Java基础-面试知识
此文章作为自己的一个学习笔记,如有错误请指教。
1 集合(collection接口、map接口)
1.1 collection接口
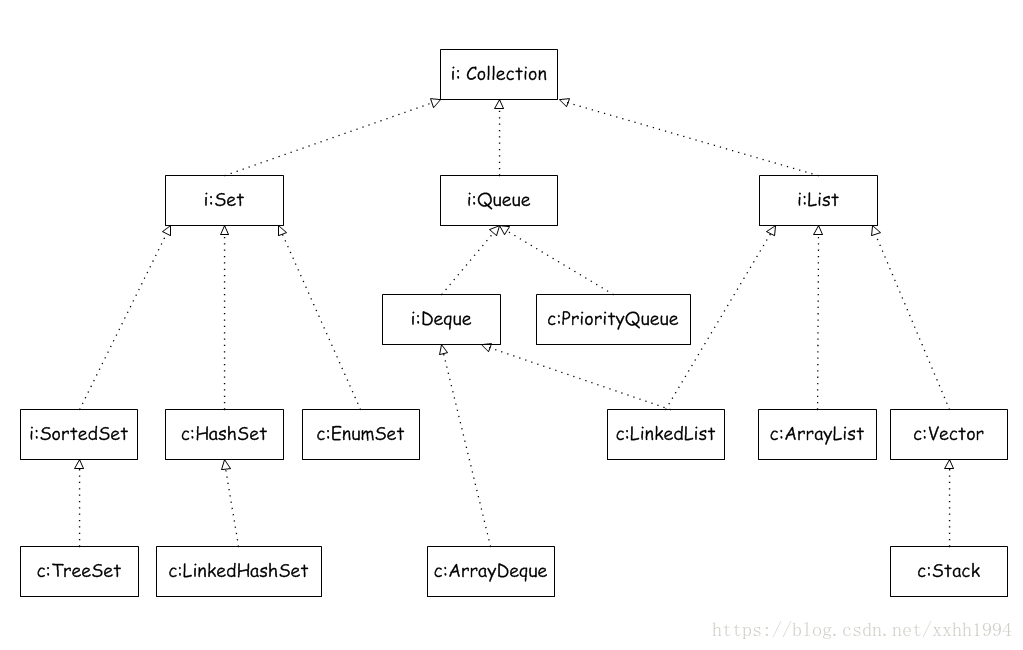
1.1.1 set接口
set集合不允许有重复值,而判断两个对象是否相等则是根据equals方法。
1,HashSet类
不保证元素的的排列顺序,加入的元素要特别注意hashCode()方法的实现。HashSet不是同步的。集合元素值可以为null。
2,LinkedHashSet类
LinkedHashSet类也是根据元素的hashCode的值来决定存储的位置,但它同时需要使用链表维护元素的次序。
与hashSet相比:对于集合略迭代时,按增加顺序返回元素;性能略低于HashSet,因为需要维护元素的顺序。但是迭代元素时会有会有好的性能,因为它采用链表维护内部的顺序
3,SortedSet接口及treeSet实现类
treeSet类是SortedSet接口的实现类,因为需要排序所以性能肯定比HashSet差。与HashSet相比,额外增加的方法有:
first():返回第一个元素
last():返回最后一个元素
lower(Object o):返回指定元素之前的元素
higher(Obect o):返回指定元素之后的元素
subSet(fromElement, toElement):返回子集合
可以定义比较器(Comparator)来实现自定义的排序。默认自然升序排序。
4, EnumSet类
EnumSet类是专为枚举类设计的集合类,EnumSet中的所有元素都必须是指定枚举类型的枚举值。
1.1.2 list接口
list接口是有序集合
1,ArrayList和Vector实现类
这两个类都是都是基于数组形式实现list接口,ArrayList线程不安全,vector线程安全,ArrayList用的多。
2,LinkedList类
基于链表形式实现
1.1.3 queue接口,
1,PriorityQueue类
2,ArrayQueue类
数组方式实现,
3,实现List接口与Deque接口的LinkedList类
1.1.4 各种线性表选择策略
数组:是以一段连续内存保存数据的;随机访问是最快的,但不支持插入、删除、迭代等操作。
ArrayList与ArrayDeque:以数组实现;随机访问速度还行,插入、删除、迭代操作速度一般;线程不安全。
Vector:以数组实现;随机访问速度一般,插入、删除、迭代速度不太好;线程安全的。
LinkedList:以链表实现;随机访问速度不太好,插入、删除、迭代速度非常快。
1.2 Map接口
Map是一个双列集合接口,如果实现了Map接口,特点是数据以键值对形式存在,键不可重复,值可以重复。java中主要有HashMap、TreeMap、Hashtable。
1.2.1 HashMap
HashMap 底层也是基于哈希表实现的,HashMap是非同步的,并且允许null,即null value和null key,无序性
1.2.2 treeMap
TreeMap也是基于红黑树(二叉树)数据结构实现 的, 特点:会对元素的键进行排序存储。有序的。
1.2.3 HashTable
底层也是hash表实现,实现方式和HashMap一致,但是hashTable是线程安全的,操作效率低。
2 线程、线程池
什么是进程呢?
进程是指运行中的应用程序,每个进程都有自己独立的地址空间(内存空间),比如用户点击桌面的IE浏览器,就启动了一个进程,操作系统就会为该进程分配独立的地址空间。当用户再次点击左面的IE浏览器,又启动了一个进程,操作系统将为新的进程分配新的独立的地址空间。目前操作系统都支持多进程。
要点:用户每启动一个进程,操作系统就会为该进程分配一个独立的内存空间。
什么是线程呢?
是进程中的一个实体,是被系统独立调度和分派的基本单位,线程自己不拥有系统资源,只拥有一点在运行中必不可少的资源,但它可与同属一个进程的其它线程共享进程所拥有的全部资源。一个线程可以创建和撤消另一个线程,同一进程中的多个线程之间可以并发执行。线程有就绪、阻塞和运行三种基本状态。
线程有几种状态:
a、新建状态(new)
b、就绪状态(Runnable)
c、运行状态(Running)
d、阻塞状态(Blocked)
e、死亡状态(Dead)
线程的创建方式:
Java使用Thread类表示线程,所有的线程都必须是Thread类或其子类的实例。Java可以使用三种方式创建线程:
1,继承Thread类
a.定义Thread子类,重写run()方法
b.创建Thread实例
c.启动线程start()方法
代码实例
public class MyThread extends Thread{//继承Thread类
public void run(){
//重写run方法
}
}
public class Main {
public static void main(String[] args){
new MyThread().start();//创建并启动线程
}
}
2,实现Runnable接口
a.定义Runnable接口的实现类,重写run(),
b.创建Runnable实现类的实例,并用这个实例作为Thread的Target来创建Thread对象,这个Thread对象才是真正的线程对象,
c.调用线程对象的start()启动线程。
代码实例:
public class MyThread2 implements Runnable {//实现Runnable接口
public void run(){
//重写run方法
}
}
public class Main {
public static void main(String[] args){
//创建并启动线程
MyThread2 myThread=new MyThread2();
Thread thread=new Thread(myThread);
thread().start();
//或者 new Thread(new MyThread2()).start();
}
}
3,实现Callable接口跟Future
(1)创建Callable接口的实现类,并实现call()方法,该call()方法将作为线程执行体,并且有返回值。
(2)创建Callable实现类的实例,使用FutureTask类来包装Callable对象,该FutureTask对象封装了该Callable对象的call()方法的返回值。(FutureTask是一个包装器,它通过接受Callable来创建,它同时实现了Future和Runnable接口。)
(3)使用FutureTask对象作为Thread对象的target创建并启动新线程。
(4)调用FutureTask对象的get()方法来获得子线程执行结束后的返回值
代码实例:
public class ThreadDemo03 {
/**
* @param args
*/
public static void main(String[] args) {
// TODO Auto-generated method stub
Callable
}
实现Runnable和实现Callable接口的方式基本相同,不过是后者执行call()方法有返回值,后者线程执行体run()方法无返回值,因此可以把这两种方式归为一种这种方式与继承Thread类的方法之间的差别如下:
1、线程只是实现Runnable或实现Callable接口,还可以继承其他类。
2、这种方式下,多个线程可以共享一个target对象,非常适合多线程处理同一份资源的情形。
3、但是编程稍微复杂,如果需要访问当前线程,必须调用Thread.currentThread()方法。
4、继承Thread类的线程类不能再继承其他父类(Java单继承决定)。
注:一般推荐采用实现接口的方式来创建多线程
线程池
线程池的作用:
线程池作用就是限制系统中执行线程的数量。
根据系统的环境情况,可以自动或手动设置线程数量,达到运行的最佳效果;少了浪费了系统资源,多了造成系统拥挤效率不高。用线程池控制线程数量,其他线程排队等候。一个任务执行完毕,再从队列的中取最前面的任务开始执行。若队列中没有等待进程,线程池的这一资源处于等待。当一个新任务需要运行时,如果线程池中有等待的工作线程,就可以开始运行了;否则进入等待队列。
1.减少了创建和销毁线程的次数,每个工作线程都可以被重复利用,可执行多个任务。
2.可以根据系统的承受能力,调整线程池中工作线线程的数目,防止因为消耗过多的内存,而把服务器累趴下(每个线程需要大约1MB内存,线程开的越多,消耗的内存也就越大,最后死机)。
线程池的几种创建方式:
Java里面线程池的顶级接口是Executor,但是严格意义上讲Executor并不是一个线程池,而只是一个执行线程的工具。真正的线程池接口是ExecutorService。
在Executors类里面提供了一些静态工厂,生成一些常用的线程池。
1. newSingleThreadExecutor
创建一个单线程的线程池。这个线程池只有一个线程在工作,也就是相当于单线程串行执行所有任务。如果这个唯一的线程因为异常结束,那么会有一个新的线程来替代它。此线程池保证所有任务的执行顺序按照任务的提交顺序执行。
2.newFixedThreadPool
创建固定大小的线程池。每次提交一个任务就创建一个线程,直到线程达到线程池的最大大小。线程池的大小一旦达到最大值就会保持不变,如果某个线程因为执行异常而结束,那么线程池会补充一个新线程。
3. newCachedThreadPool
创建一个可缓存的线程池。如果线程池的大小超过了处理任务所需要的线程,
那么就会回收部分空闲(60秒不执行任务)的线程,当任务数增加时,此线程池又可以智能的添加新线程来处理任务。此线程池不会对线程池大小做限制,线程池大小完全依赖于操作系统(或者说JVM)能够创建的最大线程大小。
4.newScheduledThreadPool
创建一个大小无限的线程池。此线程池支持定时以及周期性执行任务的需求。
代码如下:
publicclassTestSingleThreadExecutor {
publicstaticvoid main(String[] args) {
//创建一个可重用固定线程数的线程池
ExecutorService pool = Executors. newSingleThreadExecutor();
//创建实现了Runnable接口对象,Thread对象当然也实现了Runnable接口
Thread t1 = new MyThread();
Thread t2 = new MyThread();
Thread t3 = new MyThread();
Thread t4 = new MyThread();
Thread t5 = new MyThread();
//将线程放入池中进行执行
pool.execute(t1);
pool.execute(t2);
pool.execute(t3);
pool.execute(t4);
pool.execute(t5);
//关闭线程池
pool.shutdown();
}
}
3 类各个模块的执行顺序
1,静态代码块 --- 非静态代码块 ---- 构造方法
2.父类静态代码块 --- 子类静态代码块 ----- 父类非静态代码块 ----父类构造方法 ----- 子类非静态代码块 --- 子类构造方法
4. 接口 跟抽象类的区别
一个类只能继承一个类但可以实现多个接口
1.接口里只能抽象方法,抽象类可以有抽象方法也可以有普通方法
2.接口中只能定义常量,抽象类可以有常量也可以有普通成员变量
3.接口中不能有构造函数,抽象类可以声明构造函数
4.接口中的方法不能被static修饰,抽象类中的方法可以被static修饰
5.接口中的方法全都是public abstract的方法,而接口中可以用public ,protected等修饰。

接口主要用于模块与模块之间的调用
抽象类主要用于当做基础类使用,即基类
2 如果实现类是非抽象的,则必须实现抽象父类或接口中的访求、属性。
5 JVM类加载机制
JVM提供了3种类加载器:
1.启动类加载器(Bootstrap ClassLoader):负责加载 JAVA_HOME\lib 目录中的,或通过-Xbootclasspath参数指定路径中的,且被虚拟机认可(按文件名识别,如rt.jar)的类。
2.扩展类加载器(Extension ClassLoader):负责加载 JAVA_HOME\lib\ext 目录中的,或通过java.ext.dirs系统变量指定路径中的类库。
3.应用程序类加载器(Application ClassLoader):负责加载用户路径(classpath)上的类库。
JVM通过双亲委派模型进行类的加载,当然我们也可以通过继承java.lang.ClassLoader实现自定义的类加载器。

当一个类加载器收到类加载任务,会先交给其父类加载器去完成,因此最终加载任务都会传递到顶层的启动类加载器,只有当父类加载器无法完成加载任务时,才会尝试执行加载任务。
采用双亲委派的一个好处是比如加载位于rt.jar包中的类java.lang.Object,不管是哪个加载器加载这个类,最终都是委托给顶层的启动类加载器进行加载,这样就保证了使用不同的类加载器最终得到的都是同样一个Object对象。
6 Java GC机制(垃圾回收机制)
gc原理:
当创建一个对象时,GC就开始监控这个对象的地址、大小以及使用情况,通常GC是使用有向图的方式记录和管理堆中的所有对象,通过这种方式来确定哪些对象时可达,哪些对象不可达,对于不可达的对象,GC就有责任进行回收。
序员可以手动执行System.gc(),通知GC运行,但是Java语言规范并不保证GC一定会执行。
(2) 旧域:新域中的对象,经过了一定次数的GC循环后,被移入旧域
(3)永久域:存储类和方法对象,从配置的角度看,这个域是独立的,不包括在JVM堆内。默认为4M。
对于新生成的对象,对于新生成的对象,都放在Eden中;当Eden充满时(小孩太多 了),GC将开始工作,首先停止应用程序的运行,开始收集垃圾,把所有可找到的对象都复制到A空间中,一旦当A空间充满,GC就把在A空间中可找到的对象 都复制到B空间中(会覆盖原有的存储对象),当B空间满的时间,GC就把在B空间中可找到的对象都复制到A空间中,这种算法叫做copying算法(停止-复制(Stop-and-copy)清理法)。
应用程序生成的绝大部分对象都是短命的,copying算法最理想的 状态是,所有移出Eden的对象都会被收集,因为这些都是短命鬼,经过一定次数的GC后应该被收集,那么移入到旧域的对象都是长命的。对于旧域,采用的是tracing算法的一种,称为标记-清除-压缩收 集器。
四、总结
1.JVM堆的大小决定了GC的运行时间。如果JVM堆的大小超过一定的限度,那么GC的运行时间会很长。
2.对象生存的时间越长,GC需要的回收时间也越长,影响了回收速度。
3.大多数对象都是短命的,所以,如果能让这些对象的生存期在GC的一次运行周期内,wonderful!
4.应用程序中,建立与释放对象的速度决定了垃圾收集的频率。
5.如果GC一次运行周期超过3-5秒,这会很影响应用程序的运行,如果可以,应该减少JVM堆的大小了。
6.前辈经验之谈:通常情况下,JVM堆的大小应为物理内存的80%
7.final static关键字
关于final的重要知识点
1.final关键字可以用于成员变量、本地变量、方法以及类。
2.final成员变量必须在声明的时候初始化或者在构造器中初始化,否则就会报编译错误。
3.你不能够对final变量再次赋值。
4.本地变量必须在声明时赋值。
5.在匿名类中所有变量都必须是final变量。
6.final方法不能被重写。
7.final类不能被继承。
8.final关键字不同于finally关键字,后者用于异常处理。
9.final关键字容易与finalize()方法搞混,后者是在Object类中定义的方法,是在垃圾回收之前被JVM调用的方法。
10.接口中声明的所有变量本身是final的。
11.final和abstract这两个关键字是反相关的,final类就不可能是abstract的。
12.final方法在编译阶段绑定,称为静态绑定(static binding)。
13.没有在声明时初始化final变量的称为空白final变量(blank final variable),它们必须在构造器中初始化,或者调用this()初始化。不这么做的话,编译器会报错“final变量(变量名)需要进行初始化”。
14.将类、方法、变量声明为final能够提高性能,这样JVM就有机会进行估计,然后优化。
15.按照Java代码惯例,final变量就是常量,而且通常常量名要大写:
关于static的重要知识点
1.static方法就是没有this的方法。在static方法内部不能调用非静态方法,反过来是可以的。而且可以在没有创建任何对象的前提下,仅仅通过类本身来调用static方法。这实际上正是static方法的主要用途。
2.static方法一般称作静态方法,由于静态方法不依赖于任何对象就可以进行访问,因此对于静态方法来说,是没有this的,因为它不依附于任何对象,既然都没有对象,就谈不上this了。并且由于这个特性,在静态方法中不能访问类的非静态成员变量和非静态成员方法,因为非静态成员方法/变量都是必须依赖具体的对象才能够被调用。
3.static是不允许用来修饰局部变量
8 jdk、jre、jvm的关系及区别
JDK: java development kit, java开发工具包,针对开发者,里面主要包含了jre, jvm, jdk源码包,以及bin文件夹下用于开发,编译运行的一些指令器。
JRE: java runtime environment, java运行时环境,针对java用户,也就是拥有可运行的.class文件包(jar或者war)的用户。里面主要包含了jvm和java运行时基本类库(rt.jar)。
JVM: java虚拟机,将它理解为可以识别class文件的一个小型系统,class文件直接和它交互,所以它让class文件和用户真实的操作系统隔离,屏蔽了用户系统的差异性,给人一种感觉就是java出道的最大特点:一次编译,处处运行(跨平台)。
JRE和JVM区别:有些人觉得,JVM就可以执行class了,其实不然,JVM执行.class还需要JRE下的lib类库的支持,尤其是rt.jar。
9.什么是面向对象
面向对象是一种程序设计方法,它以对象作为作为基本单元来构建系统。它利用对象将系统的复杂性隐藏在对象里(也就是常说的封装),从而构建大型的工业级系统和大型系统(注意是工业及系统和大型软件系统而不是播放器等小型的系统)。面向对象包括三个过程:面向对象分析(OOA)、面向对象设计(OOD)、面向对象编程(OOP)。
10.hibernate跟mybatis的区别
Hibernate是一个开放源代码的对象关系映射框架,它对JDBC进行了非常轻量级的对象封装,建立对象与数据库表的映射。是一个全自动的、完全面向对象的持久层框架。
Mybatis是一个开源对象关系映射框架,原名:ibatis,2010年由谷歌接管以后更名。是一个半自动化的持久层框架。
MyBatis可以进行更为细致的SQL优化,可以减少查询字段。
MyBatis容易掌握,而Hibernate门槛较高。
Hibernate优势
Hibernate的DAO层开发比MyBatis简单,Mybatis需要维护SQL和结果映射。
Hibernate对对象的维护和缓存要比MyBatis好,对增删改查的对象的维护要方便。
Hibernate数据库移植性很好,MyBatis的数据库移植性不好,不同的数据库需要写不同SQL。
Hibernate有更好的二级缓存机制,可以使用第三方缓存。MyBatis本身提供的缓存机制不佳。