repartitionAndSortWithinPartitions替代repartition与sort类操作
四 最终代码
4.1 EventsCountUserAccessPath处理方法
package spark;
import bean.EventsMesgInfo;
import com.alibaba.fastjson.JSON;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.function.*;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.Time;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaInputDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka010.ConsumerStrategies;
import org.apache.spark.streaming.kafka010.KafkaUtils;
import org.apache.spark.streaming.kafka010.LocationStrategies;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import redis.clients.jedis.Jedis;
import scala.Tuple2;
import utils.JedisPoolUtil;
import java.sql.Timestamp;
import java.util.*;
public class EventsCountUserAccessPath {
private static final Logger LOG = LoggerFactory.getLogger(EventsCountUserAccessPath.class);
private static JavaStreamingContext jssc;
private static String brokers;
private static String topic;
private static String groupId;
private static SparkConf conf;
public static void main(String[] args) throws Exception {
if (args.length != 0) {
brokers = args[0];
topic = args[1];
groupId = args[2];
conf = new SparkConf().setAppName("YcKafka2SparkUserFlow");
} else {
brokers = "127.0.0.1:9092";
topic = "events-p3";
groupId = "consumer13";
conf = new SparkConf().setAppName("YcKafka2SparkUserFlow").setMaster("local[3]");
}
//控制sparkstreaming启动时,积压问题并设置背压机制,自适应批次的record变化,来控制任务的堆积
conf.set("spark.streaming.stopGracefullyOnShutdown", "true");
conf.set("spark.streaming.backpressure.enabled", "true");
conf.set("spark.streaming.backpressure.initialRate", "1000");
conf.set("spark.streaming.kafka.maxRatePerPartition", "1000");
//开启推测
// conf.set("spark.speculation","true");
// conf.set("spark.speculation.interval","100");
// conf.set("spark.speculation.quantile","0.9");
// conf.set("spark.speculation.multiplier","1.5");
jssc = new JavaStreamingContext(conf, Durations.seconds(5));
LOG.debug("JavaStreamingContext对象初始化成功");
Map<String, Object> kafkaParams = new HashMap<>();
kafkaParams.put("bootstrap.servers", brokers);
kafkaParams.put("key.deserializer", StringDeserializer.class);
kafkaParams.put("value.deserializer", StringDeserializer.class);
kafkaParams.put("group.id", groupId);
if(args.length!=0){
kafkaParams.put("enable.auto.commit", true);
}else {
kafkaParams.put("auto.offset.reset", "earliest");
kafkaParams.put("enable.auto.commit", false);
}
String kafkaTopics = topic;
String[] kafkaTopicsSplited = kafkaTopics.split(",");
Collection<String> topics = new HashSet<>();
for (String kafkaTopic : kafkaTopicsSplited) {
topics.add(kafkaTopic);
}
final JavaInputDStream<ConsumerRecord<String, String>> stream =
KafkaUtils.createDirectStream(
jssc,
LocationStrategies.PreferConsistent(),
ConsumerStrategies.<String, String>Subscribe(topics, kafkaParams)
);
LOG.debug("CreateDirectStream流,建立成功!");
JavaDStream<String> event = stream.flatMap(record -> {
List<String> list = new ArrayList<>();
try {
EventsMesgInfo mesginfo = JSON.parseObject(record.value(), EventsMesgInfo.class);
Timestamp timestamp = mesginfo.getStartTime();
String lid = mesginfo.getLiveId();
// if (mesginfo.getType().equals("finish")) {
// KafkaProducers_sparkstreaming.SendMessages(lid, "liveFinish:"+lid +":"+ mesginfo.getStartTime().getTime());
// }
String uid = mesginfo.getUser().getUserId();
if(!uid.equals("0")&&!uid.equals("null")) {
list.add(uid + "@" + timestamp.getTime() + ":" + lid);
}
return list.iterator();
} catch (Exception e) {
return list.iterator();
}
});
JavaPairDStream<String, String> userVisit = event
.mapToPair(e -> new Tuple2<>(e.split("@")[0], e.split("@")[1]));
// .filter(tuple2 -> (tuple2._1.equals("0") || tuple2._1 == null) ? false : true);
JavaPairDStream<String, String> userVisitGroup = userVisit.reduceByKey( (x, y) -> {
String str = x + "#" + y;
HashSet<String> set = new HashSet<>();
for (String e : str.split("#")) {
set.add(e);
}
List<String> tempList = new ArrayList<>(set);
Collections.sort(tempList);
return org.apache.commons.lang.StringUtils.join(tempList.toArray(), "#");
});
/**
* 获取用户访问的记录sortOldData,插入新访问的记录后的用户记录sortNewData
* 新产生的记录为(recored,1)
* 旧产生的记录为(recored,-1)
*
* 目的: 用新产生的访问路径 - 旧的用户访问路径 = 变化的访问路径
* 将变化的访问路径更新到redis中
*/
JavaDStream<String> userAccessOne = userVisitGroup.map( tuple2 -> {
try (Jedis jedis = JedisPoolUtil.getJedis()) {
Set<String> sortOldData = jedis.zrange("EVENTS:" + tuple2._1, 0, -1);
Map<String, Double> map = new HashMap<>();
for (String t : tuple2._2.split("#")) {
map.put(t.split(":")[1], Double.valueOf(t.split(":")[0]));
}
jedis.zadd("EVENTS:" + tuple2._1, map);
Set<String> sortNewData = jedis.zrange("EVENTS:" + tuple2._1, 0, -1);
if (sortNewData.equals(sortOldData)) {
return null;
}
List<String> data = new ArrayList<>();
String tmp = "";
for (String t : sortNewData) {
if (sortNewData.size() <= 1) {
return null;
} else {
if (tmp.equals("")) {
tmp = t;
} else {
data.add(tmp + "@" + t + ":" + "1");
tmp = t;
}
}
}
String tmp1 = "";
for (String t : sortOldData) {
if (sortOldData.size() <= 1) {
return null;
} else {
if (tmp1.equals("")) {
tmp1 = t;
} else {
data.add(tmp1 + "@" + t + ":" + "-1");
tmp1 = t;
}
}
}
return org.apache.commons.lang.StringUtils.join(data.toArray(), "#");
} catch (Exception e) {
e.printStackTrace();
}
return null;
}).filter(s -> s == null ? false : true)
.flatMap(s -> Arrays.asList(s.split("#")).iterator());
JavaPairDStream<String, Integer> wordsAndOne = userAccessOne
.mapToPair(e -> new Tuple2<>(e.split(":")[0], Integer.valueOf(e.split(":")[1])))
.reduceByKey((s1, s2) -> s1 + s2)
.filter(tuple2 -> tuple2._2 <= 0 ? false : true);
wordsAndOne.foreachRDD((VoidFunction2<JavaPairRDD<String, Integer>, Time>) (rdd, time) -> {
rdd.foreachPartition((VoidFunction<Iterator<Tuple2<String, Integer>>>) arg0 -> {
try (Jedis jedis = JedisPoolUtil.getJedis()) {
while (arg0.hasNext()) {
Tuple2<String, Integer> tuple2 = arg0.next();
if(jedis.exists("RESULT:" + tuple2._1)) {
jedis.set("RESULT:" + tuple2._1, String.valueOf(Integer.valueOf(jedis.get("RESULT:" + tuple2._1)) + Integer.valueOf(tuple2._2)));
jedis.expire("RESULT:" + tuple2._1,60*60*24*3);
}else {
jedis.set("RESULT:" + tuple2._1, String.valueOf(tuple2._2));
jedis.expire("RESULT:" + tuple2._1,60*60*24*3);
}
LOG.info("写入redis成功:key= " + tuple2._1 + " value= " + tuple2._2);
}
} catch (Exception e) {
e.printStackTrace();
}
});
});
// wordsAndOne.foreachRDD((VoidFunction2, Time>) (rdd, time) -> {
// rdd.foreachPartition((VoidFunction>>) arg0 -> {
// try (Jedis jedis = JedisPoolUtil.getJedis()) {
// while (arg0.hasNext()) {
// Tuple2 tuple2 = arg0.next();
//
// if(tuple2._2 == 1){
// jedis.incr("RESULT:" + tuple2._1);
// jedis.expire("RESULT:" + tuple2._1,60*60*24*3);
// }else if(jedis.exists("RESULT:" + tuple2._1) && Integer.valueOf(jedis.get("RESULT:" + tuple2._1))>0){
// jedis.decr("RESULT:" + tuple2._1);
// jedis.expire("RESULT:" + tuple2._1,60*60*24*3);
// }
// LOG.info("写入redis成功:key= " + tuple2._1 + " value= " + tuple2._2);
// }
// } catch (Exception e) {
// e.printStackTrace();
// }
// });
// });
jssc.start();
jssc.awaitTermination();
}
}
4.2 redis处理方法
package utils;
import redis.clients.jedis.*;
import java.io.Serializable;
/**
* 非切片链接池
* 备注:redis连接池 操作工具类
*/
public class JedisPoolUtil implements Serializable {
private static final long serialVersionUID = 264027256914939178L;
//Redis server
private static String redisServer = "127.0.0.1";
//Redis port
private static int port = 6379;
private static String password = "";
private static int MAX_ACTIVE = 1024;
private static int MAX_IDLE = 2000;
private static int MAX_WAIT = 10000;
private static int TIMEOUT = 10000;
private static JedisPool jedisPool = null;
static {
try {
JedisPoolConfig config = new JedisPoolConfig();
//设置最大连接数
config.setMaxTotal(MAX_ACTIVE);
//设置最大空闲数
config.setMaxIdle(MAX_IDLE);
//设置超时时间
config.setMaxWaitMillis(MAX_WAIT);
jedisPool = new JedisPool(config, redisServer, port,TIMEOUT);
// jedisPool = new JedisPool(config, redisServer,port,TIMEOUT,password);
} catch (Exception e) {
e.printStackTrace();
}
}
public synchronized static Jedis getJedis() {
try {
if (jedisPool != null) {
Jedis resource = jedisPool.getResource();
return resource;
} else {
return null;
}
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
public static void returnResource(final Jedis jedis) {
if (jedis != null) {
jedisPool.returnResource(jedis);
}
}
/**
* 批量删除大key
* public boolean delLargeHashKey(String key, int scanCount) throws Exception{
* boolean broken = false;
* Jedis jedis = pool.getSentineJedis();
* try{
* if (jedis!=null)
* {
* ScanParams scanParameters = new ScanParams();
*
* //一次获取500条,可自定义条数
* scanParameters.count(scanCount);
* String cursor = "";
* while ((!cursor.equals("0")) || (cursor == "0")){
*
* //使用hscan命令获取500条数据,使用cursor游标记录位置,下次循环使用
* ScanResult> hscanResult=jedis.hscan(key, cursor, scanParameters);
* cursor = hscanResult.getStringCursor();// 返回0 说明遍历完成
* List> scanResult = hscanResult.getResult();
* long t1 = System.currentTimeMillis();
* for(int m = 0;m < scanResult.size();m++){
* Map.Entry mapentry = scanResult.get(m);
* //System.out.println("key: "+mapentry.getKey()+" value: "+mapentry.getValue());
* jedis.hdel(key, mapentry.getKey());
* }
* long t2 = System.currentTimeMillis();
* System.out.println("删除"+scanResult.size()+"条数据,耗时: "+(t2-t1)+"毫秒,cursor:"+cursor);
* }
* return true;
* }
* return false;
* }catch (JedisException e) {
* broken = pool.handleJedisException(e);
* if (broken) {
* pool.closeResource(jedis, broken);
* }
* throw e;
* } finally {
* if (!broken && jedis != null) {
* pool.sentinel_close(jedis);
* }
* }
* }
*/
}
4.3 Pom依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.zhiboclub.aliyun</groupId>
<artifactId>YcSparkStreaming</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<properties>
<scala.version>2.11.8</scala.version>
<scala.binary.version>2.11</scala.binary.version>
<spark.connectors.version>1.0.4</spark.connectors.version>
<spark.version>2.4.3</spark.version>
<kafka.client.version>0.10.2.2</kafka.client.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>${kafka.client.version}</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.8</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>[1.2.31,)</version>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.5.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<id>scala-compile-first</id>
<phase>process-resources</phase>
<goals>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<minimizeJar>false</minimizeJar>
<shadedArtifactAttached>true</shadedArtifactAttached>
<artifactSet>
<includes>
<!-- Include here the dependencies you
want to be packed in your fat jar -->
<include>*:*</include>
</includes>
</artifactSet>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF
META-INF/*.DSA
META-INF/*.RSA
reference.conf
org.apache.maven.plugins
maven-dependency-plugin
copy-dependencies
prepare-package
copy-dependencies
${project.build.directory}/lib
false
false
true