scrapy框架开发爬虫实战——采集BOSS直聘信息【爬虫进阶】
项目GitHub
https://github.com/liuhf-jlu/scrapy-BOSS-
爬取任务
时间:2019年8月28日
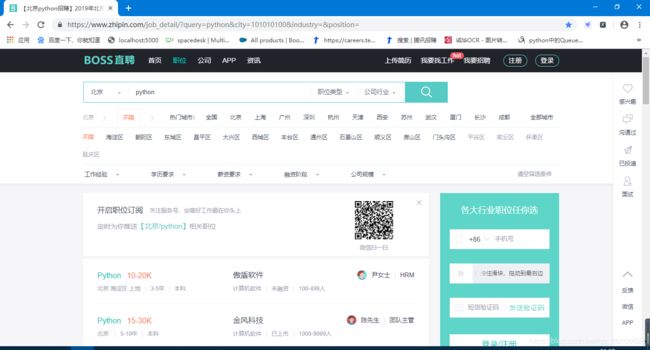
爬取内容:BOSS直聘上的北京市python岗位的招聘信息
链接:https://www.zhipin.com
创建项目
#创建项目
scrapy startproject BJ
创建爬虫
#进入项目目录下
cd BJ
#创建爬虫 scrapy genspider [爬虫名称][爬取范围]
scrapy genspider boss_zhipin 'zhipin.com'
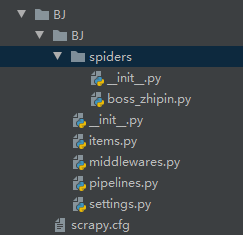
scrapy.cfg 项目配置文件
items.py 数据存储模板,用于结构化数据
pipelines.py 数据处理
settings.py 配置文件
middlewares.py 定义项目中间件
spiders 爬虫目录
明确爬虫需求,设计爬虫代码
1、定义入口URL,start_urls
起始页
https://www.zhipin.com/job_detail/?query=python&city=101010100&industry=&position=
第一页
https://www.zhipin.com/c101010100/?query=python&page=1&ka=page-1
第二页
https://www.zhipin.com/c101010100/?query=python&page=2&ka=page-2
第三页
https://www.zhipin.com/c101010100/?query=python&page=3&ka=page-3
下一页按钮的链接
https://www.zhipin.com/c101010100/?query=python&page={}&ka=page-next
通过上面可以发现url的变化规律即翻页规律,定义爬虫的start_urls=第一页的链接。
start_urls = ['https://www.zhipin.com/c101010100/?query=python&page=1&ka=page-1']
2、items定义我们要爬取的字段(以后还可以扩充)
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class BjItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
job_title = scrapy.Field() # 岗位
compensation = scrapy.Field() # 薪资
company = scrapy.Field() # 公司
address = scrapy.Field() # 地址
seniority = scrapy.Field() # 工作年薪
education = scrapy.Field() # 教育程度
company_type = scrapy.Field() # 公司类型
company_finance = scrapy.Field() # 融资
company_quorum = scrapy.Field() # 公司人数
3、编写spider
# -*- coding: utf-8 -*-
import scrapy
from BJ.items import BjItem
class BossZhipinSpider(scrapy.Spider):
name = 'boss_zhipin'
allowed_domains = ['zhipin.com']
start_urls = ['https://www.zhipin.com/c101010100/?query=python&page=1&ka=page-1']
def parse(self, response):
item =BjItem()
# 获取页面数据的条数
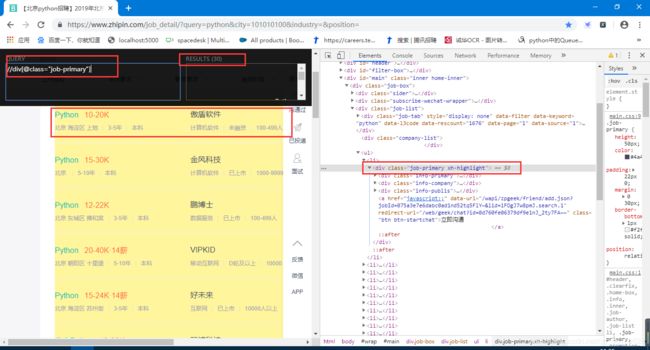
nodeList = response.xpath('//div[@class="job-primary"]')
for node in nodeList:
item["job_title"]=node.xpath('.//div[@class="job-title"]/text()').extract()[0]
item["compensation"]=node.xpath('.//span[@class="red"]/text()').extract()[0]
item["company"]=node.xpath('.//div[@class="info-company"]//h3//a/text()').extract()[0]
company_info=node.xpath('.//div[@class="info-company"]//p/text()')
temp=node.xpath('.//div[@class="info-primary"]//p/text()')
item["address"] = temp[0]
item["seniority"] = temp[1]
item["education"] = temp[2]
if len(company_info) < 3:
item["company_type"] = company_info[0]
item["company_finance"] = ""
item["company_quorum"] = company_info[-1]
else:
item["company_type"] = company_info[0]
item["company_finance"] = company_info[1]
item["company_quorum"] = company_info[2]
yield item
如果这样写是爬取不到数据的,会产生以下几个错误:
1、settings.py 中设置了 ROBOTSTXT_OBEY = True(遵守robots.txt规则),不会爬取数据。
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
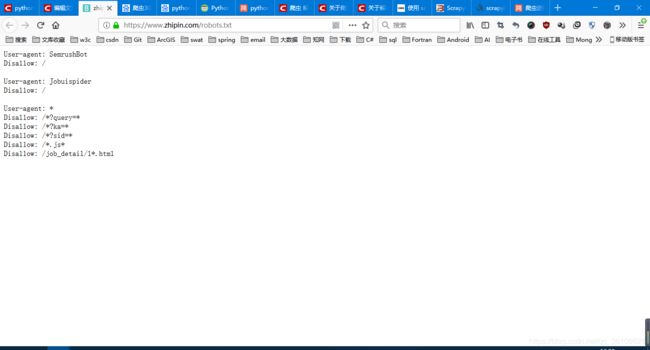
应修改为
# Obey robots.txt rules
ROBOTSTXT_OBEY = False2、如果没有添加cookie信息,会产生redirect(403)错误。
2019-08-28 16:23:11 [scrapy.core.engine] INFO: Spider opened
2019-08-28 16:23:11 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2019-08-28 16:23:11 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2019-08-28 16:23:12 [scrapy.core.engine] DEBUG: Crawled (403) (referer: None)
2019-08-28 16:23:12 [scrapy.spidermiddlewares.httperror] INFO: Ignoring response <403 https://www.zhipin.com/job_detail/?query=%E6%9C%BA%E5%99%A8%E
5%AD%A6%E4%B9%A0&city=101010100&industry=&position=>: HTTP status code is not handled or not allowed
2019-08-28 16:23:12 [scrapy.core.engine] INFO: Closing spider (finished)

参考文章:
》》》python scrapy爬虫 CrawlSpider 拉钩招聘网302重定向问题解决方案 , 修改setting信息,添加cookie请求
https://blog.csdn.net/lanhaixuanvv/article/details/78244172
4、添加Headers和cookie,修改settings
在浏览器中找到cookie信息

cookie_list="lastCity=101010100; _uab_collina=156690786993771845122604; __zp_stoken__=91d9sehzkp8EbGAr%2FhorhnBlKDxF48iLYCkIFKXQWc%2BBsP9gUqC13U399dM5YAVVefystK0H6%2BtLx651FN%2BybujeYw%3D%3D; __c=1566962162; __g=-; __l=l=%2Fwww.zhipin.com%2Fjob_detail%2F%3Fquery%3Dpython%26city%3D101010100%26industry%3D%26position%3D&r=; Hm_lvt_194df3105ad7148dcf2b98a91b5e727a=1566907870,1566962162; __a=85199832.1566370536.1566907870.1566962162.21.3.14.21; Hm_lpvt_194df3105ad7148dcf2b98a91b5e727a=1566973807"
custom_settings = {
"COOKIES_ENABLED": False,
"DOWNLOAD_DELAY": 1,
'DEFAULT_REQUEST_HEADERS': {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Connection': 'keep-alive',
'Cookie': cookie_list,
'Host': 'www.zhipin.com',
'Origin': 'https://www.zhipin.com',
'Referer': 'https://www.zhipin.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36',
}
}修改settings.py
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
5、获取分页数据

next_page=response.xpath('//div[@class="page"]//a[@class="next"]/@href').extract()[-1]
if next_page != "javascript:;":
base_url="https://www.zhipin.com"
url=base_url+next_page
yield Request(url=url,callbask=self.parse)完整的爬虫代码 boss_zhipin.py
# -*- coding: utf-8 -*-
import scrapy
from scrapy import Request
from BJ.items import BjItem
import time
class BossZhipinSpider(scrapy.Spider):
name = 'boss_zhipin' # 运行时爬虫的名称
allowed_domains = ['zhipin.com'] # 当 OffsiteMiddleware 启用时, 域名不在列表中的URL不会被跟进。
start_urls = ['https://www.zhipin.com/c101010100/?query=python&page=1&ka=page-1'] # 起始url
cookie_list="lastCity=101010100; _uab_collina=156690786993771845122604; __zp_stoken__=91d9sehzkp8EbGAr%2FhorhnBlKDxF48iLYCkIFKXQWc%2BBsP9gUqC13U399dM5YAVVefystK0H6%2BtLx651FN%2BybujeYw%3D%3D; __c=1566962162; __g=-; __l=l=%2Fwww.zhipin.com%2Fjob_detail%2F%3Fquery%3Dpython%26city%3D101010100%26industry%3D%26position%3D&r=; Hm_lvt_194df3105ad7148dcf2b98a91b5e727a=1566907870,1566962162; __a=85199832.1566370536.1566907870.1566962162.21.3.14.21; Hm_lpvt_194df3105ad7148dcf2b98a91b5e727a=1566973807"
custom_settings = {
"COOKIES_ENABLED": False,
"DOWNLOAD_DELAY": 1,
'DEFAULT_REQUEST_HEADERS': {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Connection': 'keep-alive',
'Cookie': cookie_list,
'Host': 'www.zhipin.com',
'Origin': 'https://www.zhipin.com',
'Referer': 'https://www.zhipin.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36',
}
}
def parse(self, response):
item =BjItem()
# 获取页面数据的条数
nodeList = response.xpath('//div[@class="job-primary"]')
for node in nodeList:
item["job_title"]=node.xpath('.//div[@class="job-title"]/text()').extract()[0]
item["compensation"]=node.xpath('.//span[@class="red"]/text()').extract()[0]
item["company"]=node.xpath('.//div[@class="info-company"]//h3//a/text()').extract()[0]
company_info=node.xpath('.//div[@class="info-company"]//p/text()').extract()
temp=node.xpath('.//div[@class="info-primary"]//p/text()').extract()
item["address"] = temp[0]
item["seniority"] = temp[1]
item["education"] = temp[2]
if len(company_info) < 3:
item["company_type"] = company_info[0]
item["company_finance"] = ""
item["company_quorum"] = company_info[-1]
else:
item["company_type"] = company_info[0]
item["company_finance"] = company_info[1]
item["company_quorum"] = company_info[2]
yield item
next_page=response.xpath('//div[@class="page"]//a[@class="next"]/@href').extract()[-1]
if next_page != "javascript:;":
base_url="https://www.zhipin.com"
url=base_url+next_page
time.sleep(5) # 设置爬取延迟
yield Request(url=url,callback=self.parse)6、编辑pipeline.py 将数据存为json格式的数据,将数据存入到MongoDB数据库
一般化步骤,直接上代码
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
import json
import time
import pymongo
from scrapy import Item
class BjPipeline(object):
def process_item(self, item, spider):
return item
class ImportToJson(object):
# 创建json文件
def __init__(self):
# 构建json文件的名称,bosszhipin_日期.json
jsonName = 'bosszhipin_' + str(time.strftime("%Y%m%d", time.localtime())) + '.json'
self.f = open(jsonName, 'w')
# 打开爬虫时执行的动作
def open_spider(self, spider):
pass
# 主管道
def process_item(self, item, spider):
content = json.dumps(dict(item), ensure_ascii=False) + ",\n"
self.f.write(content)
return item
# 爬虫关闭时执行的动作
def close_spider(self, spider):
self.f.close()
class ImportToMongo(object):
# 读取MongoDB中的MONGO_DB_URI
# 读取MongoDB中的MONGO_DB_NAME
@classmethod
def from_crawler(cls,crawler):
cls.DB_URI=crawler.settings.get('MONGO_DB_URI')
cls.DB_NAME=crawler.settings.get('MONGO_DB_NAME')
return cls()
def __init__(self):
pass
def open_spider(self,spider):
self.client=pymongo.MongoClient(self.DB_URI)
self.db=self.client[self.DB_NAME]
def process_item(self,item,spider):
db_name=spider.name+'_'+str(time.strftime("%Y%m%d",time.localtime()))
collection=self.db[db_name]
post=dict(item) if isinstance(item,Item) else item
collection.insert_one(post)
return item
def close_spider(self,spider):
self.client.close()
添加完pipeline之后,一定要在settings.py中设置,
# MongoDB
# Mongo_DB_URI
# Mongo_DB_NAME
MONGO_DB_URI = 'mongodb://localhost:27017/'
MONGO_DB_NAME = 'bosszhipin'
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'BJ.pipelines.BjPipeline': 300,
'BJ.pipelines.ImportToJson': 310,
'BJ.pipelines.ImportToMongo': 320,
}
7、运行爬虫
scrapy crawl boss_zhipinjson格式数据

MongoDB

8、托管代码到GitHUb