京东预测系统核心介绍
1. 京东预测系统
1.1 预测系统介绍
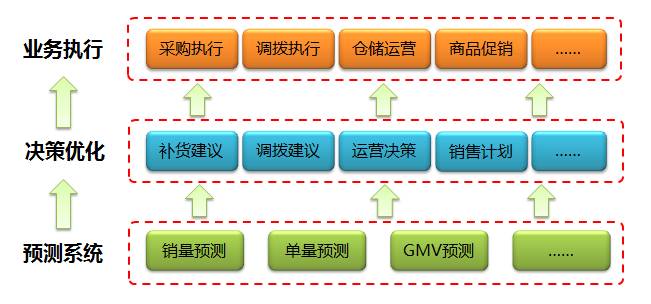
预测系统在整个供应链体系中处在最底层并且起到一个支撑的作用,支持上层的多个决策优化系统,而这些决策优化系统利用精准的预测数据结合运筹学技术得出最优的决策,并将结果提供给更上层的业务执行系统或是业务方直接使用。
目前,预测系统主要支持三大业务:销量预测、单量预测和GMV预测。其中销量预测主要支持商品补货、商品调拨;单量预测主要支持仓库、站点的运营管理;GMV预测主要支持销售部门计划的定制。
销量预测按照不同维度又可以分为RDC采购预测、FDC调拨预测、城市仓调拨预测、大建仓补货预测、全球购销量预测和图书促销预测等;单量预测又可分为库房单量预测、配送中心单量预测和配送站单量预测等(在这里“单量”并非指用户所下订单的量,而是将订单拆单后流转到仓库中的单量。例如一个用户的订单中包括3件物品,其中两个大件品和一个小件品,在京东的供应链环节中可能会将其中两个大件品组成一个单投放到大件仓中,而将那个小件单独一个单投放到小件仓中,单量指的是拆单后的量);GMV预测支持到商品粒度。
1.2 预测系统架构
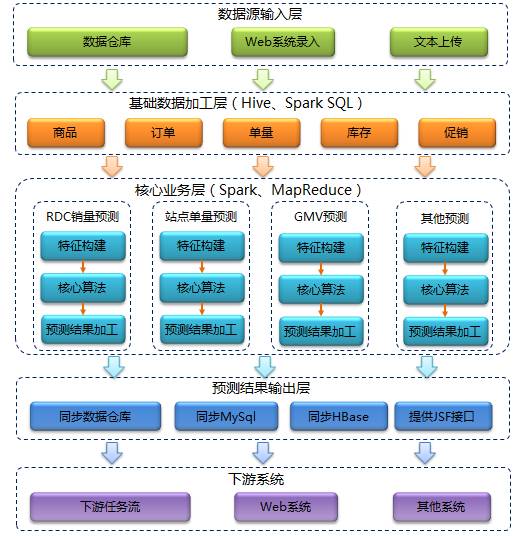
整体架构从上至下依次是:数据源输入层、基础数据加工层、核心业务层、数据输出层和下游系统。首先从外部数据源获取我们所需的业务数据,然后对基础数据进行加工清洗,再通过时间序列、机器学习等人工智能技术对数据进行处理分析,最后计算出预测结果并通过多种途径推送给下游系统使用。
- 数据源输入层:京东数据仓库中存储着我们需要的大部分业务数据,例如订单信息、商品信息、库存信息等等。而对于促销计划数据则大部分来自于采销人员通过Web系统录入的信息。除此之外还有一小部分数据通过文本形式直接上传到HDFS中。
- 基础数据加工层:在这一层主要通过Hive对基础数据进行一些加工清洗,去掉不需要的字段,过滤不需要的维度并清洗有问题的数据。
- 核心业务层:这层是系统的的核心部分,横向看又可分为三层:特征构建、预测算法和预测结果加工。纵向看是由多条业务线组成,彼此之间不发生任何交集。
- 特征构建:将之前清洗过的基础数据通过近一步的处理转化成标准格式的特征数据,提供给后续算法模型使用。
- 核心算法:利用时间序列分析、机器学习等人工智能技术进行销量、单量的预测,是预测系统中最为核心的部分。
- 预测结果加工:预测结果可能在格式和一些特殊性要求上不能满足下游系统,所以还需要根据实际情况对其进行加工处理,比如增加标准差、促销标识等额外信息。
- 预测结果输出层:将最终预测结果同步回京东数据仓库、MySql、HBase或制作成JSF接口供其他系统远程调用。
- 下游系统:包括下游任务流程、下游Web系统和其他系统。
2. 预测系统核心介绍
2.1 预测系统核心层技术选型
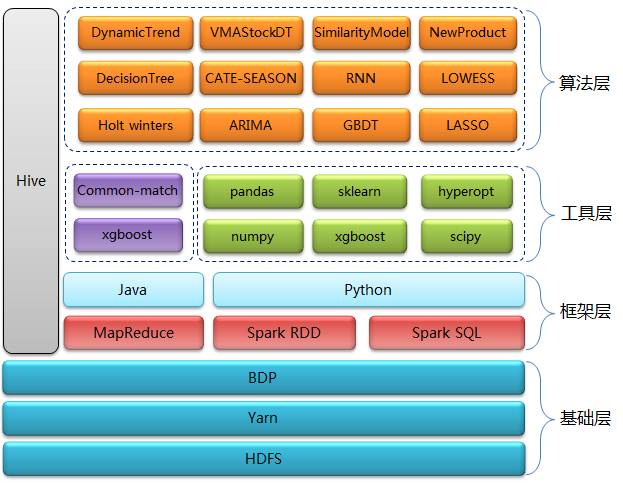
预测系统核心层技术主要分为四层:基础层、框架层、工具层和算法层
基础层: HDFS用来做数据存储,Yarn用来做资源调度,BDP(Big Data Platform)是京东自己研发的大数据平台,我们主要用它来做任务调度。
框架层: 以Spark RDD、Spark SQL、Hive为主, MapReduce程序占一小部分,是原先遗留下来的,目前正逐步替换成Spark RDD。 选择Spark除了对性能的考虑外,还考虑了Spark程序开发的高效率、多语言特性以及对机器学习算法的支持。在Spark开发语言上我们选择了Python,原因有以下三点:
- Python有很多不错的机器学习算法包可以使用,比起Spark的MLlib,算法的准确度更高。我们用GBDT做过对比,发现xgboost比MLlib里面提供的提升树模型预测准确度高出大概5%~10%。虽然直接使用Spark自带的机器学习框架会节省我们的开发成本,但预测准确度对于我们来说至关重要,每提升1%的准确度,就可能会带来成本的成倍降低。
- 我们的团队中包括开发工程师和算法工程师,对于算法工程师而言他们更擅长使用Python进行数据分析,使用Java或Scala会有不小的学习成本。
- 对比其他语言,我们发现使用Python的开发效率是最高的,并且对于一个新人,学习Python比学习其他语言更加容易。
工具层: 一方面我们会结合自身业务有针对性的开发一些算法,另一方面我们会直接使用业界比较成熟的算法和模型,这些算法都封装在第三方Python包中。我们比较常用的包有xgboost、numpy、pandas、sklearn、scipy和hyperopt等。
Xgboost:它是Gradient Boosting Machine的一个C++实现,xgboost最大的特点在于,它能够自动利用CPU的多线程进行并行,同时在算法上加以改进提高了精度。
numpy:是Python的一种开源的数值计算扩展。这种工具可用来存储和处理大型矩阵,比Python自身的嵌套列表结构要高效的多(该结构也可以用来表示矩阵)。
pandas:是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。
sklearn:是Python重要的机器学习库,支持包括分类、回归、降维和聚类四大机器学习算法。还包含了特征提取、数据处理和模型评估三大模块。
scipy:是在NumPy库的基础上增加了众多的数学、科学以及工程计算中常用的库函数。例如线性代数、常微分方程数值求解、信号处理、图像处理和稀疏矩阵等等。
算法层: 我们用到的算法模型非常多,原因是京东的商品品类齐全、业务复杂,需要根据不同的情况采用不同的算法模型。我们有一个独立的系统来为算法模型与商品之间建立匹配关系,有些比较复杂的预测业务还需要使用多个模型。我们使用的算法总体上可以分为三类:时间序列、机器学习和结合业务开发的一些独有的算法。
1. 机器学习算法主要包括GBDT、LASSO和RNN :
GBDT:是一种迭代的决策树算法,该算法由多棵决策树组成,所有树的结论累加起来做最终答案。我们用它来预测高销量,但历史规律不明显的商品。
RNN:这种网络的内部状态可以展示动态时序行为。不同于前馈神经网络的是,RNN可以利用它内部的记忆来处理任意时序的输入序列,这让它可以更容易处理如时序预测、语音识别等。
LASSO:该方法是一种压缩估计。它通过构造一个罚函数得到一个较为精炼的模型,使得它压缩一些系数,同时设定一些系数为零。因此保留了子集收缩的优点,是一种处理具有复共线性数据的有偏估计。用来预测低销量,历史数据平稳的商品效果较好。
2. 时间序列主要包括ARIMA和Holt winters :
ARIMA:全称为自回归积分滑动平均模型,于70年代初提出的一个著名时间序列预测方法,我们用它来主要预测类似库房单量这种平稳的序列。
Holt winters:又称三次指数平滑算法,也是一个经典的时间序列算法,我们用它来预测季节性和趋势都很明显的商品。
3. 结合业务开发的独有算法包括WMAStockDT、SimilarityModel和NewProduct等:
WMAStockDT:库存决策树模型,用来预测受库存状态影响较大的商品。
SimilarityModel:相似品模型,使用指定的同类品数据来预测某商品未来销量。
NewProduct:新品模型,顾名思义就是用来预测新品的销量。
2.2 预测系统核心流程
预测核心流程主要包括两类:以机器学习算法为主的流程和以时间序列分析为主的流程。
1. 以机器学习算法为主的流程如下:
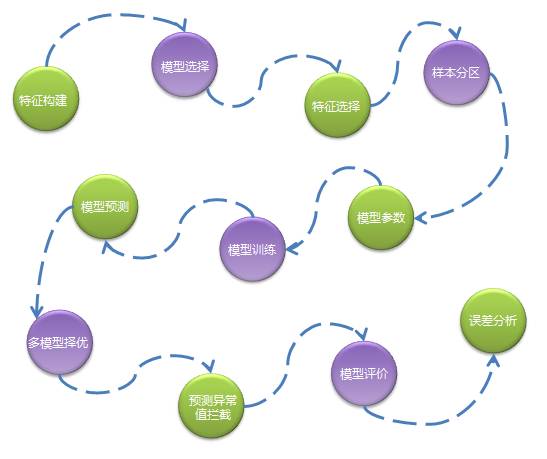
特征构建:通过数据分析、模型试验确定主要特征,通过一系列任务生成标准格式的特征数据。
模型选择:不同的商品有不同的特性,所以首先会根据商品的销量高低、新品旧品、假节日敏感性等因素分配不同的算法模型。
特征选择:对一批特征进行筛选过滤不需要的特征,不同类型的商品特征不同。
样本分区:对训练数据进行分组,分成多组样本,真正训练时针对每组样本生成一个模型文件。一般是同类型商品被分成一组,比如按品类维度分组,这样做是考虑并行化以及模型的准确性。
模型参数:选择最优的模型参数,合适的参数将提高模型的准确度,因为需要对不同的参数组合分别进行模型训练和预测,所以这一步是非常耗费资源。
模型训练:待特征、模型、样本都确定好后就可以进行模型训练,训练往往会耗费很长时间,训练后会生成模型文件,存储在HDFS中。
模型预测:读取模型文件进行预测执行。
多模型择优:为了提高预测准确度,我们可能会使用多个算法模型,当每个模型的预测结果输出后系统会通过一些规则来选择一个最优的预测结果。
预测值异常拦截:我们发现越是复杂且不易解释的算法越容易出现极个别预测值异常偏高的情况,这种预测偏高无法结合历史数据进行解释,因此我们会通过一些规则将这些异常值拦截下来,并且用一个更加保守的数值代替。
模型评价:计算预测准确度,我们通常用使用mapd来作为评价指标。
误差分析:通过分析预测准确度得出一个误差在不同维度上的分布,以便给算法优化提供参考依据。
2. 以时间序列分析为主的预测流程如下:
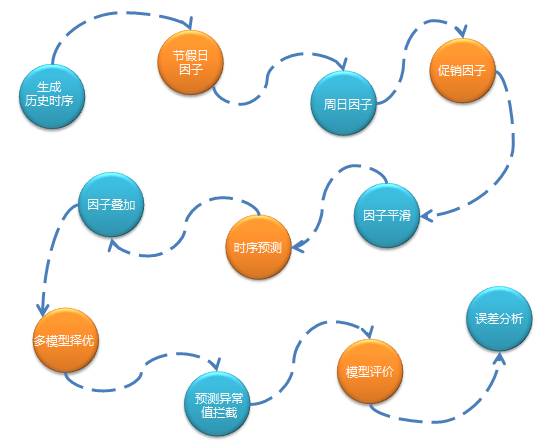
2.3 Spark在预测核心层的应用
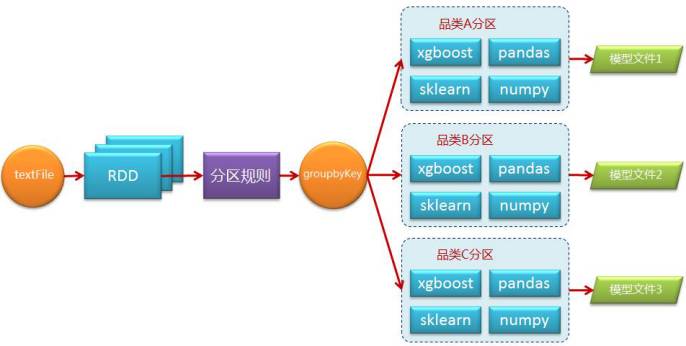
我们使用Spark SQL和Spark RDD相结合的方式来编写程序,对于一般的数据处理,我们使用Spark的方式与其他无异,但是对于模型训练、预测这些需要调用算法接口的逻辑就需要考虑一下并行化的问题了。我们平均一个训练任务在一天处理的数据量大约在500G左右,虽然数据规模不是特别的庞大,但是Python算法包提供的算法都是单进程执行。我们计算过,如果使用一台机器训练全部品类数据需要一个星期的时间,这是无法接收的,所以我们需要借助Spark这种分布式并行计算框架来将计算分摊到多个节点上实现并行化处理。
我们实现的方法很简单,首先需要在集群的每个节点上安装所需的全部Python包,然后在编写Spark程序时考虑通过某种规则将数据分区,比如按品类维度,通过groupByKey操作将数据重新分区,每一个分区是一个样本集合并进行独立的训练,以此达到并行化。流程如下图所示:
伪码如下:

repartitionBy方法即设置一个重分区的逻辑返回(K,V)结构RDD,train方法是训练数据,在train方法里面会调用Python算法包接口。saveAsPickleFile是Spark Python独有的一个Action操作,支持将RDD保存成序列化后的sequnceFile格式的文件,在序列化过程中会以10个一批的方式进行处理,保存模型文件非常适合。
虽然原理简单,但存在着一个难点,即以什么样的规则进行分区,key应该如何设置。为了解决这个问题我们需要考虑几个方面,第一就是哪些数据应该被聚合到一起进行训练,第二就是如何避免数据倾斜。
针对第一个问题我们做了如下几点考虑:
- 被分在一个分区的数据要有一定的相似性,这样训练的效果才会更好,比如按品类分区就是个典型例子。
- 分析商品的特性,根据特性的不同选择不同的模型,例如高销商品和低销商品的预测模型是不一样的,即使是同一模型使用的特征也可能不同,比如对促销敏感的商品就需要更多与促销相关特征,相同模型相同特征的商品应倾向于分在一个分区中。
针对第二个问题我们采用了如下的方式解决:
- 对于数据量过大的分区进行随机抽样选取。
- 对于数据量过大的分区还可以做二次拆分,比如图书小说这个品类数据量明显大于其他品类,于是就可以分析小说品类下的子品类数据量分布情况,并将子品类合并成新的几个分区。
- 对于数据量过小这种情况则需要考虑进行几个分区数据的合并处理。
总之对于后两种处理方式可以单独通过一个Spark任务定期运行,并将这种分区规则保存。