论文阅读 - 《Neural Relation Extraction with Selective Attention over Instances》
作者:xg123321123
出处:http://blog.csdn.net/xg123321123/article/details/53218870
声明:版权所有,转载请联系作者并注明出处
1 问题定义
distant supervised 关系提取是一种从文本中提取关系事实的方法。
知识库是一种可以被用在问答系统和Web搜索中的三元组关系事实(e.g.,(Microsoft, founder, Bill Gates))的集合。
目前已有了一些大型知识库(knowledge base,KB),如freebase等,但这些远不能将大千世界的关系网络表示清楚。
所以需要更多的知识库。很多被用来构建知识库的方法都需要大量标注好的训练数据,这需要大量人力。
distant supervised关系提取则用来缓解这一尴尬局面。
distant supervised关系提取假设如果知识库中包含特定2个实体的某句话属于某种关系,那么所有包含这2个实体的句子都属于这种关系。
2 背景综述
- 对于偌大的知识库,难免会有一些错误的label,而distant supervised关系提取方法总是深受其害;
- 也有人尝试multi-instance学习来降低错误label的影响,但是由于这些方法都是用固有工具显式地提取特征,所以固有工具产生的错误会不断地传播;
- 大多数已有的深度学习方法需要句子级别的label,这使得深度学习在大规模知识库上的应用变得不太现实;
- 也有人尝试将multi-instance和深度学习结合起来实现distant supervised提取,然而这种方法在所有包含特定2个实体的句子中,只选取最有可能的一个来进行训练和预测,这就丢失了大部分信息。
3 灵感来源
- 运用attention机制来尽量减轻错误label的负面影响;
- 运用CNN将关系用sentence embedding的语义组合来表示,以此充分利用训练知识库的信息。
4 方法概述
- 给定句子集合 {x1,x2,...,xn} ,模型将会给出每种关系 r 的概率;
- 给定一个句子,使用CNN来构建其对应的向量;
- 然后使用句子级别的attention机制来选取对关系提取有影响的句子。
语句编码器
先将每个句子转化为稠密实数向量,然后利用卷积,池化和非线性转换等操作构建起对应的句向量,原理示意图如下。
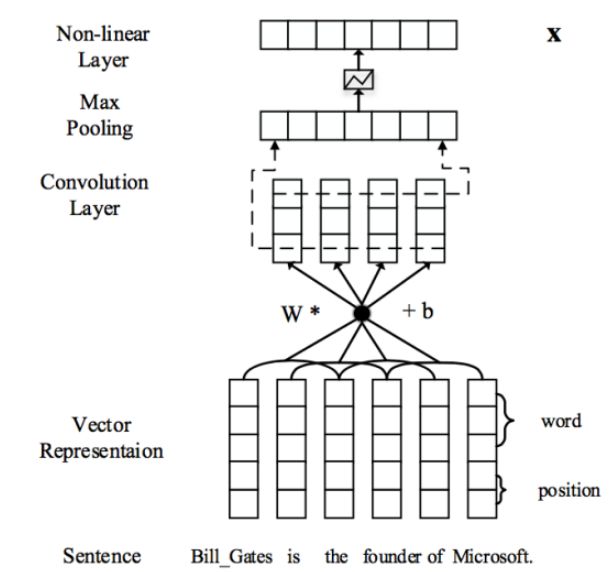
输入表示
- 输入为原始句子 x={w1,w2,...,wm} ;
- 用word2vec将原始句子中的每个单词转换为实数向量;
- 用每个单词分别和2个实体的距离构造2个位置向量;
- 一个原始句子就被表示为了一个向量序列 w⃗ ={w⃗ 1,w⃗ 2,...,w⃗ m} ,其中 wi∈Rd(d=da+db×2) , da 在文中取的3,而 db 取的1
卷积,池化和非线性操作
- 文本语句总是变长的,且对于最后关系分类比较重要的信息可能会出现句子的任何部分,所以需要将整个句子的信息都捕捉到;
- 本部分先对上面的向量序列 w⃗ ={w⃗ 1,w⃗ 2,...,w⃗ m} 用卷积操作得到局部特征,然后用池化操作联合所有局部特征得到一个固定长度的向量;
- 向量序列可以形式化地表示为向量序列 w⃗ 和一个卷积矩阵 W⃗ 的乘积,在向量序列 w⃗ 中,定义 w 个词嵌入为
qi={wi−l+1,wi−l+2,...wi},其中 (1≤i≤m+l−1) ,为了对齐,还同时使用了padding操作
- 所以卷积操作可以形式化为
pi=[W⃗ q⃗ +b⃗ ]i
- 接着对 pi 使用max pooling操作,具体来说,每个 pi 都被首尾两个实体分为了三部分 (pi1,pi2,pi3) ,对这三部分分开做max pooling
[x]ij=max(pij)再将三部分的结果 [x]i1,[x]i2,[x]i3 联合起来得到 [x]i
- 最后,对这固定长度的一系列 [x]i,(其中1≤i≤m+l−1) 使用双曲正切函数得到输出。
attention机制
给定一个实体对和其对应的关系,传统的方法在无标签的语料集中提取所有包含该实体对的句子,并认为这样的句子中实体也存在同样的关系。显而易见地,这种方法会因为一些噪音语料而影响训练效果
所以引入attention机制,给不同的语料赋予不同的权重,隐式地摒弃一些噪音语料,以此提升分类器的性能。
给包含某一实体及其关系的所有句子都分配权重,这个权重的大小代表着我们是否可以认为该句子包含着该种关系。
给定包含一个实体和n个句子的集合 S=x1,x2,...,xn ,将n个句子向量化表示为 x⃗ 1,x⃗ 2,...,x⃗ n ,加入attention机制时,权重定义为:
其中
函数 e 体现了一个句子对于该关系的match程度。
其中 x⃗ i 是句子向量, A 是表示权重的对角矩阵, r⃗ 是代表着该关系的向量。
这样一来, e 的大小取决于 x⃗ 在 r⃗ 上的映射的大小,与该实体关系更加密切的句子可以取得更大的取值。
那么对于句子集合 S ,引入attention机制后,可以将其定义为向量 s⃗ :
加入attention机制得到句子集合向量 s⃗ 后,再通过一层网络得到 o⃗ :
其中 M 是所有实体关系的向量所组成的矩阵, d⃗ 是偏置向量。
这样使得网络的输出数目和关系数目相等,方便后续softmax层进行分类:
其中 nr 是所有关系的数目。
需要最大化的就是在网络参数下某实体关系的概率。
最后,损失函数采用交叉熵:
5 模型分析
attention机制
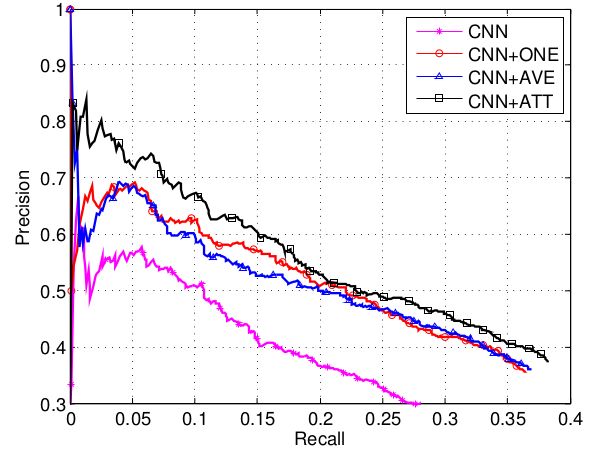
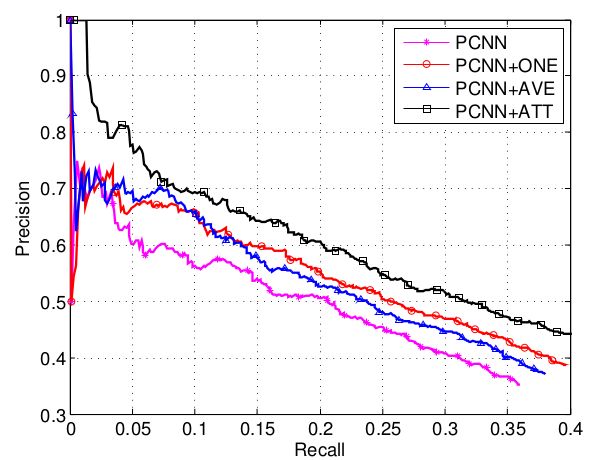
从上面两张图可以看出
- ONE模型(at-least-one multi-instance,每次只选取最后可能的一个句子进行训练和预测)效果要优于裸CNN模型,证明了过滤掉噪音语料是有效的;
- AVE模型(sentence-level attention’s naive version,上面的 s=∑i1nx⃗ i )效果优于裸CNN模型,证明了减弱噪音语料是有效的;
- 而AVE模型和ONE模型的效果接近,因为对噪音语料的处理都不是十分恰当;
- 实验也证明了文章对于噪音语料处理的有效性。
句子数目
使用CNN/PCNN+ONE,CNN/PCNN+AVE和CNN/PCNN+ATT三种模型在所有句子上训练,然后在每个实体对对应2个以上句子的实例中进行测试,分别使用随机选取1个句子,随机选取2个句子和选取所有句子的方式进行测试。
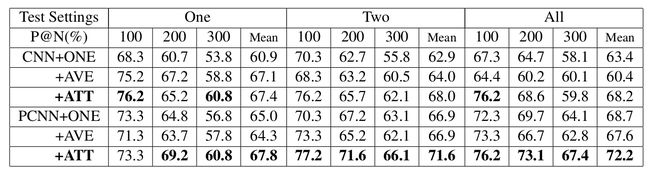
从上图可以看出
- 搭载ATT的模型在所有实验条件下都表现最好;
- 随机选取一个句子测试时,搭载AVE的模型和搭载ATT的模型性能接近,但当选取句子数目上升时,搭载AVE的模型的性能不再增加,说明将每个句子等同对待时,噪音语料会对关系提取有负面影响;
- 在选取一个句子做预测时,CNN+AVE和CNN+ATT的模型的性能明显优于CNN+ONE,由于这只跟训练有关,说明尽管一些噪音语料会带来负面影响,但训练时考虑的语料越多,总的来说,还是对关系提取有帮助的;
- 搭载ATT的模型要明显优于其余2种模型,说明当考虑的语料越多的同时,考虑的语料的质量越高,对关系提取的帮助越大。
对比手工提取特征的方法
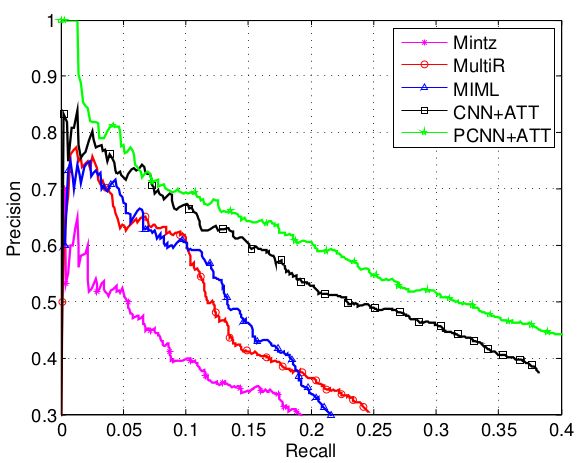
从上图可以看出
- 基于attention机制的神经网络模型要明显优于手工提取特征的方法,不仅性能曲线整体更高,同时,下降得也更平缓;
- 同为使用神经网络的模型,PCNN+ATT要明显优于CNN+ATT,这说明attention机制只考虑了全局的句子层面的信息,而没有考虑到句子内部的信息,也就是说还可以通过使用更为强劲的句子编码神经网络获得更好的句子内信息,以此来提高关系提取的性能。
6 未来展望
- 可以尝试将基于attention机制的multi-instance学习和神经网络结合的方法用在除relation extraction以外的其他任务;
- 可以将instance-level selective attention方法和其他的神经网络结构结合起来。
本篇博客主要参考自
《< Neural Relation Extraction with Selective Attention over Instances>笔记》