solr的安装及简单使用
Solr是什么
Solr基于Lucene的全文搜索服务器。同时对其进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的全文搜索引擎
试验版的安装
默认你安装了jdk1.8
1.下载 http://archive.apache.org/dist/lucene/solr/7.1.0/solr-7.1.0.tgz
2.上传至master上的~/bigdata下,然后用下面的命令解压:
tar -xvf solr-7.1.0.tgz
3.cd solr-7.1.0
bin/solr start -e cloud //在solrCloud的模式下启动solr
一路回车就行了
4.jps验证
浏览器访问http://master:8983 验证,看到下面界面就表示启动成功了
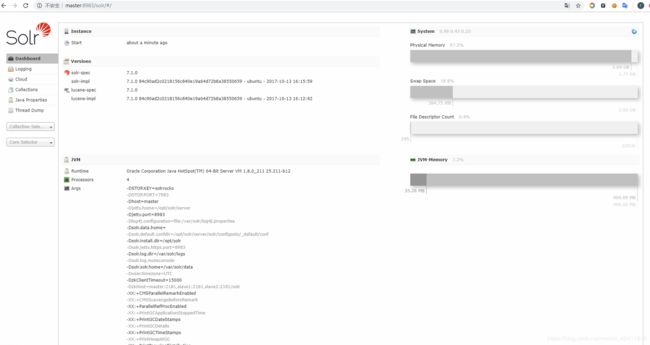
5.启动时报错信息原因及处理:
ERROR: Did not see Solr at http://localhost:8983/solr come online within 30 这是因为你的内存不够了,需要加内存
6.创建collection的时候报错处理
ERROR: Connect to localhost:7574 [localhost/127.0.0.1, localhost/0:0:0:0:0:0:0:1] failed: Connection ref used (Connection refused)
这是因为你都没有启动solr,需要先启动才行
简单的使用
1.创建一个collection
bin/solr create -c films_json -s 2 -rf 2
2.将example/films/films.json文件都上传到solr中对应的films_json来建立索引
bin/post -c films_json example/films/films.json
这时候你会发现它导数据的时候报错了,原因是因为,其中的name类型错误了,前面是浮点数,solr会自动推断类型,但是后面是字符串了,因此就会报错
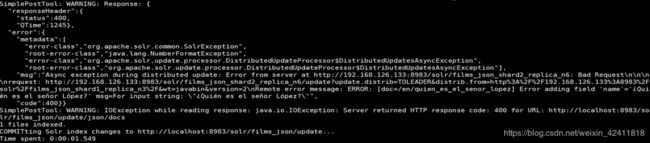
这个时候schema中只有默认的字段,这些默认的字段都是在:
/home/hadoop-jrq/bigdata/solr-7.1.0/server/solr/configsets/_default/conf/managed-schema中配置的
这个时候你会发现schema中多了不少字段,这个是solr从上面的json文件中推导出来的(在界面上也可以看到)
这个就是solr的schemaless模式,但是这种模式在生产上是不推荐使用的,我们应该关闭:
bin/solr delete -c films_json 删除刚刚创建了的
bin/solr create -c films_json -s 2 -rf 2 重新创建
// 关掉默认的推导
curl http://master:8983/solr/films_json/config -d ‘{“set-user-property”: {“update.autoCreateFields”:“false”}}’
// 这时候会报错,需要指定schema
bin/post -c films_json example/films/films.json => 这个时候查不到数据也没有schema,需要我们自己动手添加shema
修改schema增加字段的方式一:
curl -X POST -H ‘Content-type:application/json’ --data-binary ‘{“add-field”: {“name”:“name”, “type”:“text_general”, “multiValued”:false, “stored”:true}}’ http://master:8983/solr/films_json/schema
在界面上增加以下字段方式二:
directed_by -> text_general
initial_release_date -> string
genre -> text_general
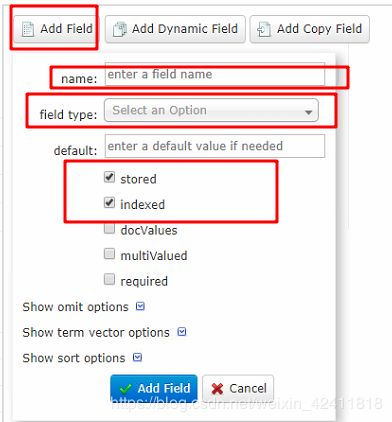
在这里如果勾选了索引,在导数据的时候就会切分数据,然后建索引
然后添加索引数据:
bin/post -c films_json example/films/films.json
3.数据的查询
查询films_json这个collection的全部数据:
curl “http://localhost:8983/solr/films_json/select?indent=on&q=:”
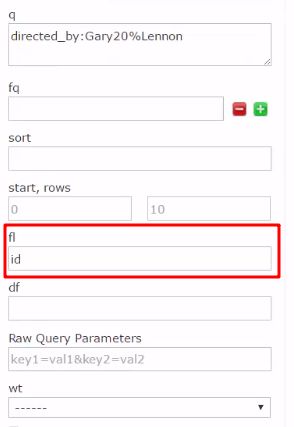
查询特定字段中带有directed_by:Gary20%Lennon的数据:(20%代表空格,在页面上查询的时候不能有20%,直接用空格代替就行了)
curl http://localhost:8983/solr/films_json/select?q=directed_by:Gary20%Lennon
查询带有directed_by:Gary20%Lennon的条目的id值:
curl “http://localhost:8983/solr/films_json/select?q=directed_by:Gary20%Lennon&fl=id”
联合查询,查询既directed_by包含Animation且name中包含Franklin的内容
curl http://localhost:8983/solr/films_json/select?q=+genre:Animation%20+name:Franklin
联合查询,查询既directed_by包含Animation但是name中不包含Franklin的内容
curl “http://localhost:8983/solr/films_json/select?q=+genre:Animation%20-name:Franklin”
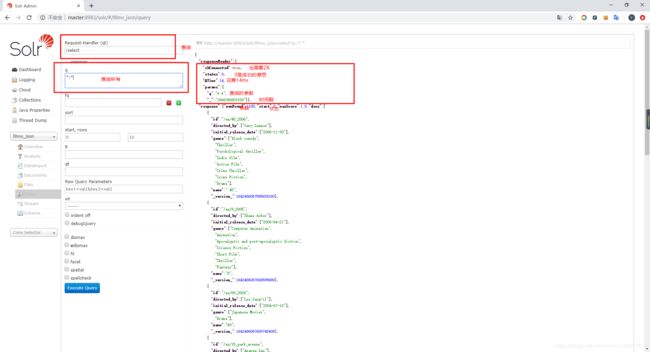
界面查询包含Gary的:

这个会查询出所有,这就是索引的概念了,因为之前我们勾上了索引,因此他会进行分词,每一个词都会是一个索引,solr会记住这个索引,查询的时候就会查出
界面联合查询(+包含 -不包含):
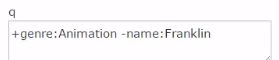
只显示ID:
集群安装solr
1.停止实验版的solr : bin/solr stop -all
在master机器上执行下面的命令
在sudo文件中增加JAVA的Path, visudo
![]()
用hadoop-jrq这个账号在master上执行下面的命令:
在sudo文件中增加hadoop-jrq的sudo权限
hadoop-jrq ALL=(ALL) ALL
tar xzf /home/hadoop-jrq/bigdata/solr-7.1.0.tgz solr-7.1.0/bin/install_solr_service.sh --strip-components=2
sudo bash ./install_solr_service.sh solr-7.1.0.tgz -u hadoop-jrq-s solr -p 8983
sudo vi /etc/default/solr.in.sh
ZK_HOST=“master:2181,slave1:2181,slave2:2181/solr”
SOLR_HOST=master
bash /opt/solr/bin/solr zk mkroot /solr -z master:2181 -> 只在master上执行
sudo service solr restart
scp -r /home/hadoop-jrq/bigdata/solr-7.1.0.tgz hadoop-jrq@slave1:~/bigdata
在slave1机器上执行下面的命令
在sudo文件中增加JAVA的Path, visudo
![]()
在sudo文件中增加hadoop-jrq的sudo权限
hadoop-jrq ALL=(ALL) ALL
用hadoop-jrq这个账号在slave1上执行下面的命令:
tar xzf /home/hadoop-jrq/bigdata/solr-7.1.0.tgz solr-7.1.0/bin/install_solr_service.sh --strip-components=2
sudo bash ./install_solr_service.sh solr-7.1.0.tgz -u hadoop-jrq-s solr -p 8983
sudo vi /etc/default/solr.in.sh
ZK_HOST=“master:2181,slave1:2181,slave2:2181/solr”
SOLR_HOST=slave1
sudo service solr restart
在master中去执行,没有相应的目录就创建
#因为我们需要这些配置
cp -r /opt/solr/server/solr/configsets/sample_techproducts_configs/conf/* /home/hadoop-jrq/hbase-course/solr/conf/
bash /opt/solr/server/scripts/cloud-scripts/zkcli.sh -zkhost master:2181/solr -cmd upconfig -confdir /home/hadoop-jrq/hbase-course/solr/conf -confname test-core
curl “http://master:8983/solr/admin/collections?action=CREATE&name=test-core&numShards=2&replicationFactor=2&maxShardsPerNode=2&collection.configName=test-core”
看到下面的界面就说明成功了!
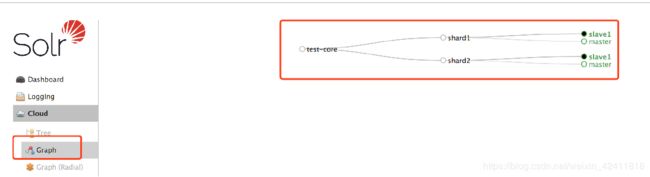
设置开机不启动
sudo chkconfig solr off
hbase结合solr创建二级索引
文字解释参考:https://blog.csdn.net/zhenzhendeblog/article/details/52911676
代码案例:
import java.util.UUID
import com.jrq.hbase.spark.HBaseContext
import org.apache.hadoop.hbase.client.Scan
import org.apache.hadoop.hbase.{CellUtil, HBaseConfiguration, TableName}
import org.apache.spark.sql.{Row, SaveMode, SparkSession}
import org.apache.spark.sql.types._
// 其实这就是创建索引的过程
object Spark2SolrIndexer {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.appName("Spark2SolrIndexer")
.master("local")
.getOrCreate()
// 首先需要读hbase里的数据
val hbaseConf = HBaseConfiguration.create()
val hbaseContext = new HBaseContext(spark.sparkContext, hbaseConf)
val scan = new Scan()
scan.setCaching(10) // 每次读多少数据
scan.setBatch(30) // 读多少列
// 拿到对应的数据,然后转成RDD
val sensorRDD = hbaseContext.hbaseRDD(TableName.valueOf("sensor"), scan)
import scala.collection.JavaConversions._
val sensorRowRDD = sensorRDD.mapPartitions { case iterator =>
val event = new Event()
// 对每条记录转成 row类型的RDD
iterator.flatMap { case (_, result) =>
val cells = result.listCells()
cells.map {cell =>
val finalEvent = new CellEventConvertor().cellToEvent(cell, event)
Row(UUID.randomUUID().toString, CellUtil.cloneRow(cell), finalEvent.getEventType.toString, finalEvent.getPartName.toString)
}
}
}
// 构建schema
val schema =
StructType(
StructField("id", StringType, false) ::
StructField("rowkey", BinaryType, true) ::
StructField("eventType", StringType, false) ::
StructField("partName", StringType, false) :: Nil)
val sensorDF = spark.createDataFrame(sensorRowRDD, schema)
import com.lucidworks.spark.util.SolrDataFrameImplicits._
// 需要这个是因为需要知道solr安装在哪里
val options = Map(
"zkhost" -> "master:2181,slave1:2181,slave2:2181/solr"
)
// 把数据写到sensor表里去
// sensorDF.write.options(options).solr("sensor")
// 每次都覆写
sensorDF.write.mode(SaveMode.Overwrite).options(options).solr("sensor")
}
}