从kafka中获取数据写入到redis中
大家:
好!从kafka中获取数据写入到redis中,需要用到spark中的redis客户端配置,请参考前面的博客(https://blog.csdn.net/zhaoxiangchong/article/details/78379883)。
第一步 要先将数据打入到kafka中,请参照我以前的博客 https://blog.csdn.net/zhaoxiangchong/article/details/78379927
说明: 尤其要注意kafka中的topic的名称,这两个一定要一致。
第二步,idea中部署kafka打入redis的代码,如下所示:
package Traffic
import java.text.SimpleDateFormat
import java.util.Calendar
import kafka.serializer.{StringDecoder, StringEncoder}
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
import net.sf.json.JSONObject
/**
* Created by Administrator on 2017/10/14.
* 功能: 从kafka中获取数据写入到redis中
*
*/
object CarEventAnalysis {
def main(args: Array[String]): Unit = {
//配置SparkStrteaming
val conf=new SparkConf().setAppName("CarEventAnalysis").setMaster("local[2]")
val sc=new SparkContext(conf)
val ssc=new StreamingContext(sc,Seconds(5))
val dbindex=1 //指定是用哪个数据库进行连接
//从kafka中读取数据(用直连的方法)
val topics=Set("car_event")
// 只要和brokers相关的都要写全
val brokers="192.168.17.108:9092"
//配置kafka参数
val kafkaParams=Map[String,String](
"metadata.broker.list"->brokers,
"serializer.class"->"kafka.serializer.StringEncoder"
)
//创建一个流 这是一个模板代码 参数中的两个String代表的是kafka的键值对的数据,及key和value
val kafkaStream=KafkaUtils.createDirectStream[String,String,
StringDecoder,StringDecoder](ssc,kafkaParams,topics)
//从kafka中将数据读出
val events=kafkaStream.flatMap(line=>{
//转换为object
val data=JSONObject.fromObject(line._2) // ._2是真正的数据
// println(data)
//必须用Some修饰data option有两个子类 none 代表无值 some代表有值
// 加上some表示一定有值,后面有x.getString和x.getInt,保证程序能知道有值
Some(data)
})
//从kafka中取出卡口编号和速度数据
val carspeed=events.map(x=>(x.getString("camer_id"),x.getInt("car_speed")))
//把数据变成(camer_id,(car_speed,1))
.mapValues((x:Int)=>(x,1.toInt))
//每隔10秒计算一次前20秒的速度(4个rdd) Tuple2表示两个参数
// (速度,数量) (速度,数量)
.reduceByKeyAndWindow((a:Tuple2[Int,Int], b:Tuple2[Int,Int]) =>
{(a._1 + b._1,a._2 + b._2)},Seconds(20),Seconds(10))
// carspeed 速度之和 数量之和
// carspeed.map{case(key,value)=>(key,value._1/value._2.toFloat)}
carspeed.foreachRDD(rdd=>{
rdd.foreachPartition(partitionofRecords=>{
//得到连接池的一个资源
val jedis=RedisClient.pool.getResource
// camer_id 卡口以及总的速度
partitionofRecords.foreach(pair=>{
val camer_id=pair._1 //卡口
val total_speed=pair._2._1 //总的速度
val count=pair._2._2 //总的数量
val now=Calendar.getInstance().getTime() //获取当前的时间
val minuteFormat=new SimpleDateFormat("HHmm") //获取分钟格式
val dayFormat=new SimpleDateFormat("yyyyMMdd") //获取天格式
val time = minuteFormat.format(now) //获取分钟
val day = dayFormat.format(now) //获取天
//开始往redis中插入数据
if(count!=0){
jedis.select(dbindex) //用选择的数据库
// set进去一个map
jedis.hset(day + "_" + camer_id, time ,total_speed + "_" + count)
// 从redis中取数据
val foreachdata=jedis.hget(day + "_" + camer_id, time)
println(foreachdata)
}
})
RedisClient.pool.returnResource(jedis)
})
})
println("----------计算开始---------------------------")
ssc.start()
ssc.awaitTermination()
}
}第三步: idea中运行第二步部署好的kafka打入redis的代码,程序截图如下所示:
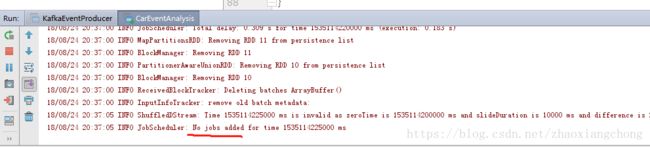
说明: 这说明,kafka对应的topic中没有job为其打入数据。这正常,因为此时还没有往kafka中打数据,此步是为了测试代码的正确性
如果在没有引入依赖jar的情况下,此步是会报错的,截图如下所示:

说明: 需要引入ezmorph-1.0.6.jar, 以及三个依赖jar commons-collections-3.2.jar,commons-lang-2.3.jar,commons-pool2-2.2.jar, 共四个jar
第四步: 运行第一步的往kafka中打数据的程序,截图以下所示:

说明: 1 截图显示,已经开始往kafka中打数据了
2 此时的数据源,测试数据要造的多点,防止一会就把数据全部打到kafka中了
第五步: 此时kafka中有数据了,检查第三步的程序的运行结果,截图如下所示:

说明: 这就说明,kafka已经开始往redis中打数据了
第六步: 登录到redis的客户端,验证数据是否存入redis中
[root@hadoop ~]# redis-cli -p 12002
127.0.0.1:12002> select 1
OK
127.0.0.1:12002[1]> hgetall 20180824_310999015305
1) "2038"
2) "40_2"
说明: 结果的意思是,在20180824的20点38分,在卡口310999015305,共有2辆车通过,这2辆车的总速度是40说明: 1 因为程序中redis中的key值的时间是按照当前日期来的,所以显示了20180824日,而非测试数据中的日期。而在实际的生产中,数据中的日期和当前日期是很相近的,因为是实时计算