电商数据分析-SQL
1. 项目背景:
通过对现有用户购物行为的数据进行分析,深度探索用户的消费行为、消费规律、消费偏好,针对不同的用户群体,以便更精细化运营,取得更好的业务;
2. 数据来源
数据来源:https://tianchi.aliyun.com/dataset/dataDetail?dataId=649&userId=1
注:如果数据太大,可以通过系统抽样选取部分数据
UserBehavior是阿里巴巴提供的一个淘宝用户行为数据集,本数据集(UserBehavior.csv)包含了2017年11月25日至2017年12月3日之间,有行为的约一百万随机用户的所有行为(行为包括点击、购买、加购、喜欢),数据集的每一行表示一条用户行为,由用户ID、商品ID、商品类目ID、行为类型和时间戳组成,并以逗号分隔。
3. 从不同维度分析
第一个维度:用户购物情况整体分析
以PV、UV、平均访问量、跳失率等指标,分析用户最活跃的日期及活跃时段,了解用户行为习惯
第二个维度:商品购买情况分析
从成交量、人均购买次数、复购率等指标,探索用户对商品的购买偏好,了解商品的销售规律
第三个维度:用户行为转化漏斗分析
从收藏转化率、购物车转化率、成交转化率,对用户行为从浏览到购买进行漏斗分析
第四个维度:参照RFM模型,对用户进行分类,找出有价值的用户
4. 数据分析
分析步骤如下:
提出问题------理解数据------数据清洗------构建模型------数据可视化
一、 提出问题
用户最活跃的日期及时段
用户对商品有哪些购买偏好
用户行为间的转化情况
用户分类,哪些是有价值的用户
二、 理解数据
| user_id | item_id | item_cat | beh_type | time_stamp |
|---|---|---|---|---|
| 用户ID | 商品ID | 商品类目ID | 行为类型 | 时间戳 |
注意,用户行为有4种:
| pv | fav | cart | buy |
|---|---|---|---|
| 点击浏览 | 收藏商品 | 添加购物车 | 购买 |
三、 数据清洗
-
1 数据导入:在运行窗口中输入
net start mysql启动SQL,再打开本地客户端SQLyog,从本地导入csv文件,注意先打开数据,大概扫下数据,并确认数据源中是否有标题行;

-
2 查看缺失值:通过计数查看全部列是否有缺失值
SELECT COUNT(user_id),COUNT(item_id),COUNT(item_cat),COUNT(beh_type),COUNT(time_stamp) FROM ut;
![]()
每一列的计算结果返回一样,说明没有缺失值;
注:如果有缺失值,一般处理方法有删除、通过fillna()函数实现NULL值填充、均值填充
ALTER TABLE ut ADD COLUMN dates DATE NOT NULL;
ALTER TABLE ut ADD COLUMN times VARCHAR(10) NOT NULL;
ALTER TABLE ut ADD COLUMN hours VARCHAR(10);
ALTER TABLE ut ADD COLUMN hours VARCHAR(10);
SET sql_safe_updates=0;
UPDATE ut SET date_time=FROM_UNIXTIME(time_stamp); #from_unixtime()函数可以把时间戳转变成日期格式
UPDATE ut SET dates=LEFT(date_time,10);
UPDATE ut SET times=SUBSTRING(date_time,12,5); #从12位开始,截取5个字符
UPDATE ut SET hours=LEFT(times,2);
UPDATE ut SET hours=LEFT(times,2);
- 3 查看异常值
SELECT * FROM ut WHERE dates NOT BETWEEN '2017-11-25' AND '2017-12-03';
- 4 删除异常值,有些日期是研究日期之外的数据
DELETE FROM ut WHERE dates NOT BETWEEN '2017-11-25' AND '2017-12-03';
- 5 查看异常值-behavior
SELECT beh_type FROM ut WHERE beh_type NOT IN ('pv','buy','cart','fav'); #返回空,说明没有异常值
5. 创建模型
一、 用户购物整体情况分析
- 1. 查看pv(访问量)是939535
SELECT COUNT(beh_type) AS 浏览量 FROM `ut` WHERE beh_type = 'pv';
- 2 查看访问用户总数是10202
SELECT COUNT(DISTINCT user_id) AS 用户数 FROM `ut`;
- 3. 平均访问量是 939535/10202=92.1,即每个用户平均访问了92个页面
SELECT (939535/10202);
- 4. 跳失率:只有点击行为的用户/总用户数
根据user_id分组,计算消费行为的种类之和,正常的用户行为进行时,pv点击浏览是第一个动作,之后是其他三个动作,所以这里我们只需要选择消费行为种类之和是1的,就是pv类型;
CREATE OR REPLACE VIEW v2
AS
SELECT user_id,COUNT(DISTINCT beh_type) 消费行为总类 FROM `ut` GROUP BY user_id HAVING 消费行为总类=1; #创建视图
SELECT COUNT(*) FROM v2;
结果返回595个用户,跳失率为 593/10202=0.0581,这个跳失率不算高,没有出现异常;
- 5. 每天访问量/访客情况
SELECT dates,COUNT(beh_type) AS 访问量 FROM ut
WHERE beh_type='pv'
GROUP BY dates;

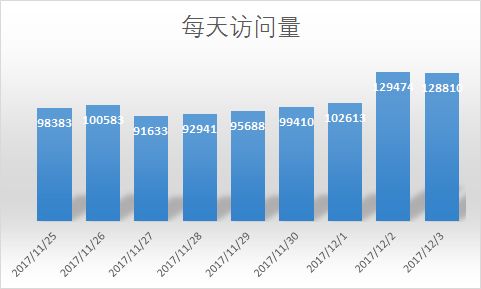
- 6. 每天访客人数情况
SELECT dates,COUNT(DISTINCT user_id) AS 访客数 FROM ut
GROUP BY dates;
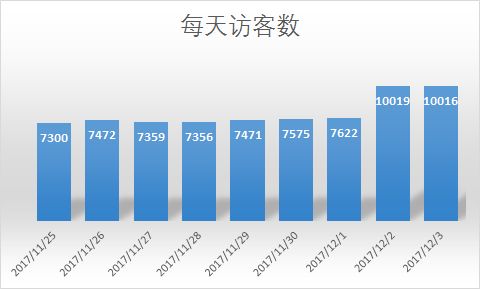
2017-12-02数据激增,是否和周末有关,如果是,那为什么之前的周末没有增加,所以无关;
- 7. 每个时间段访客人数情况
SELECT hours,COUNT(DISTINCT user_id) AS 访客数 FROM USER GROUP BY hours ORDER BY 访客数 DESC;
SELECT hours,COUNT(beh_type) AS 访问量 FROM USER WHERE beh_type='pv' GROUP BY hours ORDER BY 访问量 DESC;
可以将两个查询结果的表格合并,注意如果两个数据集行数不同,需要用外连接,或者查看缺失值,这里都是返回24行,所以可以用内连接
SELECT a.hours,a.访客数,b.访问量
FROM
(SELECT hours,COUNT(DISTINCT user_id) AS 访客数 FROM USER GROUP BY hours) a
JOIN
(SELECT hours,COUNT(beh_type) AS 访问量 FROM USER WHERE beh_type='pv' GROUP BY hours) b
ON a.hours=b.hours ORDER BY hours;
从下面图形可以看到访问量远高于访客数,这是正常现象,比如一个访客会产生很多访问量;
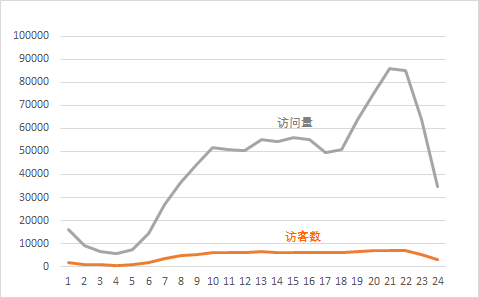
为了看清楚访问量和访客数的走势,我们添加双坐标轴;

可以看出访客量和访问量大概趋势走向一致,根据排序结果来看,晚上1-6睡眠时间,访问量很低,7-8点开始回升,直到上午10点开始趋缓,可能是在上班,一直持续到18点,因为开始陆续下班,到了晚上19点开始再次攀升,21-22产生一个新高,再往回数据开始回落,应该是开始准备休息了;
然后我们来分析是否成交量也符合上述规律呢?
SELECT hours, COUNT(beh_type) AS 成交量 FROM USER
WHERE beh_type='buy'
GROUP BY hours
ORDER BY 成交量 DESC;

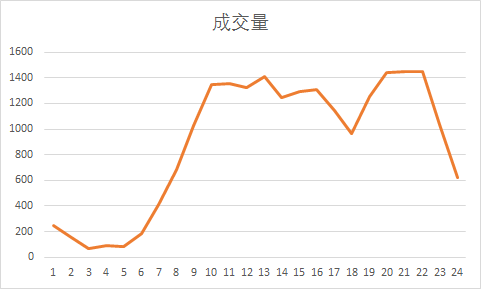
可以看出成交量和上面访客趋势类似,在访客最高的21-22时成交量达到峰值;
二、 商品购买情况分析
- 1. 日成交量:查看每天成交数量
SELECT dates,COUNT(beh_type) AS 成交量 FROM USER
WHERE beh_type='buy'
GROUP BY dates;
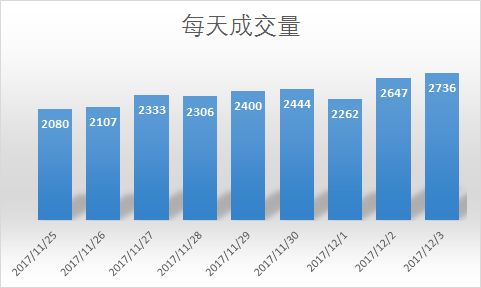
这个趋势和购物分析中的访客量趋势近似;
- 2. 人均购买次数:总订单数 / 总人数
SELECT COUNT(beh_type)/COUNT(DISTINCT user_id) AS 人均购买次数 FROM USER WHERE beh_type='buy';
结果是3.0,说明每位用户平均购买3次商品
- 3. 复购率:复购率 = 购买2次及以上用户数/总购买用户数
购买的总人数有7000人:
SELECT COUNT(DISTINCT user_id) FROM USER WHERE beh_type='buy';
购买2次以上的用户有4639人:
CREATE OR REPLACE VIEW v3
AS
SELECT DISTINCT user_id FROM USER WHERE beh_type='buy' GROUP BY user_id HAVING COUNT(beh_type)>1;
SELECT COUNT(*) FROM v3;
复购率为:4639/7000=66%,短短9天之内复购率66%算很高了,说明很多回头客,有可能店铺在做临时促销;
这么高的复购率,那排行前十的有哪些呢?
SELECT DISTINCT user_id,COUNT(user_id) 购买次数 FROM USER WHERE beh_type='buy'
GROUP BY user_id ORDER BY 购买次数 DESC LIMIT 10;
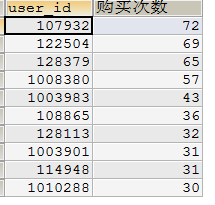
购买次数最高的用户购买了72次,且在9天之内,说明店铺商品还是很不错的,如果有用户的相关信息,可以更进一步的分析性别,区域,商品偏好等等,因为数据有限,此处不展开讨论;
那这么高的复购率,用户都在抢购些什么东西呢?
SELECT item_id,COUNT(beh_type) 成交量 FROM USER
WHERE beh_type='buy'
GROUP BY item_id
ORDER BY 销量 DESC
LIMIT 10;

这是成交量前十的商品,第一的商品卖出了17件,销量最高的商品往往利润不是最大的,有可能是商店为了引流而打造的‘爆款’,用于引流,甚至有商品对应的毛利表,也可能更深入的印证这一理论,因为数据有限,所以在此不做展开深入讨论;
三、用户行为转化漏斗分析
先通过分组筛选出每个四种不同消费行为的计数;


通过上面的步骤可以看到,浏览量很大,说明商品页面还可以,而从浏览到最终购买的转化率只有2%,有很大的流失率,下面我们一步步的分析转化过程和概率;
第一条线路:浏览—加入购物车—购买
第二条线路:浏览—添加收藏—购买
先计算出浏览的总人数有10169
SELECT COUNT(DISTINCT user_id) FROM USER WHERE beh_type='pv';
然后计算加购物车人数,以及之后购买的人数:
SELECT COUNT(DISTINCT a.user_id) 加购物车人数,COUNT(DISTINCT b.user_id) 之后购买人数 FROM
(SELECT user_id,item_id,item_cat,time_stamp FROM USER WHERE beh_type='cart') a
LEFT JOIN
(SELECT user_id,item_id,item_cat,time_stamp FROM USER WHERE beh_type='buy') b
ON a.user_id=b.user_id AND a.item_id=b.item_id AND a.item_cat=b.item_cat AND a.time_stamp < b.time_stamp;
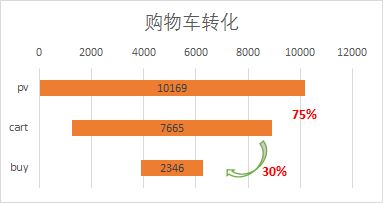
结果可知有7665加入购物车用户,有2346加入后购买,从浏览到加购物车,转化率7665/10169=75%,从加购车到购买,转化率2346/7665=30%
浏览-收藏-购买,和上述的行为类似;
SELECT COUNT(DISTINCT a.user_id) 收藏人数,COUNT(DISTINCT b.user_id) 之后购买人数 FROM
(SELECT user_id,item_id,item_cat,time_stamp FROM USER WHERE beh_type='fav') a
LEFT JOIN
(SELECT user_id,item_id,item_cat,time_stamp FROM USER WHERE beh_type='buy') b
ON a.user_id=b.user_id AND a.item_id=b.item_id AND a.item_cat=b.item_cat AND a.time_stamp < b.time_stamp;

结果可知收藏人数4070,购买人数884,总人数10169,从浏览到加收藏,转化率4070/10169=40%,从加收藏到购买,转化率884/4070=21%
下篇:电商数据分析-Pandas