Python+requests+selenium多线程爬取王者荣耀全部1080P壁纸(共450M,用时57S)并按英雄进行分类
玩王者荣耀有4年了,一直很喜欢这个游戏。记不得是哪天了,当时刚刚接触python,看见网上有人用python爬取王者荣耀全皮肤图片,虽然看不懂,但满是羡慕,也想着有一天能够自己写一个程序爬我喜欢的东西。
看了大神的文章后开始自学爬虫,期间也进行过一些尝试,但结果总是不尽人意。于是利用暑假的时间,买了一本关于爬虫的书籍,开始系统的学习。在经过大量的示例分析和实践后,我又进行了一次尝试,也就是这次,用了一天半的时间运行,调试,运行,调试。。。程序最终定型!
声明一下,和网上其他爬皮肤的程序是有本质区别的,是爬壁纸,爬壁纸,爬壁纸!!!!
一、准备工作
安装第三方库requests、selenium、pyquery
安装Chrome浏览器驱动chromedriver
二、爬取方式
(1)Ajax
(以下内容是我昨天写第一个版本的时候,分析Ajax请求的过程,本来不打算写这个直接写selenium的,但毕竟也是我一个思考过程,还是放在上面吧,分享一下我的经历,多看我的笑话,少走一些弯路)
进入王者荣耀官网:https://pvp.qq.com/点击游戏壁纸
既然有这么多页,那么就先翻页找找url的规律
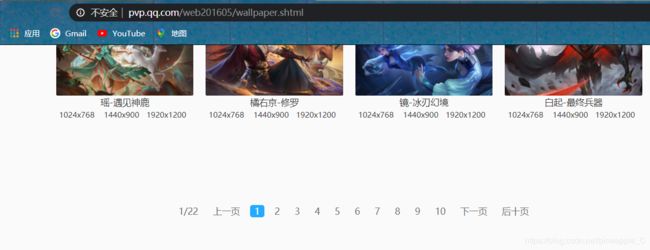
 多翻几页看可以发现,url根本就没有变化!!!而且还是以shtml结尾的并不是html
多翻几页看可以发现,url根本就没有变化!!!而且还是以shtml结尾的并不是html
查了一些资料,大多都是这样解释的:SHTML不是HTML而是一种服务器 API,shtml是服务器动态产成的html。html或者htm是一种静态的页面格式,不需要服务器解析其中的脚本,浏览器可以直接编译显示;而shtml或者shtm由于它基于SSI技术,当有服务器端可执行脚本时被当作一种动态编程语言来看待,就如php、aspx、asp、jsp一样,当shtml或者shtm中不包含服务器端可执行脚本时其作用和html或者htm是一样的。
前端的东西我也不太了解,总之它是动态页面。所以一开始我是查找Ajax请求的
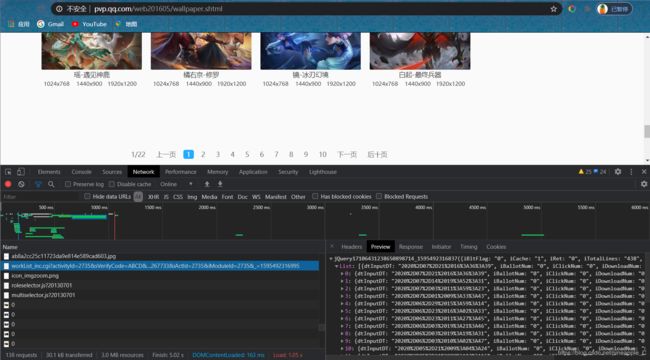 每次翻页都会加载一些图片,而图片的上方总是有这个请求,所以我猜想这里面很可能包含图片的信息,打开一看正好这个请求是有20个字典组成的json数据,而一页刚好加载20张图片,就是它了!
每次翻页都会加载一些图片,而图片的上方总是有这个请求,所以我猜想这里面很可能包含图片的信息,打开一看正好这个请求是有20个字典组成的json数据,而一页刚好加载20张图片,就是它了!
展开后发现这些链接都是经过url编码的,而且还带有编号,直接看很难看出其中的规律
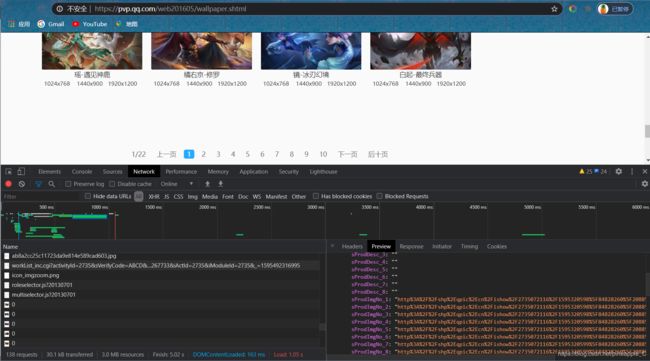 我们可以用url.parse.unquote()对他们进行解码
我们可以用url.parse.unquote()对他们进行解码
from urllib.parse import unquote
sProdImgNo_1 = unquote(
"http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735072116%2F1595320598%5F84828260%5F20885%5FsProdImgNo%5F1%2Ejpg%2F200")
sProdImgNo_2 = unquote(
"http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735072116%2F1595320598%5F84828260%5F20885%5FsProdImgNo%5F2%2Ejpg%2F200")
sProdImgNo_3 = unquote(
"http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735072116%2F1595320598%5F84828260%5F20885%5FsProdImgNo%5F3%2Ejpg%2F200")
sProdImgNo_4 = unquote(
"http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735072116%2F1595320598%5F84828260%5F20885%5FsProdImgNo%5F4%2Ejpg%2F200")
sProdImgNo_5 = unquote(
"http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735072116%2F1595320598%5F84828260%5F20885%5FsProdImgNo%5F5%2Ejpg%2F200")
sProdImgNo_6 = unquote(
"http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735072116%2F1595320599%5F84828260%5F20885%5FsProdImgNo%5F6%2Ejpg%2F200")
sProdImgNo_7 = unquote(
"http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735072116%2F1595320599%5F84828260%5F20885%5FsProdImgNo%5F7%2Ejpg%2F200")
sProdImgNo_8 = unquote(
"http%3A%2F%2Fshp%2Eqpic%2Ecn%2Fishow%2F2735072116%2F1595320599%5F84828260%5F20885%5FsProdImgNo%5F8%2Ejpg%2F200")
sProdName = unquote("%E5%BC%A0%E9%A3%9E%2D%E8%99%8E%E9%AD%84")
print(sProdImgNo_1, sProdImgNo_2, sProdImgNo_3, sProdImgNo_4, sProdImgNo_5, sProdImgNo_6, sProdImgNo_7, sProdImgNo_8,
sProdName, sep='\n')
输出结果:
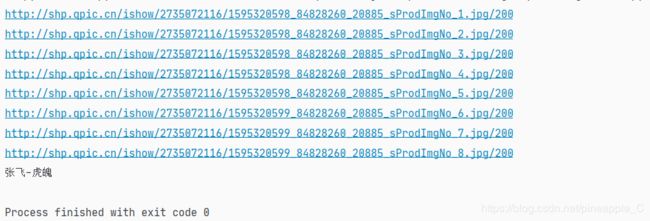
点击其中的一条,感觉图片好小
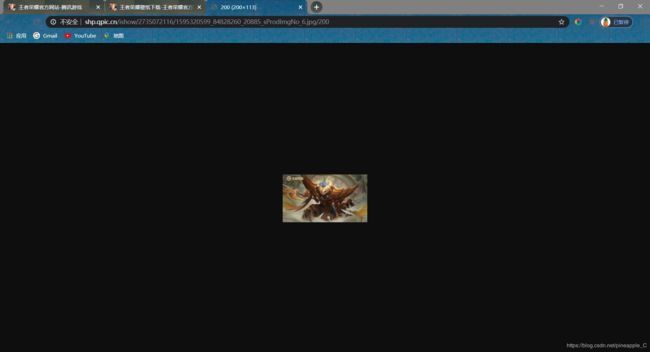 连续点击多个链接,发现都是这么小,只有长和宽有微小的变化。可是图片和图片名称都是张飞,应该没错的呀,所以我怀疑,可能是用JavaScript加工后使图片变大了,而Ajax请求里的只是基础的未经过的url。
连续点击多个链接,发现都是这么小,只有长和宽有微小的变化。可是图片和图片名称都是张飞,应该没错的呀,所以我怀疑,可能是用JavaScript加工后使图片变大了,而Ajax请求里的只是基础的未经过的url。
分析网页源代码后验证了我的想法:
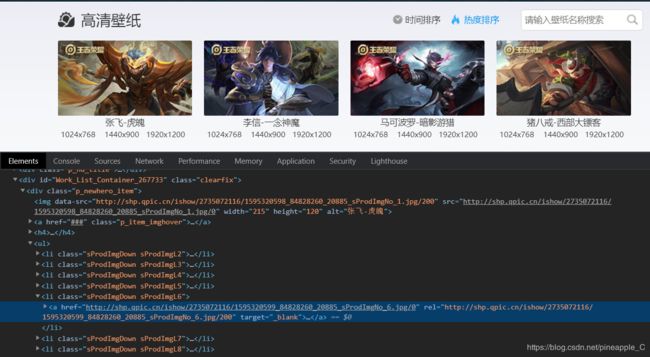 格式几乎一模一样,唯一不同就是jpg后的数字,我突然灵光一现,把解析出的url后面的200改成0,图片竟然变大了!
格式几乎一模一样,唯一不同就是jpg后的数字,我突然灵光一现,把解析出的url后面的200改成0,图片竟然变大了!
后来查看下面的JavaScript,也再一步验证了我的想法:
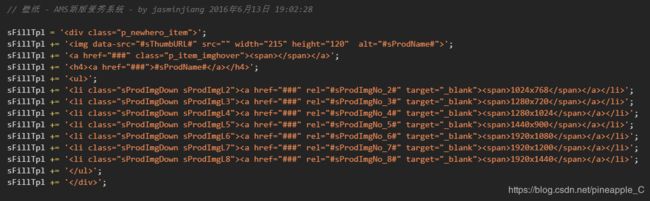
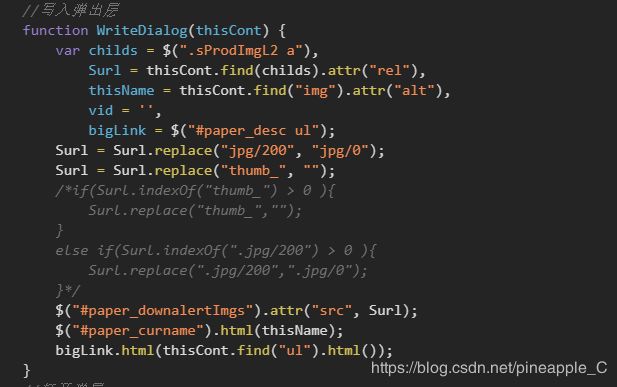
分析到此,基本算是完成了,剩下的就是编写程序了,因为这是我的第一个版本(失败版本,连我自己都觉得复杂,不配python之美),所以也没有写注释,但毕竟这个敲了一天,不舍得扔掉,大家就当看个笑话吧
# -*- coding: utf-8 -*-
"""
@author:Pineapple
@contact:[email protected]
@time:2020/7/21 18:08
@file:glory_of_kings.py
@desc:
"""
from pyquery.pyquery import PyQuery as pq
from urllib.parse import urlencode
from urllib.parse import unquote
from selenium import webdriver
from time import perf_counter
import threading
import requests
import os
start_1 = perf_counter()
base_url = 'https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?'
hero_url = 'https://pvp.qq.com/web201605/herolist.shtml'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36'
}
RESULTS = []
PATH = './image/'
DIRS = []
def get_page(page=0):
"""
获取这一页包含图片信息的js文件
:param page: 页码,从0开始
:return: response.json()
"""
param = {
'activityId': 2735,
'sVerifyCode': 'ABCD',
'sDataType': 'JSON',
'iListNum': 20,
'totalpage': 0,
'page': page,
'iOrder': 0,
'iSortNumClose': 1,
'iAMSActivityId': 51991,
'_everyRead': 'true',
'iTypeId': 2,
'iFlowId': 267733,
'iActId': 2735,
'iModuleId': 2735
}
url = base_url + urlencode(param)
try:
print('正在爬取第{}页信息'.format(page + 1))
response = requests.get(url, headers=headers)
if response.status_code == 200:
# with open('glory_of_kings.json','w',encoding='utf-8')as file:
# file.write(response.text)
return get_info(response.json())
except requests.ConnectionError as e:
print('Error', e.args, sep='\n')
get_page(page)
def make_dir():
browser = webdriver.Chrome()
browser.get(hero_url)
hero_name = browser.page_source
doc = pq(hero_name)
items = doc('.herolist-content ul li').items()
for item in items:
DIRS.append(item.find('a').text())
for dir in DIRS:
if not os.path.exists(PATH + dir):
os.mkdir(PATH + dir)
os.mkdir(PATH + '其它')
def get_info(info_json):
if info_json:
items = info_json.get('List')
for item in items:
info = {}
info['image'] = requests.get(
unquote(item.get('sProdImgNo_6'))[:-3]).content
info['skin'] = unquote(item.get('sProdName'))
RESULTS.append(info)
def save_image():
count = 0
for result in RESULTS:
count += 1
print('正在下载第{}张壁纸'.format(count))
for dir in DIRS:
if result['skin'].count(dir):
with open(PATH + dir + '\\{}.jpg'.format(result['skin']), 'wb')as f:
f.write(result['image'])
break
if not os.path.exists(PATH + dir + '\\{}.jpg'.format(result['skin'])):
with open(PATH + '其它' + '\\{}.jpg'.format(result['skin']), 'wb')as file:
file.write(result['image'])
def index_page(start, end):
for i in range(start, end):
get_page(i)
def main():
t1 = threading.Thread(target=index_page, args=(0, 3))
t2 = threading.Thread(target=index_page, args=(3, 6))
t3 = threading.Thread(target=index_page, args=(6, 9))
t4 = threading.Thread(target=index_page, args=(9, 12))
t5 = threading.Thread(target=index_page, args=(12, 15))
t6 = threading.Thread(target=index_page, args=(15, 18))
t7 = threading.Thread(target=index_page, args=(18, 22))
t1.start()
t2.start()
t3.start()
t4.start()
t5.start()
t6.start()
t7.start()
t7.join()
make_dir()
save_image()
print('用时{:.3f}s'.format(start_1 - perf_counter()))
if __name__ == '__main__':
main()
(2)selenium
上面分析Ajax请求比较繁琐,而且url参数众多不好构造,虽然投机取巧少些几个参数也能请求成功,但这都是个例。大部分当遇到url参数复杂,难以发现规律的情况,就轮到selenium出场了。
至于为什么我第一个版本选择Ajax还是要再插一句(原谅我话多),其实起初我就是用selenium的,但翻页的操作叫我搞错了,导致我误认为使用selenium翻页后网页源码不变,于是就去艰难的找Ajax了。后来睡了一觉,越想越不对劲,翻页后网页的整体框架没有变,只有结点内容和链接发生了变化,果然是我搞错了,细节决定成败!一个翻页的小失误,,让我多花了一天的时间。
嗯,进入正题!
再看一下标题:多线程爬取王者荣耀1080P壁纸并按英雄进行分类。
大概分为以下下几个步骤:创建文件夹,爬取网页源码,筛选分类,多线程运行。
相关依赖
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
from pyquery.pyquery import PyQuery as pq
from selenium import webdriver
from time import perf_counter
import threading
import requests
import os
全局变量
# 计时开始
start = perf_counter()
options = webdriver.ChromeOptions()
# 禁止浏览器加载图片,提高运算速度
options.add_argument('blink-settings=imagesEnabled=false')
browser = webdriver.Chrome(options=options)
wait = WebDriverWait(browser, 10)
# 放有全部英雄名称的url
url_hero = 'https://pvp.qq.com/web201605/js/herolist.json'
# 壁纸url
url_image = 'https://pvp.qq.com/web201605/wallpaper.shtml'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:78.0) Gecko/20100101 Firefox/78.0'
}
DIRS = [] # 存放所有文件夹的名称
COUNT = 0 # 已爬取的壁纸个数
HTML = [] # 存放每一页的html源码
1)创建文件夹
这个操作要提前进行,因为筛选完就直接分类下载了,要提前创建好文件夹以供下载保存。
一开始并没有用requests请求,而是用selenium的,但是我发现对于https://pvp.qq.com/web201605/herolist.shtml这个网页用selenium很慢(用浏览器要加载很长时间)。
接着我想到了其他人爬皮肤的时候好像就是这个网页,但他们是找Ajax,于是我也就顺便利用一下他们找到的规律。我用Chrome查看的时候出现一大堆乱码,切换到Firefox就没问题,这个问题还没研究,有人知道的吗?
另外我专门测试了一下selenium和requests两者get网页和json的速度:
import timeit
time_1 = timeit.timeit("options = webdriver.ChromeOptions();"
"options.add_argument('blink-settings=imagesEnabled=false');"
"browser = webdriver.Chrome(options=options);"
"browser.get('https=//pvp.qq.com/web201605/herolist.shtml')",
setup="from selenium import webdriver",
number=1)
time_2 = timeit.timeit("url_hero='https=//pvp.qq.com/web201605/js/herolist.json';"
"headers={'User-Agent'='Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv=78.0) Gecko/20100101 Firefox/78.0'};"
"requests.get(url=url_hero,headers=headers)",
setup="import requests",
number=1)
print(time_1, time_2, sep='\n')
输出结果:
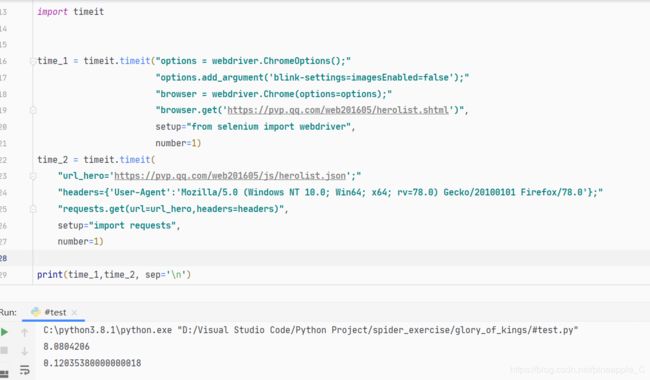 selenium加载这个网页用了8s,而用获取Ajax请求只用了0.12s,所以这里果断用requess请求json
selenium加载这个网页用了8s,而用获取Ajax请求只用了0.12s,所以这里果断用requess请求json
观察json可以发现,英雄名数据都在"cname"属性里,后面就按照这个筛选元素了
def make_dir():
"""
爬取url_hero,根据筛选出的英雄名创建文件夹
:return: 无
"""
if not os.path.exists('image'):
os.mkdir('image')
os.mkdir('image/其它')
html = requests.get(url=url_hero, headers=headers)
heros = html.json()
for hero in heros:
# 根据筛选出的英雄名创建文件夹
dir = hero.get('cname')
if not os.path.exists('image/' + dir):
os.mkdir('image/' + dir)
DIRS.append(dir)
这次我也没有写结合路径的函数,直接在当前工作路径下创建文件夹image,所有的图片都将分类好然后保存到这里。
2)爬取网页源码
网页一共有22页,不光要爬取网页源码,还要要进行翻页的操作,而且加载22页的图片会影响运行速度,可以禁止图片加载来提高运行速度。
禁止加载图片
options = webdriver.ChromeOptions()
# 禁止浏览器加载图片,提高运算速度
options.add_argument('blink-settings=imagesEnabled=false')
browser = webdriver.Chrome(options=options)
关于定位元素我就不多说了,这个实在是比分析Ajax简单多了
def index_page(page):
"""
根据特定条件进行翻页,爬取网页源码
:param page: 页码
:return: 无
"""
try:
if page:
# 等待“下一页”可以被点击
downpage = wait.until(EC.element_to_be_clickable((
By.CLASS_NAME, 'downpage'
)))
# 等待“上一页”可以被点击
uppage=wait.until(EC.element_to_be_clickable((
By.CLASS_NAME,'uppage'
)))
downpage.click()
# 等待壁纸列表加载完毕
wait.until(EC.presence_of_element_located((
By.CSS_SELECTOR, '#Work_List_Container_267733 > div'
)))
HTML.append(browser.page_source)
except TimeoutException as e:
print('Error', e.args)
# 如果此页抛出异常,重新爬取
if page:
uppage.click()
index_page(page)
else:
index_page(page))
还是老套路,根据是否页码是第一页判断要不要翻页,如果超出等待时间则抛出超时异常,重新爬取。
3)筛选并下载
def down_image(html):
"""
下载这一页的壁纸,并根据壁纸名称进行分类
:param html: 这一页的源码
:return: 无
"""
global COUNT # 声明全局变量COUNT
doc = pq(html)
imgs = doc('#Work_List_Container_267733 .p_newhero_item').items()
# 遍历这一页的20张壁纸
for img in imgs:
# 一个标记,记录次壁纸是否被正确下载且分类
down = False
COUNT += 1
print('正在下载第{}张壁纸'.format(COUNT))
name = img('h4 > a').text() # 壁纸名称
# 壁纸链接
skin = img('ul > li.sProdImgDown.sProdImgL6 > a').attr('href')
# 遍历所以文件夹,并且按壁纸名进行分类
for dir in DIRS:
path = 'image/' + dir + '/{}.jpg'.format(name)
# 判断此壁纸是否属于此英雄(文件夹)
if name.count(dir):
with open(path, 'wb')as file:
file.write(requests.get(url=skin, headers=headers).content)
down = True # 记录壁纸已经下载
break
# 如果壁纸没有被分类下载,那么下载到“其他”目录下
if not down:
with open('image/其它' + '/{}.jpg'.format(name), 'wb')as file:
file.write(requests.get(url=skin, headers=headers).content)
分类的过程甚是艰辛,有的壁纸是用“-”分开英雄名和皮肤名的,有的则是用“.”。真的烦啊,甚至有一些是合影根本就不是皮肤也不是英雄,害的我去另一个网址专门爬英雄名,专门又创建了一个“其他”的目录来存放这些合影之类的壁纸
4)线程池
算了一下一共438个图片,这意味着要请求438次,每一次请求都需要消耗时间。使用多线程,以一页为一个线程,可以同时请求+下载22次,大大的缩短了运行时间。
def threadings():
"""
创建一个线程池,一个22个线程,每一个线程负责下载一页
:return: 无
"""
thread_list = []
for i in HTML:
t = threading.Thread(target=down_image, args=(i,))
thread_list.append(t)
for t in thread_list:
t.start()
for t in thread_list:
t.join()
三、完整代码
基于PyCarm、python3.8.1、selenium3.141.0、pyquery1.4.1
# -*- coding: utf-8 -*-
"""
@author:Pineapple
@contact:[email protected]
@time:2020/7/23 8:40
@file:glory_of_kings_2.py
@desc:Use selenium and pyquery to quickly crawl the king of glory wallpaper
"""
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
from pyquery.pyquery import PyQuery as pq
from selenium import webdriver
from time import perf_counter
import threading
import requests
import os
# 计时开始
start = perf_counter()
options = webdriver.ChromeOptions()
# 禁止浏览器加载图片,提高运算速度
options.add_argument('blink-settings=imagesEnabled=false')
browser = webdriver.Chrome(options=options)
wait = WebDriverWait(browser, 10)
# 放有全部英雄名称的url
url_hero = 'https://pvp.qq.com/web201605/js/herolist.json'
# 壁纸url
url_image = 'https://pvp.qq.com/web201605/wallpaper.shtml'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:78.0) Gecko/20100101 Firefox/78.0'
}
DIRS = [] # 存放所有文件夹的名称
COUNT = 0 # 已爬取的壁纸个数
HTML = [] # 存放每一页的html源码
def make_dir():
"""
爬取url_hero,根据筛选出的英雄名创建文件夹
:return: 无
"""
if not os.path.exists('image'):
os.mkdir('image')
os.mkdir('image/其它')
html = requests.get(url=url_hero, headers=headers)
heros = html.json()
for hero in heros:
# 根据筛选出的英雄名创建文件夹
dir = hero.get('cname')
if not os.path.exists('image/' + dir):
os.mkdir('image/' + dir)
DIRS.append(dir)
def index_page(page):
"""
根据特定条件进行翻页,爬取网页源码
:param page: 页码
:return: 无
"""
try:
if page:
# 等待“下一页”可以被点击
downpage = wait.until(EC.element_to_be_clickable((
By.CLASS_NAME, 'downpage'
)))
# 等待“上一页”可以被点击
uppage=wait.until(EC.element_to_be_clickable((
By.CLASS_NAME,'uppage'
)))
downpage.click()
# 等待壁纸列表加载完毕
wait.until(EC.presence_of_element_located((
By.CSS_SELECTOR, '#Work_List_Container_267733 > div'
)))
HTML.append(browser.page_source)
except TimeoutException as e:
print('Error', e.args)
# 如果此页抛出异常,重新爬取
if page:
uppage.click()
index_page(page)
else:
index_page(page))
def down_image(html):
"""
下载这一页的壁纸,并根据壁纸名称进行分类
:param html: 这一页的源码
:return: 无
"""
global COUNT # 声明全局变量COUNT
doc = pq(html)
imgs = doc('#Work_List_Container_267733 .p_newhero_item').items()
# 遍历这一页的20张壁纸
for img in imgs:
# 一个标记,记录次壁纸是否被正确下载且分类
down = False
COUNT += 1
print('正在下载第{}张壁纸'.format(COUNT))
name = img('h4 > a').text() # 壁纸名称
# 壁纸链接
skin = img('ul > li.sProdImgDown.sProdImgL6 > a').attr('href')
# 遍历所以文件夹,并且按壁纸名进行分类
for dir in DIRS:
path = 'image/' + dir + '/{}.jpg'.format(name)
# 判断此壁纸是否属于此英雄(文件夹)
if name.count(dir):
with open(path, 'wb')as file:
file.write(requests.get(url=skin, headers=headers).content)
down = True # 记录壁纸已经下载
break
# 如果壁纸没有被分类下载,那么下载到“其他”目录下
if not down:
with open('image/其它' + '/{}.jpg'.format(name), 'wb')as file:
file.write(requests.get(url=skin, headers=headers).content)
def threadings():
"""
创建一个线程池,一个22个线程,每一个线程负责下载一页
:return: 无
"""
thread_list = []
for i in HTML:
t = threading.Thread(target=down_image, args=(i,))
thread_list.append(t)
for t in thread_list:
t.start()
for t in thread_list:
t.join()
def main():
"""
函数入口,完成计时操作
:return: 无
"""
make_dir()
browser.get(url_image)
for i in range(22):
index_page(i)
threadings()
# 计时结束
print('全部下载完成,共用时{}s'.format(perf_counter() - start))
browser.close()
if __name__ == '__main__':
main()
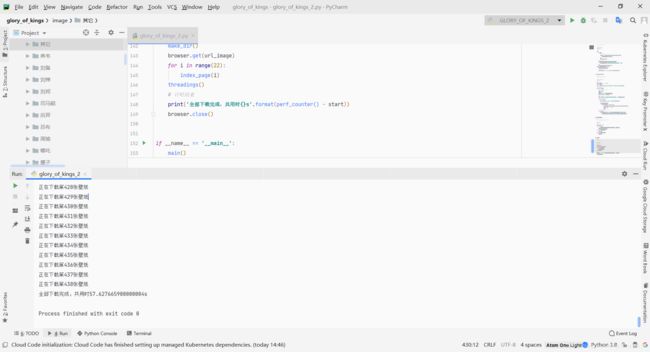
附上这个赛季的主题:
四、结语
只是看书学习的话,一天确实可以学不少,可是实际动起手来,光是这一个小项目就花了我一天半的时间,理论和实践真的是有很大差距的。虽然过程中遇到了很多问题,但是我都一一克服,还顺便把多线程复习了一下,对项目的总体框架又加深了理解。有了这次经验,相信以后再做类似的项目可以写的更快,更好!
如有错误,欢迎私信纠正
技术永无止境,谢谢支持