sparkstreaming+Kafka性能优化
(一)sparkstreaming参数理解
使用SparkStreaming集成kafka时有几个比较重要的参数:
(1)spark.streaming.stopGracefullyOnShutdown (true / false)默认fasle
确保在kill任务时,能够处理完最后一批数据,再关闭程序,不会发生强制kill导致数据处理中断,没处理完的数据丢失
(2)spark.streaming.backpressure.enabled (true / false) 默认false
开启后spark自动根据系统负载选择最优消费速率
(3)spark.streaming.backpressure.initialRate (整数) 默认直接读取所有
在(2)开启的情况下,限制第一次批处理应该消费的数据,因为程序冷启动队列里面有大量积压,防止第一次全部读取,造成系统阻塞
(4)spark.streaming.kafka.maxRatePerPartition (整数) 默认直接读取所有
限制每秒每个消费线程读取每个kafka分区最大的数据量
一个启动spark任务的python脚本:
import sys,os
print("start spark tasks")
os.environ["PYSPARK_PYTHON"]="/usr/lib/python3/bin/python"
os.system('/opt/spark/spark-2.1.3-bin-hadoop2.7/bin/spark-submit '
' --master local[*] '
' --total-executor-cores 100 '
' --conf "spark.streaming.backpressure.enabled=true" '
' --conf "spark.streaming.backpressure.initialRate=1000" '
' --conf "spark.executor.extraJavaOptions=-XX:+UseConcMarkSweepGC" '
' --conf "spark.streaming.backpressure.enabled=true" '
' --conf "spark.streaming.kafka.maxRatePerPartition=200000"'
' --jars /jars/spark-streaming-kafka-0-8-assembly_2.11-2.1.3.jar '
' --executor-memory 150G'
' /code/src/com/Mysql/main.py'
)
print("finish")(二)测试问题记录
1.冷启动第一批数据划分过大,容易内存泄露从而程序异常退出
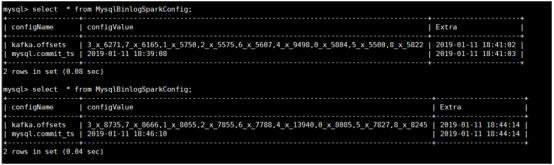
Extra为写入数据库的时间,configvalue为mysql日志产生时间,15分钟处理了将近2个小时间的数据。
参数:
sc=2s,其余参数置空为spark默认参数,从前5天的数据开始读取(kafka默认存储7天数据)。
我们将从kafka各个分区取得offset记录如表,可以观察到spark接kafka的数据只有个别分区才有,其他分区一直未0,这个是数据倾斜,问题在于maxwell生产者的向kafka只对个别分区抛数据时,稍后再说。我们先说冷启动,第一批数据量很大,后续很多任务在排队。

可以看到,冷启动,第一批数据量很大,后续很多任务在排队。

解决:
spark.streaming.backpressure.enabled=TRUE
spark.streaming.backpressure.initialRate设置一下
2.spark task数据不均匀
数据分布不均匀的情况下, 出现了部分task有数据,部分task却没有数据的情况, 导致机器的cpu资源没有得到充分利用。其实就是线上从kafka获取数据时, kafka中的分区数据分布不均, 导致部分task处理的数据量特别少,并未达到并行计算的效果。
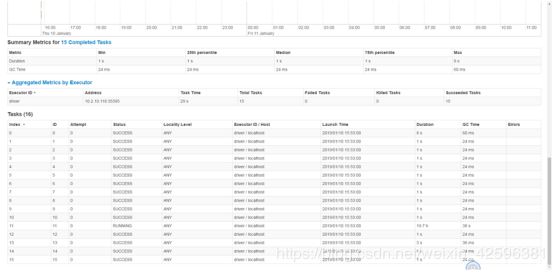
如上图,只有一个任务在运行,其余数据量很小或者没有。
分析从kakfa生产端写入到各个分区的数据为何不均匀,如何解决。
(1)原因分析
Kafka数据倾斜的问题一般是由于生产者使用的Partition接口实现类对分区处理的问题,一般是对key做hash之后,对分区数取模。当出现数据倾斜时,小量任务耗时远高于其它任务,从而使得整体耗时过大,未能充分发挥分布式系统的并行计算优势(参考Apache Kafka 0.10 技术内幕:数据倾斜详解)。
而使用Maxwell解析MySQL的Binlog发送到Kafka的时候,生产者是Maxwell,那么数据倾斜的问题明细就是Maxwell引起的了。官方解释:

(2)解决方法
1生产者
利用maxwell造成的分区不均现象,可以用参数设定一下:--producer_partition_by=primary_key
设置之后再启动maxwell,观察了下,9个分区写入数据增量差不多。
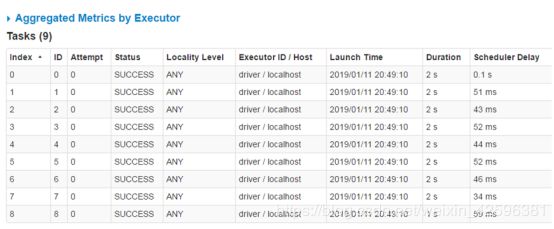
再次启动sparkstreaming,观察到各个任务都有执行,任务分配均匀。
对两个分区数为9和12的对比一下:
分区数9:数据量=2000
分区数12:数据量=2224

运行了一晚上以后,再查看数据量的记录表,各个分区写入的数据量差不多。问题解决


2.消费者:
利用DStream.reparation(partitionNum), 对DStream进行重新分区, 请注意, reparation()函数会对数据做shuffle, 这就相当于将数据分配到了其他机器上.这样就能提高并行度, 提高集群cpu资源利用率。
kvs.transform(storeOffsetRanges).repartition(16)
任务线程数变为16,能明显看到数据处理效率提高。

2万多的数据量只用了11s,但是数据顺序错乱了!!

数据的顺序被打乱了,对于数据库中的操作顺序错乱了。
3.任务本地等待时间

PROCESS_LOCAL 进程本地化:task要计算的数据在同一个Executor中
NODE_LOCAL 节点本地化:速度比 PROCESS_LOCAL 稍慢,因为数据需要在不同进程之间传递或从文件中读取
set('spark.locality.wait.process','2s')
set('spark.locality.wait.node','1s')
解释:
##经过2s,spark降低任务执行级别为node_local,再等待1s会接着降低级别,运行速度越来越慢。现在想让每一个task都能拿到最好的数据本地化级别,那么调优点就是等待时间加长。注意!如果过度调大等待时间,虽然为每一个task都拿到了最好的数据本地化级别,但是我们job执行的时间也会随之延长。

set('spark.locality.wait.process','200ms')
set('spark.locality.wait.node','100ms')

4有且一次消费
目前能实现一次消费是比较困难的,可以实现多次消费,在写表时要注意SQL语句判断下重复数据。
(1)insert into表示插入数据,数据库会检查主键(PrimaryKey),如果出现重复会报错;
(2)replace into表示插入替换数据,需求表中有PrimaryKey,或者unique索引的话,如果数据库已经存在数据,则用新数据替换,如果没有数据效果则和insert into一样;replace into 跟 insert 功能类似,不同点在于:replace into 首先尝试插入数据到表中,如果发现表中已经有此行数据(根据主键或者唯一索引判断)则先删除此行数据,然后插入新的数据。 2. 否则没有此行数据的话,直接插入新数据。原理:1. 首先判断数据是否存在; 2. 如果不存在,则插入;3.如果存在,则更新。
(3)REPLACE语句会返回一个数,来指示受影响的行的数目。该数是被删除和被插入的行数的和。如果对于一个单行REPLACE该数为1,则一行被插入,同时没有行被删除。如果该数大于1,则在新行被插入前,有一个或多个旧行被删除。如果表包含多个唯一索引,并且新行复制了在不同的唯一索引中的不同旧行的值,则有可能是一个单一行替换了多个旧行。
(4)insert ignore表示,如果中已经存在相同的记录,则忽略当前新数据,直接跳过;
5.堆积太多任务
堆积太多任务,若是任务过多超过spark处理的能力就会可能报错。
分析:
划红线的这一批数据附近处理时间达12s,而在12s内仍然每0.3s消费数据抛给spark,这时很多任务就会排队,但只要spark没有堆积过多的任务,且processtime(即第二列)小于0.3s,spark会追到最新的数据并处理。

任务过多报错!
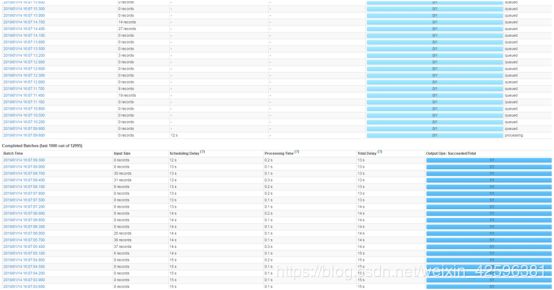

6.任务倾斜
如下图只有Index=3的任务在运行,其余的任务均在1-2s就运行完毕了。这个就是任务倾斜。
先查看数据是否发生倾斜,一般这个问题还是由于生产者向kafka中不同分区写入数据不均匀造成,解决参考数据倾斜。

(三)测试记录
(1)参数对比:
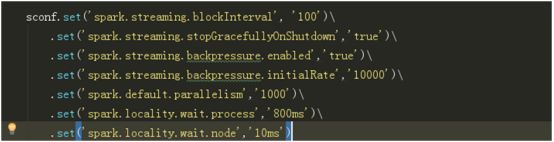
sc=1s

sc=0.3s,处理第一批积压的数据量为10万多,用了1.3min

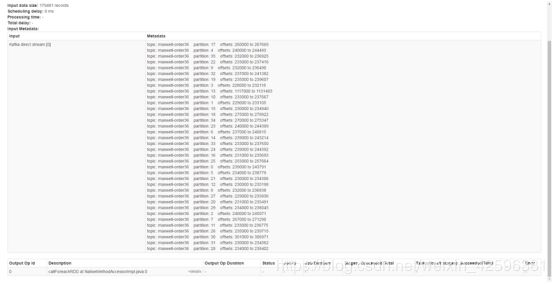
在此刻生产数据与消费数据的速率对比情况:
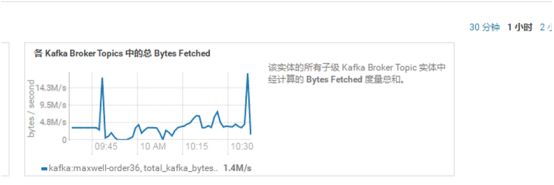
Maxwell向kafka中产生的的日志的速率在41.9K/s,消费速率在3.2M/,加上spark.streaming.backpressure.enabled=true这个参数,spark可以根据生产与消费的压力情况,自主选择最有消费速率。

追上来到最新的数据后。
休息日或者淡季的测试情况:
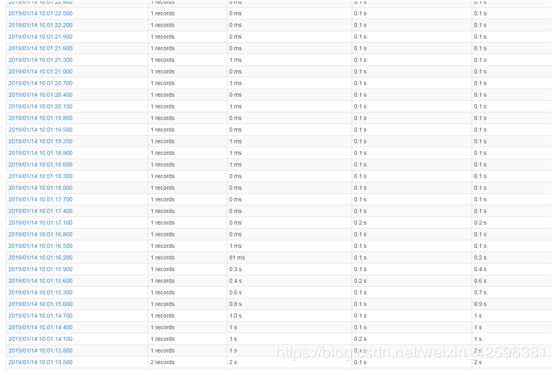
旺季情况,0.3秒内会产生1千多甚至1万多条记录。

(2)消费者速率
从头开始消费,加上这个参数,可以调节第一批数据量,避免第一批数据量过大从而内存溢出。
--conf "spark.streaming.backpressure.enabled=true”
--conf "spark.streaming.kafka.maxRatePerPartition=200000”
Spark数据切分情况:

此时观察到此刻消费速度在峰值,8.3M/s,动态调整消费速率是在spark.streaming.backpressure.enabled开启状态时生效。