Python-人物词频统计-jieba库-三国演义
jieba库的函数只有一个,lcut()
首先下载三国演义 TXT文件,utf-8格式
进行分词
import jieba
def get_text():
f = open('三国演义.txt','r',encoding='utf-8').read()
words = jieba.lcut(f)
return words
对于标点符号先不管它
思路:对于读出的列表,进行遍历,如果长度为1,说明是符号,略去,对于其他,进行词频统计,利用字典
import jieba
def get_text():
f = open('三国演义.txt','r',encoding='utf-8').read()
words = jieba.lcut(f)
return words
words = get_text()
counts = {}
for i in words:
if len(i)==1:
continue
else:
counts[i] = counts.get(i,0)+1
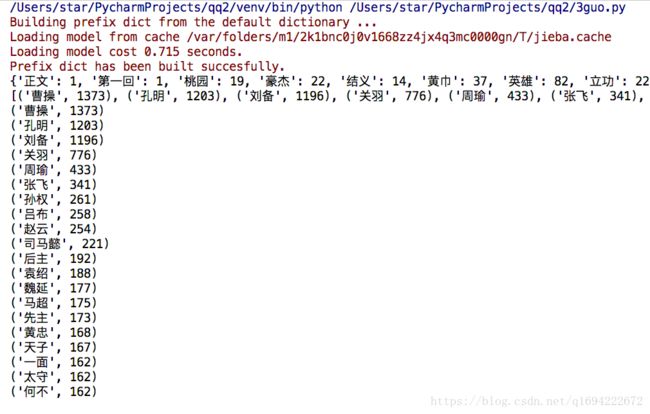
print(counts)
ls = list(counts.items())
ls.sort(key= lambda x:x[1],reverse=True)
print(ls)
for i in ls[:20]:
print(i)

发现像将军却说,二人不可,这样的词不是人物,还有玄德关公这样的不是大名,还有孔明和孔明曰被认为是两个词,这些都需要进行处理,可以在遍历列表的时候进行处理,如果不是人名则略去,如果是同一个人则合并
import jieba
def get_text():
f = open('三国演义.txt','r',encoding='utf-8').read()
words = jieba.lcut(f)
return words
words = get_text()
counts = {}
includes = ['将军','却说','二人','不可','荆州','如此','不能',
'商议','如何','主公','军士','左右','军马','引兵',
'次日','大喜','天下','于是','东吴','今日','不敢',
'魏兵','人马','不知','汉中','陛下','一人','众将',
'只见','蜀兵','大叫','上马','此人','后人','城中']
for i in words:
if len(i)==1 or i in includes:
continue
elif i in ['丞相']:
counts['曹操'] = counts.get('曹操', 0) + 1
elif i in ['孔明曰']:
counts['孔明'] = counts.get('孔明', 0) + 1
elif i in ['玄德曰','玄德']:
counts['刘备'] = counts.get('刘备', 0) + 1
elif i in ['关公','云长']:
counts['关羽'] = counts.get('关羽', 0) + 1
elif i in ['都督']:
counts['周瑜'] = counts.get('周瑜', 0) + 1
else:
counts[i] = counts.get(i,0)+1
print(counts)
ls = list(counts.items())
ls.sort(key= lambda x:x[1],reverse=True)
print(ls)
for i in ls[:20]:
print(i)