Flume + Kafka + TridentStorm + Hbase项目实战
Flume + Kafka + TridentStorm + Hbase项目实战
版权声明:禁止转载,转载必究
标签(空格分隔): Storm项目
Write by Vin
1,项目简介
项目名称:基于Storm开发实现的实时网站流量统计
项目需求:通过Storm分析业务系统产生的网站访问日志数据,实时的统计出各种PV,包括:
每个URL单独的PV
网站外链PV
搜索关键字PV
项目技术架构:

本文目的旨在记录配置要点,以方便以后查看,故均按简单方式搭建环境,并且通过代码生成日志来模拟Nginx日志信息,并使用一层flume来进行该日志的监控
2,数据模拟
2.1数据模拟与环境搭建
1,生成日志
日志样例:
132.46.30.61 - - [1476285399264] "GET /list.php HTTP/1.1" 200 0 "-" "Mozilla/5.0 (Linux; Android 4.2.1; Galaxy Nexus Build/JOP40D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Mobile Safari/535.19" "-"
215.168.214.201 - - [1476285965677] "GET /edit.php HTTP/1.1" 200 0 "http://www.google.cn/search?q=spark mllib" "Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1" "-"通过日志样例,使用scala编程每个1s生成一条日志信息,代码如下:文件名称 NginxLogGenerator.scala
package org.project.storm.study
/**
* Created by hp-pc on 2016/10/16.
*/
import scala.collection.immutable.IndexedSeq
import scala.util.Random
/**
* Created by ad on 2016/10/13.
*/
class NginxLogGenerator {
}
object NginxLogGenerator{
/** user_agent **/
val userAgents: Map[Double, String] = Map(
0.0 -> "Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2;Tident/6.0)",
0.1 -> "Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2;Tident/6.0)",
0.2 -> "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1;Tident/4.0; .NETCLR 2.0.50727)",
0.3 -> "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
0.4 -> "Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
0.5 -> "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
0.6 -> "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)",
0.7 -> "Mozilla/5.0 (iPhone; CPU iPhone OS 7_)_3 like Mac OS X) AppleWebKit/537.51.1 (KHTML, like Gecko) Version/7.0 Mobile/11B511 Safari/9537.53",
0.8 -> "Mozilla/5.0 (Linux; Android 4.2.1; Galaxy Nexus Build/JOP40D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Mobile Safari/535.19",
0.9 -> "Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
1.0 -> " "
)
/**IP**/
val ipSliceList = List(10,28,29,30,43,46,53,61,72,89,96,132,156,122,167,
143,187,168,190,201,202,214,215,222)
/** url **/
val urlPathList = List(
"login.php","view.php","list.php","upload.php","admin/login.php","edit.php","index.html"
)
/** http_refer **/
val httpRefers = List(
"http://www.baidu.com/s?wd=%s",
"http://www.google.cn/search?q=%s",
"http://www.sogou.com/web?query=%s",
"http://www.yahoo.com/s?p=%s",
"http://cn.bing.com/search?q=%s"
)
/** search_keyword **/
val searchKeywords = List(
"spark",
"hadoop",
"yarn",
"hive",
"mapreduce",
"spark mllib",
"spark sql",
" IPphoenix",
"hbase"
)
val random = new Random()
/** ip **/
def sampleIp(): String ={
val ipEles: IndexedSeq[Int] = (1 to 4).map{
case i =>
val ipEle: Int = ipSliceList(random.nextInt(ipSliceList.length))
//println(ipEle)
ipEle
}
ipEles.iterator.mkString(".")
}
/**
* url
* @return
*/
def sampleUrl(): String ={
urlPathList(random.nextInt(urlPathList.length))
}
/**
* user_agent
* @return
*/
def sampleUserAgent(): String ={
val distUppon = random.nextDouble()
userAgents("%#.1f".format(distUppon).toDouble)
}
/** http_refer **/
def sampleRefer()={
val fra = random.nextDouble()
if(fra > 0.2)
"-"
else {
val referStr = httpRefers(random.nextInt(httpRefers.length))
val queryStr = searchKeywords(random.nextInt(searchKeywords.length))
referStr.format(queryStr)
}
}
def sampleOneLog() ={
val time = System.currentTimeMillis()
val query_log = "%s - - [%s] \"GET /%s HTTP/1.1\" 200 0 \"%s\" \"%s\" \"-\"".format(
sampleIp(),
time,
sampleUrl(),
sampleRefer(),
sampleUserAgent()
)
query_log
}
def main(args: Array[String]) {
while(true){
println(sampleOneLog())
Thread.sleep(1000)
}
}
}
执行示例:

2,模拟Nginx服务器
在Linux中新建一个目录mkdir ~/project_workspace
将NginxLogGenerator.scala文件拷贝到该新创建的目录中
编辑Linux脚本执行该scala文件:文件名为generator_log.sh:
代码如下
#!/usr/bin
SCALAC='/usr/bin/scalac'
$SCALAC NginxLogGenerator.scala
SCALA='/usr/bin/scala'
$SCALA /类所在路径/NginxLogGenerator >> nginx.log执行sh generator_log.sh,就会在该目录下生成nginx.log文件
可通过tail -f nginx.log查看,中断 CTRL + C 或者 jps获取pid然后使用kill -9 pid
查看执行效果:

2.2Flume搭建及配置
在vin01机器上,搭建并配置flume,新建一个Storm_project.conf文件,配置如下:
#exec source - memory channel - kafka sink/hdfs sink
a1.sources = r1
a1.sinks = kafka_sink hdfs_sink
a1.channels = c1 c2
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /home/vin/project_workspace/nginx.log //此处之前配置成~/...,然后一直运行不成功
# kafka_sink
a1.sinks.kafka_sink.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.kafka_sink.topic = nginxlog
a1.sinks.kafka_sink.brokerList = vin01:9092
a1.sinks.kafka_sink.requiredAcks = 1
a1.sinks.kafka_sink.batchSize = 20
a1.sinks.kafka_sink.channel = c1
# hdfs_sink
a1.sinks.hdfs_sink.type = hdfs
a1.sinks.hdfs_sink.hdfs.path = /flume/events/%y-%m-%d
a1.sinks.hdfs_sink.hdfs.filePrefix = nginx_log-
a1.sinks.hdfs_sink.hdfs.fileType = DataStream
a1.sinks.hdfs_sink.hdfs.useLocalTimeStamp = true
a1.sinks.hdfs_sink.hdfs.round = true
a1.sinks.hdfs_sink.hdfs.roundValue = 10
a1.sinks.hdfs_sink.hdfs.roundUnit = minute
a1.sinks.hdfs_sink.hdfs.rollInterval = 0
a1.sinks.hdfs_sink.hdfs.rollSize = 102400
a1.sinks.hdfs_sink.hdfs.rollCount = 0
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1 c2
a1.sinks.kafka_sink.channel = c1
a1.sinks.hdfs_sink.channel = c2
a1.sources.r1.selector.type = replicating2.3 使用kafka创建nginxlog topic,并测试
首先先保证zookeeper正常:zkServer.sh status
启动kafka集群:
[vin@vin01 kafka_2.10-0.8.2.1]$ bin/kafka-server-start.sh config/server.properties &
在实际生产中使用后台启动,命令如下:
$ nohup bin/kafka-server-start.sh config/server.properties > /dev/null 2>&1 & 创建topic:
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
查看topic:
bin/kafka-topics.sh --list --zookeeper localhost:2181
测试kafka集群:
开启生产者:[vin@vin01 kafka_2.10-0.8.2.1]$ bin/kafka-console-producer.sh --broker-list vin01:9092 --topic nginxlog
开启消费者:[vin@vin01 kafka_2.10-0.8.2.1]$ bin/kafka-console-consumer.sh --zookeeper vin01:2181 --topic nginxlog --from-beginning
同生产者窗口发送消息,观察消费者窗口能否收到
查看某个topic:$ bin/kafka-topics.sh --describe --zookeeper vin01:2181 --topic nginxlog
2.4 开启Flume agent进行监控日志
[vin@vin01 flume-1.5.0-cdh5.3.6-bin]$ bin/flume-ng agent -n a1 -c conf/ --conf-file conf/Storm_project.conf -Dflume.root.logger=INFO,console这是可以打开kafka的消费者观察日志数据是否进来,同时查看HDFS上是否生成日志数据
kafka consumer窗口:
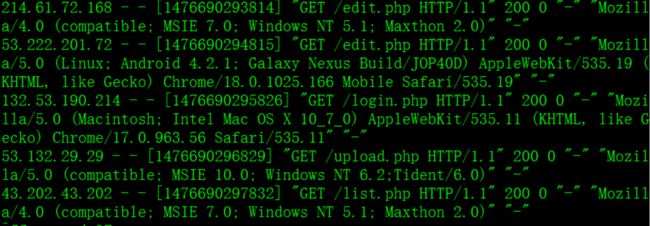
HDFS目录:

注:两层Flume的设置
第一层配置
# use an avro type file as a source
a2.sources = r2
a2.sinks = k2
a2.channels = c2
# configure the source
a2.sources.r2.channels = c2
a2.sources.r2.type = exec
a2.sources.r2.command = tail -F /home/vin/project_workspace/nginx.log
# Describe the sink
a2.sinks.k2.type = avro
a2.sinks.k2.channel = c2
a2.sinks.k2.hostname = 192.168.73.6
a2.sinks.k2.port = 44446
# configure the channel
a2.channels.c2.type = memory
a2.channels.c2.capacity = 10000
a2.channels.c2.transactionCapacity = 1000
# Bind the source and sink to the channel
第二层配置
#exec source - memory channel - kafka sink/hdfs sink
a1.sources = r1
a1.sinks =hdfs_sink kafka_sink
a1.channels = c1 c2
a1.sources.r1.type = avro
a1.sources.r1.channels = c1 c2
a1.sources.r1.bind = 192.168.73.6
a1.sources.r1.port = 44446
# kafka_sink
a1.sinks.kafka_sink.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.kafka_sink.topic = nginxlog
a1.sinks.kafka_sink.brokerList = vin01:9092,vin02:9092,vin03:9092
a1.sinks.kafka_sink.requiredAcks = 1
a1.sinks.kafka_sink.batchSize = 20
# hdfs_sink
a1.sinks.hdfs_sink.type = hdfs
a1.sinks.hdfs_sink.hdfs.path =hdfs://192.168.73.6:8020/flume/events/%y-%m-%d
a1.sinks.hdfs_sink.hdfs.filePrefix = nginx_log-
a1.sinks.hdfs_sink.hdfs.fileType = DataStream
a1.sinks.hdfs_sink.hdfs.useLocalTimeStamp = true
a1.sinks.hdfs_sink.hdfs.round = true
a1.sinks.hdfs_sink.hdfs.roundValue = 10
a1.sinks.hdfs_sink.hdfs.roundUnit = minute
a1.sinks.hdfs_sink.hdfs.rollInterval = 0
a1.sinks.hdfs_sink.hdfs.rollSize = 102400
a1.sinks.hdfs_sink.hdfs.rollCount = 0
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sinks.kafka_sink.channel = c2
a1.sinks.hdfs_sink.channel = c1
2.5 数据源
在flume监控的日志目录中,我们通过generator_log.sh脚本来源源不断的产生数据
2.6 总结
上面的步骤通过模拟nginx服务器源源不断的产生数据,通过flume收集数据并将数据写入HDFS用作离线分析和写入kafka中用作实时数据分析,下面步骤即是对这些日志数据使用Storm进行分析
3,数据分析
数据分析流程图

在idea上开发storm
主类的设计:NginxLogAnly.java
- 1,架构设计
Storm的核心Topology,这里使用Trident Storm
首先将类的整体架构设计出来:包括topology的构造,及config的设置;代码如下:
public class NginxLogAnaly {
public static void main(String[] args) {
// 构造Trident Topology operation流程
TridentTopology topology = new TridentTopology();
//.......
//.......
//.......
//.......
Config conf = new Config();
if (args == null || args.length <= 0){
// 本地IDE环境中执行
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("nginxlogAnaly",conf,topology.build());
}else{
try {
conf.setNumWorkers(4);
conf.setDebug(true);
// 设置当前Topology处理流程中正在处理的Tuple最大数量
conf.setMaxSpoutPending(200);
StormSubmitter.submitTopology(args[0],conf,topology.build());
} catch (AlreadyAliveException e) {
e.printStackTrace();
} catch (InvalidTopologyException e) {
e.printStackTrace();
}
}
}
}- 2,构建kafka spout
通过在trident storm kafka的jar包中可以找到两个函数:

TransactionalTridentKafkaSpout与OpaqueTridentKafkaSpout,其中OpaqueTridentKafkaSpout具有容错性,他们的区别在于事务控制的不同
那么创建Spout:
OpaqueTridentKafkaSpout tridentKafkaSpout = new OpaqueTridentKafkaSpout(???);创建好spout之后就要完成它,即?的位置是什么?通过查看 OpaqueTridentKafkaSpout 源码,它需要一个config配置项

config配置项包含了哪个kafka集群,哪个topic等信息,查看它的源码:

其中的第一个方法帮我们实现了clientId,即在底层自己生成了客户端id,其中的BrokerHost指定的其实是我们的zookeeper集群,因为storm是作为一个消费者而言的,topic是要消费的kafka集群上的某个topic,所以定义这两个对象:
BrokerHosts hosts = new ZkHosts("vin01:2181");
String topic = "nginxlog";然后再指定是否从头消费,和解析的格式,通常以字符串格式进行解析:
config.forceFromStart = false;
config.scheme = new SchemeAsMultiScheme(new StringScheme());整个spout就构造好了:
// 构造Trident Kafka Spout
BrokerHosts hosts = new ZkHosts("vin01:2181");
String topic = "nginxlog";
TridentKafkaConfig config = new TridentKafkaConfig(hosts,topic);
config.forceFromStart = false;
config.scheme = new SchemeAsMultiScheme(new StringScheme());
//TransactionalTridentKafkaSpout
OpaqueTridentKafkaSpout tridentKafkaSpout =
new OpaqueTridentKafkaSpout(config);
Stream stream = topology.newStream(SPOUT_ID,tridentKafkaSpout)
// {"str":"xxxxxx"}
.each(new Fields("str"),new PrintFilter())程序写到这里进行测试,即最后一行each方法,each方法的第一个参数表示它后面的参数能够获取哪些字符串,spout解析出来的是str:xxx格式的,所以自定义一个PrinterFilter()方法将它打印出来.该方法代码如下:
package com.vin.bigdata.storm.trident01;
import backtype.storm.tuple.Fields;
import storm.trident.operation.Filter;
import storm.trident.operation.TridentOperationContext;
import storm.trident.tuple.TridentTuple;
import java.util.List;
import java.util.Map;
/**
* 打印测试过滤器
* Created by ad on 2016/9/25.
*/
public class PrintFilter implements Filter {
/**
* 实现对Tuple进行过滤的逻辑
* @param tuple
* @return
*/
@Override
public boolean isKeep(TridentTuple tuple) {
Fields fields = tuple.getFields();
List将kafka集群启动,本地启动,flume启动,生成数据的脚本启动,本地测试结果:

kafka spout构造成功
关键是要每遍历一个目录结构就要执行一个hive语句,要写个循环
- 3,提取日志中的字段(使用each),定义一个函数LogParserFunction()来对这些字段解析(对原来的key-value对进行解析,产生新的key-value对,然后将新的key-value对追加到原key-value对后面):
注意:

Stream stream = topology.newStream(SPOUT_ID,tridentKafkaSpout)
// {"str":"xxxxxx"}
//.each(new Fields("str"),new PrintFilter())
// 随机重分区
//.shuffle()
//.global() // 全局 重分区
.batchGlobal() // 针对批次全局重分区 同一个批次内的tuple进入同一个分区,而不同批次内的记录进入不同分区
.each(new Fields("str"),new LogParserFunction(),new Fields(
// ip,time,url,httpRefer,keyWord,userAgent
IP,
TIME,
URL,
HTTPREFER,
KEYWORD,
USERAGENT))
// 设置有4个分区来执行LogParserFunction
.parallelismHint(4)
- 4,定义LogParserFunction类来提取需要的字段,代码如下:
package com.vin.bigdata.storm.webstatictis;
import backtype.storm.tuple.Values;
import storm.trident.operation.Function;
import storm.trident.operation.TridentCollector;
import storm.trident.operation.TridentOperationContext;
import storm.trident.tuple.TridentTuple;
import java.util.Map;
/**
*
* 日志文件解析Function
* 用于解析日志记录,并从中提取出 ip time url httpRefer keyword userAgent
* Created by ad on 2016/10/15.
*/
public class LogParserFunction implements Function {
private int partitionIndex ;
@Override
public void execute(TridentTuple tuple, TridentCollector collector) {
String logStr = tuple.getStringByField("str");
//132.46.30.61 - - [1476285399264] "GET /list.php HTTP/1.1" 200 0 "-" "Mozilla/5.0 (Linux; Android 4.2.1; Galaxy Nexus Build/JOP40D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Mobile Safari/535.19" "-"
//215.168.214.201 - - [1476285965677] "GET /edit.php HTTP/1.1" 200 0 "http://www.google.cn/search?q=spark mllib&b=c" "Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1" "-"
// 按空格 “ 进行split
// 正则表达式进行匹配
if(logStr != null){
// 按空格split
String[] logInfosByBlank = logStr.split(" ");
String ip = logInfosByBlank[0];
String timeStr = logInfosByBlank[3];
String time = timeStr.substring(1,timeStr.length() - 1);
String url = logInfosByBlank[5];
// 按引号切分
String[] logInfosByQuotes = logStr.split("\"");
String httpReferStr= logInfosByQuotes[3];
String httpRefer = "";
String keyWord = "";
String[] httpReferInfos = httpReferStr.split("/");
if(httpReferInfos.length >= 2){
httpRefer = httpReferInfos[2]; // www.google.cn
String params = httpReferInfos[3]; // search?q=spark mllib&b=c
String parameters = params.split("\\?")[1]; // q=spark mllib&b=c
keyWord = parameters.split("&")[0].split("=")[1]; // spark mllib
}
String userAgent = logInfosByQuotes[5];
// System.out.println("分区索引号:" + this.partitionIndex + "----->ip=" + ip + "-->time="+ time + "-->url=" + url+"-->httpRefer=" +
// httpRefer + "-->keyWord=" + keyWord + "-->userAgent=" + userAgent);
collector.emit(new Values(ip,time,url,httpRefer,keyWord,userAgent));
}
}
@Override
public void prepare(Map conf, TridentOperationContext context) {
// 获取到分区号
this.partitionIndex = context.getPartitionIndex();
}
@Override
public void cleanup() {
}
}
其最后发射的字段的key值分别是:ip,time,url,httpRefer,keyWord,userAgent,所以这里设置六个字段来进行接收:

然后再调用each打印测试一下:
.each(new Fields("str"),new LogParserFunction(),new Fields(
// ip,time,url,httpRefer,keyWord,userAgent
IP,
TIME,
URL,
HTTPREFER,
KEYWORD,
USERAGENT))
// 设置有4个分区来执行LogParserFunction
.parallelismHint(4)
.each(new Fields("str",IP,
TIME,
URL,
HTTPREFER,
KEYWORD,
USERAGENT),new PrintFilter())
;本地运行结果:

抽取出来的key-value对追加到原key-value对的后面了
![]()
- 5,统计pv,(以统计USERAGENT的pv为例)
这里需要统计的是基于浏览器类型和版本号的pv,这里就要用到project方法,称为投影,它能去除Tuple中后面用不到的key-value对,.所以这里调用project方法,参数中是我们要保留的字段:
// 1.统计浏览器类型、版本号的PV 时间 分钟
TridentState tridentState = stream.project(new Fields(TIME,USERAGENT))
// 解析USERAGENT,获取浏览器类型、版本
.each(new Fields(USERAGENT),new BrowerInfoGetFunction(),
new Fields(BROWSERNAME,BROWSERVERSION))
.each(new Fields(TIME),new TimeParserFunction("yyyy-MM-dd HH:mm"),
new Fields(YYYYMMDDHHMM))其中BrowerInfoGetFunction()方法是解析userAgent,获取浏览器类型BROWSERNAME和浏览器版本BROWSERVERSION.代码如下:
package com.vin.bigdata.storm.webstatictis;
import backtype.storm.tuple.Values;
import com.vin.bigdata.storm.util.UserAgentUtil;
import storm.trident.operation.Function;
import storm.trident.operation.TridentCollector;
import storm.trident.operation.TridentOperationContext;
import storm.trident.tuple.TridentTuple;
import java.util.Map;
/**
* 解析userAgent获取得到浏览器类型。版本
* Created by ad on 2016/10/15.
*/
public class BrowerInfoGetFunction implements Function {
@Override
public void execute(TridentTuple tuple, TridentCollector collector) {
String userAgent = tuple.getStringByField("userAgent");
String browserName = "";
String browserVersion = "";
if(userAgent != null && !userAgent.trim().equals("")) {
UserAgentUtil.UserAgentInfo userAgentInfo =
UserAgentUtil.analyticUserAgent(userAgent);
if(userAgentInfo != null){
browserName = userAgentInfo.getBrowserName();
browserVersion = userAgentInfo.getBrowserVersion();
}
}
if(!browserName.equals("") && !browserVersion.equals("")){
collector.emit(new Values(browserName,browserVersion));
}
}
@Override
public void prepare(Map conf, TridentOperationContext context) {
}
@Override
public void cleanup() {
}
}
在解析过程中用到了浏览器解析工具类,工具类代码如下:
package com.vin.bigdata.storm.util;
import java.io.IOException;
import cz.mallat.uasparser.OnlineUpdater;
import cz.mallat.uasparser.UASparser;
/**
* 解析浏览器的user agent的工具类,内部就是调用这个uasparser jar文件
*
* @author ibeifeng
*
*/
public class UserAgentUtil {
static UASparser uasParser = null;
// static 代码块, 初始化uasParser对象
static {
try {
uasParser = new UASparser(OnlineUpdater.getVendoredInputStream());
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 解析浏览器的user agent字符串,返回UserAgentInfo对象。
* 如果user agent为空,返回null。如果解析失败,也直接返回null。
*
* @param userAgent
* 要解析的user agent字符串
* @return 返回具体的值
*/
public static UserAgentInfo analyticUserAgent(String userAgent) {
UserAgentInfo result = null;
if (!(userAgent == null || userAgent.trim().isEmpty())) {
// 此时userAgent不为null,而且不是由全部空格组成的
try {
cz.mallat.uasparser.UserAgentInfo info = null;
info = uasParser.parse(userAgent);
result = new UserAgentInfo();
result.setBrowserName(info.getUaFamily());
result.setBrowserVersion(info.getBrowserVersionInfo());
result.setOsName(info.getOsFamily());
result.setOsVersion(info.getOsName());
} catch (IOException e) {
// 出现异常,将返回值设置为null
result = null;
}
}
return result;
}
/**
* 内部解析后的浏览器信息model对象
*
* @author 肖斌
*
*/
public static class UserAgentInfo {
private String browserName; // 浏览器名称
private String browserVersion; // 浏览器版本号
private String osName; // 操作系统名称
private String osVersion; // 操作系统版本号
public String getBrowserName() {
return browserName;
}
public void setBrowserName(String browserName) {
this.browserName = browserName;
}
public String getBrowserVersion() {
return browserVersion;
}
public void setBrowserVersion(String browserVersion) {
this.browserVersion = browserVersion;
}
public String getOsName() {
return osName;
}
public void setOsName(String osName) {
this.osName = osName;
}
public String getOsVersion() {
return osVersion;
}
public void setOsVersion(String osVersion) {
this.osVersion = osVersion;
}
@Override
public String toString() {
return "UserAgentInfo [browserName=" + browserName + ", browserVersion=" + browserVersion + ", osName="
+ osName + ", osVersion=" + osVersion + "]";
}
}
}
时间解析类TimeParserFunction的代码如下:
package com.vin.bigdata.storm.webstatictis;
import backtype.storm.tuple.Values;
import storm.trident.operation.Function;
import storm.trident.operation.TridentCollector;
import storm.trident.operation.TridentOperationContext;
import storm.trident.tuple.TridentTuple;
import java.text.DateFormat;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Map;
/**
* 解析时间戳得到具体到某个时间单位的时间字符串
* Created by ad on 2016/10/15.
*/
public class TimeParserFunction implements Function {
private String timeFormat ;
public TimeParserFunction(String timeFormat) {
this.timeFormat = timeFormat;
}
@Override
public void execute(TridentTuple tuple, TridentCollector collector) {
String timestamp = tuple.getStringByField("time");
Date date = new Date();
date.setTime(Long.valueOf(timestamp));
DateFormat df = new SimpleDateFormat(timeFormat);
String timeStr = df.format(date);
collector.emit(new Values(timeStr));
}
@Override
public void prepare(Map conf, TridentOperationContext context) {
}
@Override
public void cleanup() {
}
}
此时调用打印方法测试:
.each(new Fields(TIME,USERAGENT,BROWSERNAME,BROWSERVERSION,YYYYMMDDHHMM),new PrintFilter())本地测试结果:

….
….

抽出这些字段之后进行分组聚合,再调用打印方法测试,代码如下:
// 1.统计浏览器类型、版本号的PV 时间 分钟
TridentState tridentState = stream.project(new Fields(TIME,USERAGENT))
// 解析USERAGENT,获取浏览器类型、版本
.each(new Fields(USERAGENT),new BrowerInfoGetFunction(),
new Fields(BROWSERNAME,BROWSERVERSION))
.each(new Fields(TIME),new TimeParserFunction("yyyy-MM-dd HH:mm"),
new Fields(YYYYMMDDHHMM))
//.each(new Fields(TIME,USERAGENT,BROWSERNAME,BROWSERVERSION,YYYYMMDDHHMM),new PrintFilter())
.groupBy(new Fields(YYYYMMDDHHMM,BROWSERNAME,BROWSERVERSION))
.persistentAggregate(
new MemoryMapState.Factory(),
new Count(),
new Fields("pvOfBrowserByMinutes")
)
;
tridentState.newValuesStream().each(
new Fields(YYYYMMDDHHMM,BROWSERNAME,BROWSERVERSION,"pvOfBrowserByMinutes"),
new PrintFilter());
本地测试结果:

打印出的是每分钟,某个浏览器的某个版本的pv,这里是用内存来把结果存储起来
- 6,使用Hbase存储结果
首先将生成的结果通过调用Hbase api 来进行关联映射:
HBaseMapState.Options options =new HBaseMapState.Options();
options.columnFamily = "cf";
options.tableName = "nginxLogAnaly";
options.qualifier = "pvOfBrowserByMinutes"; //列标签
//Hbase会将groupBy的字段拼接起来作为rowkey
StateFactory hbaseStateFactory = HBaseMapState.opaque(options);这里需要将hbase的配置文件作为该项目的resource拷贝到idea中
在Hbase中创建好表之后,将代码中的memory存储替换为hbase存储

本地运行测试结果:

可以看到它的rowkey是拼接起来的,这样不利于查询,所以这里可以进行优化,在groupby之前我们将字段先按照我们想要的格式拼接起来,即在groupby之前再次调用each方法,自定义拼接函数,最终输出拼接好的字符串
- 附NginxLogAnaly.java代码
package com.vin.bigdata.storm.webstatictis;
import backtype.storm.Config;
import backtype.storm.LocalCluster;
import backtype.storm.StormSubmitter;
import backtype.storm.generated.AlreadyAliveException;
import backtype.storm.generated.InvalidTopologyException;
import backtype.storm.spout.SchemeAsMultiScheme;
import backtype.storm.tuple.Fields;
import com.vin.bigdata.storm.trident01.PrintFilter;
import org.apache.storm.hbase.trident.state.HBaseMapState;
import storm.kafka.BrokerHosts;
import storm.kafka.StringScheme;
import storm.kafka.ZkHosts;
import storm.kafka.trident.OpaqueTridentKafkaSpout;
import storm.kafka.trident.TridentKafkaConfig;
import storm.trident.Stream;
import storm.trident.TridentState;
import storm.trident.TridentTopology;
import storm.trident.operation.builtin.Count;
import storm.trident.state.StateFactory;
import storm.trident.testing.MemoryMapState;
/**
*
* 通过Trident实现网站流量统计分析程序
*
* 数据源 Kafka
*
* 1、IP的PV
* 2、url的PV
* 3、搜索引擎的PV
* 4、搜索关键字的PV
* 5、浏览器类型、版本的PV
* 6、终端类型的PV
* Created by ad on 2016/10/15.
*/
public class NginxLogAnaly {
private static final String SPOUT_ID = "tridentKafkaSpout";
private static final String IP = "ip";
private static final String TIME = "time";
private static final String URL = "url";
private static final String HTTPREFER = "httpRefer";
private static final String KEYWORD = "keyWord";
private static final String USERAGENT = "userAgent";
private static final String BROWSERNAME = "browserName";
private static final String BROWSERVERSION = "browserVersion";
private static final String YYYYMMDDHHMM = "yyyyMMddHHmm";
public static void main(String[] args) {
// 构造Trident Topology operation流程
TridentTopology topology = new TridentTopology();
// 构造流
// 构造Trident Kafka Spout
BrokerHosts hosts = new ZkHosts("vin01:2181");
String topic = "nginxlog";
TridentKafkaConfig config = new TridentKafkaConfig(hosts,topic);
config.forceFromStart = false;
config.scheme = new SchemeAsMultiScheme(new StringScheme());
//TransactionalTridentKafkaSpout
OpaqueTridentKafkaSpout tridentKafkaSpout =
new OpaqueTridentKafkaSpout(config);
Stream stream = topology.newStream(SPOUT_ID,tridentKafkaSpout)
// {"str":"xxxxxx"}
//.each(new Fields("str"),new PrintFilter())
// 随机重分区
//.shuffle()
//.global() // 全局 重分区
.batchGlobal() // 针对批次全局重分区 同一个批次内的tuple进入同一个分区,而不同批次内的记录进入不同分区
.each(new Fields("str"),new LogParserFunction(),new Fields(
// ip,time,url,httpRefer,keyWord,userAgent
IP,
TIME,
URL,
HTTPREFER,
KEYWORD,
USERAGENT))
// 设置有4个分区来执行LogParserFunction
.parallelismHint(4)
/*.each(new Fields("str",IP,
TIME,
URL,
HTTPREFER,
KEYWORD,
USERAGENT),new PrintFilter())*/
;
HBaseMapState.Options options =new HBaseMapState.Options();
options.columnFamily = "cf";
options.tableName = "nginxLogAnaly";
options.qualifier = "pvOfBrowserByMinutes"; //列标签
//Hbase会将groupBy的字段拼接起来作为rowkey
StateFactory hbaseStateFactory = HBaseMapState.opaque(options);
// 1.统计浏览器类型、版本号的PV 时间 分钟
TridentState tridentState = stream.project(new Fields(TIME,USERAGENT))
// 解析USERAGENT,获取浏览器类型、版本
.each(new Fields(USERAGENT),new BrowerInfoGetFunction(),
new Fields(BROWSERNAME,BROWSERVERSION))
.each(new Fields(TIME),new TimeParserFunction("yyyy-MM-dd HH:mm"),
new Fields(YYYYMMDDHHMM))
//.each(new Fields(TIME,USERAGENT,BROWSERNAME,BROWSERVERSION,YYYYMMDDHHMM),new PrintFilter())
.groupBy(new Fields(BROWSERNAME,BROWSERVERSION,YYYYMMDDHHMM))
.persistentAggregate(
// new MemoryMapState.Factory(),
hbaseStateFactory,
new Count(),
new Fields("pvOfBrowserByMinutes")
)
;
tridentState.newValuesStream().each(
new Fields(YYYYMMDDHHMM,BROWSERNAME,BROWSERVERSION,"pvOfBrowserByMinutes"),
new PrintFilter());
// 2.url的PV
//stream.each()
Config conf = new Config();
if (args == null || args.length <= 0){
// 本地IDE环境中执行
LocalCluster cluster = new LocalCluster();
cluster.submitTopology("nginxlogAnaly",conf,topology.build());
}else{
try {
conf.setNumWorkers(4);
conf.setDebug(true);
// 设置当前Topology处理流程中正在处理的Tuple最大数量
conf.setMaxSpoutPending(200);
StormSubmitter.submitTopology(args[0],conf,topology.build());
} catch (AlreadyAliveException e) {
e.printStackTrace();
} catch (InvalidTopologyException e) {
e.printStackTrace();
}
}
}
}
喜欢我的文章请关注微信公众号DTSpider
